Quantrium Guides
7/8, 2020 – 7 min read

Tesseractは、様々なOSで使用できる光学文字認識エンジンである。 これは、Apache ライセンスの下でリリースされたフリーソフトウェアです。 Tesseractは、1980年代にHewlett-Packard社によってプロプライエタリなソフトウェアとして開発され、その後2005年にオープンソースソフトウェアとして公開されました。 その後、2006年からはGoogleが開発スポンサーとなっている。 このガイドでは、私のWindows 10マシンにTesseractをインストールするための手順をご紹介します。 1196>
Windows システムに Tesseract 4 をインストールするには、次のリンクにアクセスします:
Tesseract-ocr-w64-setup-v4.1.0.20190314.exe というハイパーリンクをクリックして、Windows 実行ファイルをダウンロードします。 Tesseract-ocr-w64-setup-v4.1.0.20190314.exe」というexeファイルを保存するよう求める通知が表示されます。 この.exeファイルを十分な記憶容量がある場所に保存します。
このexeファイルを開きます。 このソフトウェアによるシステムの変更を許可しますか」と表示されたら、「はい」をクリックします。
次へをクリックし、「I agree to the terms and conditions」をクリックし、Tesseract を誰にインストールするか(このコンピュータを使う人、自分だけ、どちらでも可)を選択後、次へをクリックします。
ScrollView、トレーニングツール、ショートカット作成、言語データというボックスにチェックをしてください。 これらはデフォルトでチェックされているはずですが、あなたのシステムでチェックされていない場合に備えて、チェックをしてください。
さて、日本語、中国語、クルド語などの外国語や、ヒンディー語、タミル語、ベンガル語などのインド言語で予測したい場合は、「追加の文字データ」と「追加の言語データ」にもチェックをしてください。 英語のみで予測を行いたい場合は、このオプションにチェックを入れる必要はありません。 Tesseractをインストールするディレクトリを選択します。 デフォルトではC:\Program Files\Tesseract-OCRと表示されるので、そこにインストールしました。 お好みでインストールしてください。 ただし、Tesseractをインストールしたパスをメモしておいてください。 これは重要です。
次に、プログラムのショートカットを作成するスタートメニューのフォルダを選択できます。 私は、「Tesseract-OCR」というフォルダーに作成しました。 新しいフォルダーに作成したい場合は、”Select the Start Menu folder where you would like …” の右下の空欄にフォルダー名を入力するだけです。
また、ショートカットを作成しない場合は、左下の “Do not create shortcuts” ボックスにチェックを入れることができます。 お好みのオプションを選択し終えたら、インストールをクリックします。 インストールには数分かかります。
インストールが終了したら、Tesseract をインストールしたディレクトリに移動します。 Windows のコマンドラインから Tesseract を使用するために、システムの環境変数で Tesseract をパスに追加する必要があります。 すると、「システム環境変数の編集」という結果が表示されます。 それをクリックします。 これをクリックすると、「システムのプロパティ」の「詳細設定」になり、右下に「環境変数…」というボタンが表示されるはずです。 そのボタンをクリックします。
さて、ここに2つのテーブルが表示されているはずです。 ひとつはという名前です。 ここで、<username>は、現在PCを使用しているユーザー名を表す変数です。 もう1つは「システム変数」というテーブルです。 システム変数」テーブルの中の「パス」という変数をクリックして、下のスクリーンショットに示すように、「OK」ボタンのすぐ上の「編集」というボタンをクリックします。
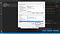
これが終わると、「環境変数の編集」というページが表示されるようになります。 ここで、右上に「新規作成」というボタンがあります。 その「新規作成」ボタンをクリックします。 空白のスペースができるので、そこにテキストを追加してください。
ディレクトリ名を入力したら、「Enter」キーを押して、「環境変数の編集テーブル」にディレクトリ名が追加されたかどうかを確認します。 追加されたら、”OK “をクリックします。 環境変数」ページで再度「OK」をクリックします。 システムのプロパティ」ページで再度「OK」をクリックします。 これですべての設定オプションが終了したはずです。
コマンドプロンプトを開き、tesseract --versionと入力してEnterキーを押します。
Output for tesseract – version command after tesseract was successfully installed
tesseract command not found などのエラーが表示されたら、おそらくこのガイドに従っている間に何らかの間違いがあるのでしょう。 どこを間違えたのか、もう一度確認し、修正してみてください。 または、もう一度すべてのプロセスを繰り返すこともできます。
Great! これで、あなたのマシンにTesseractがインストールされました。 1196>
How to use Tesseract 4 using Command Line on a Windows Machine
First, make sure you have some handwritten document or some typed document in the form of an image.Tesseract は、手書きの文書または画像の形で入力された文書です。 例えば、デスクトップにhandwritten_photo_1というpng形式の写真があり、それを使ってTesseractをテストしてみたいとします。 コマンドプロンプトを開いてください。
C:\Users\username>
ここで username はそのシステムでのあなたのユーザー名です。 デスクトップディレクトリに移動する必要があります。
C:\Users\username> cd Desktop
これでDesktopディレクトリに移動し、そこに私の画像があります。 Tesseractがドキュメント内のテキストをどのように予測するかは、以下のコマンドで確認できます:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseractはコマンドライン自体にテキストを直接出力します。 -lパラメータは言語の指定に使用されます。 ここでは、デフォルトの言語である英語を指定しているため、-l engを使用することは冗長になっています。 OCR に他の言語を使用したい場合は、言語を指定するすべての .traineddata ファイルが含まれているこのリンクを確認してください:
たとえば、ヒンディー語で書かれたテキスト ドキュメントがあるとします。 次に、この上記のリンクに移動し、hin.traineddataというタイトルのファイルをクリックし、それをダウンロードしてください。 ダウンロードが完了したら、tesseractをインストールしたディレクトリの中にある「tessdata」フォルダに移動します。 それができたら、次のコマンドを使用してヒンディー語のドキュメントの OCR を実行できます:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
OCR 出力をコマンド ライン自体に表示するのではなく、OCR 出力をテキスト ファイルに保存したいとします。 この場合、代わりに次のコマンドを入力できます:
tesseract handwritten_photo_1.png output.txt
handwritten_photo_1.png内のテキストは、現在の作業ディレクトリ (私の場合は Desktop) にある output.txt というテキスト ファイルに格納されます。
Tesseract は、テキスト ファイルを入力として受け取ることもできます。テキストには、処理したいイメージの絶対パスがすべて含まれている必要があります。
これは、たとえば、C:\Program Files ディレクトリに handwritten_photo_1.png と handwritten_photo_2.png という英語の手書きのイメージがあるとすると、特に便利です。 さて、現在の作業ディレクトリに、input.txt というテキストファイルがあり、その内容は、
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
1 行目と 2 行目にそれぞれあります。
さて、この 2 つの手書き写真の内容をテキストファイルに格納したい場合、次のようにすればよいでしょう:
tesseract input.txt output.txt -l eng
output.txt には handwritten_photo_1.png と handwritten_photo_2.png、両方の OCR内容が順に含まれることになります。 ここで、input.txtはカレントワーキングディレクトリにあったことに注意が必要です。
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt のようにディレクトリを指定すれば、現在の作業ディレクトリにないテキストファイルでもテッセラクトを利用することができます。 この操作は、2枚以上の写真に対して行うこともできます。 なお、output.txtファイル内の新しい写真の予測は、次のような記号が先頭に付きます。
つまりこの場合、Viral Calicは最初のイメージ、CY am the king of the worldは2枚目、Com and Serrは3枚目と、予測されるイメージということです。 すべての入力画像に対して出力を確認し、予測の精度をチェックすることができます。
以上です。 おめでとうございます。これで、Windows 10システムでTesseractを使用する準備が整いました。