Quantrium Guides
.

Tesseract je engine pro optické rozpoznávání znaků, který lze použít v různých operačních systémech. Jedná se o svobodný software vydaný pod licencí Apache. Původně byl Tesseract vyvinut společností Hewlett-Packard jako proprietární software v 80. letech 20. století, později byl v roce 2005 uvolněn jako open source software. Od roku 2006 pak jeho vývoj sponzoruje společnost Google. V této příručce vás provedu kroky, kterými jsem se řídil při instalaci programu Tesseract do počítače se systémem Windows 10. Ukážu vám také, jak můžete tesseract používat z příkazového řádku, jakmile jej úspěšně nainstalujete.
Chcete-li nainstalovat Tesseract 4 do našeho systému Windows, přejděte na následující odkaz:
Stáhněte spustitelný soubor systému Windows kliknutím na hypertextový odkaz s názvem tesseract-ocr-w64-setup-v4.1.0.20190314.exe. Zobrazí se oznámení s výzvou k uložení exe souboru s názvem „Tesseract-ocr-w64-setup-v4.1.0.20190314.exe“. Uložte tento exe soubor kamkoli, kde máte dostatek úložného prostoru.
Otevřete tento exe soubor. Pokud se vás okno zeptá „Do you want to allow this software to make changes to your system“, klikněte na yes. Budete přesměrováni do sekce instalace.
Stiskněte tlačítko Další, klikněte na tlačítko Souhlasím s podmínkami a po výběru, pro koho a co všechno chcete Tesseract nainstalovat (pro kohokoli, kdo používá tento počítač/jen pro mě. Můžete vybrat obojí), klikněte na tlačítko Další.
Zaškrtněte políčka s nápisy „ScrollView“, „Training Tools“, „Shortcuts creation“ a důležitě „Language data“. Ty by měly být ve výchozím nastavení zaškrtnuty, ale udělejte to pro případ, že by ve vašem systému zaškrtnuty nebyly.
Nyní, pokud chcete provádět předpovědi v cizích jazycích, jako je japonština, čínština, kurdština nebo v indických jazycích, jako je hindština, tamilština, bengálština atd. zaškrtněte také „dodatečná data písma“ a „dodatečná data jazyka“. Pokud chcete provádět předpovědi pouze pro angličtinu, nemusíte tuto možnost zaškrtávat.
Klikněte na tlačítko Další. Vyberte adresář, do kterého chcete nainstalovat aplikaci Tesseract. Ve výchozím nastavení se mi zobrazuje C:\Program Files\Tesseract-OCR a tam jsem ho nainstaloval. Můžete jej nainstalovat podle svého výběru. Všimněte si však cesty, kam jste Tesseract nainstalovali do svého počítače. Je to důležité.
Nyní můžete vybrat složku nabídky Start, ve které chcete vytvořit zástupce programů. Já jsem ho vytvořil ve složce s názvem „Tesseract-OCR“. Pokud ji chcete mít v nové složce, stačí zadat název složky do prázdného místa vpravo pod textem „Vyberte složku nabídky Start, ve které chcete ….“.
Můžete také zaškrtnout políčko „Nevytvářet zástupce“ vlevo dole, pokud nechcete vytvářet žádné zástupce. Po dokončení výběru preferované možnosti klikněte na tlačítko Instalovat. Instalace by měla trvat několik minut.
Po dokončení instalace přejděte do adresáře, kam jste nainstalovali svůj Tesseract. Chceme používat Tesseract z příkazového řádku Windows a k tomu musíme přidat Tesseract do cesty v systémové proměnné prostředí.
To provedete tak, že kliknete na tlačítko Start ve Windows a vyhledáte „proměnná prostředí“. Zobrazí se výsledek s názvem „Upravit systémové proměnné prostředí“. Klepněte na něj. Po kliknutí na něj byste se měli nacházet v části „Upřesnit“ v části „Vlastnosti systému“ a vpravo dole by mělo být vidět tlačítko s názvem „Proměnné prostředí ….“. Klikněte na toto tlačítko.
Nyní zde uvidíte dvě tabulky. Jednu s názvem User variables for <username>. Zde <username> je proměnná, která znamená uživatelské jméno používající v současné době počítač. Druhá tabulka se jmenuje „Systémové proměnné“. V tabulce „Systémové proměnné“ klikněte na proměnnou s názvem „Cesta“ a poté klikněte na toto tlačítko s názvem „Upravit“ přímo nad tlačítkem „OK“, jak je znázorněno dole na obrázku níže.
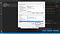
Po dokončení se zobrazí stránka s názvem „Upravit proměnnou prostředí“. Zde vpravo nahoře uvidíte tlačítko s názvem „Nový“. Klikněte na toto tlačítko „Nový“. Zobrazí se prázdné místo, kam můžete přidat nějaký text. Zde přidejte název adresáře, ve kterém jsou uloženy všechny soubory Tesseract-OCR.
Jakmile zadáte název adresáře, stiskněte tlačítko „Enter“ a zkontrolujte, zda byl název vašeho adresáře přidán do tabulky „Upravit proměnnou prostředí“. Jakmile se tak stane, klepněte na tlačítko „OK“. Na stránce „Proměnné prostředí“ znovu klikněte na tlačítko OK. Na stránce „System Properties“ (Vlastnosti systému) znovu klikněte na „OK“. Nyní jste museli ukončit všechny možnosti nastavení.
Otevřete příkazový řádek a na příkazovém řádku zadejte tesseract --version a stiskněte enter. Zobrazí se něco takového:
Pokud se zobrazí nějaká chyba jako tesseract command not found, s největší pravděpodobností jste při postupu podle tohoto návodu udělali nějakou chybu. Vraťte se zpět a podívejte se, kde jste udělali chybu, a pokuste se ji opravit. Případně můžete celý postup zopakovat znovu.
Skvělé! Nyní máte v počítači nainstalovaný program Tesseract. Můžete si s ním začít hrát a dále ho zkoumat.
Jak používat Tesseract 4 pomocí příkazového řádku v počítači se systémem Windows
Nejprve se ujistěte, že máte nějaký ručně psaný dokument nebo nějaký psaný dokument ve formě obrázku. Řekněme, že máte na ploše nějakou fotografii ve tvaru png s názvem handwritten_photo_1 a chcete s ní vyzkoušet Tesseract. Otevřete si příkazový řádek. Začnete v tomto adresáři:
C:\Users\username>
kde username je vaše uživatelské jméno v daném systému. Potřebuji přejít do adresáře pracovní plochy. Použiji tedy následující příkaz:
C:\Users\username> cd Desktop
Nyní jsem v adresáři Plocha, kde se nachází můj obraz. Můžete se podívat, jaký text Tesseract předpovídá v dokumentu pomocí následujícího příkazu:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseract přímo vypíše text v samotném příkazovém řádku. Parametr -l slouží k zadání jazyka. Zde jsme jej zadali jako angličtinu, což je stejně výchozí případ, takže použití -l eng bylo v tomto případě zbytečné. Pokud chcete pro OCR použít nějaký jiný jazyk, podívejte se na tento odkaz zde, kde jsou všechny soubory .traineddata, které určují jazyk:
Řekněme, že máte textový dokument napsaný v hindštině. Pak přejděte na tento výše uvedený odkaz, klikněte na soubor s názvem hin.traineddata a stáhněte jej. Jakmile jej stáhnete, musíte jej přesunout do složky „tessdata“, která bude uvnitř adresáře, kam jste původně nainstalovali tesseract. Jakmile tak učiníte, můžete provést OCR hindských dokumentů pomocí následujícího příkazu:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
Místo zobrazení výstupu OCR na samotném příkazovém řádku řekněme, že chcete, aby byl výstup OCR uložen v textovém souboru. V takovém případě můžete místo toho zadat následující příkaz:
tesseract handwritten_photo_1.png output.txt
Text v handwritten_photo_1.png bude uložen do textového souboru s názvem output.txt, který bude umístěn ve vašem současném pracovním adresáři, což byla v mém případě plocha.
Tesseract může také jako vstup přijmout textový soubor, přičemž text musí obsahovat všechny absolutní cesty k obrázkům, které chcete zpracovat.
To je užitečné zejména tehdy, když máte řekněme dva obrázky psané rukou v angličtině s názvy handwritten_photo_1.png a handwritten_photo_2.png v adresáři C:\Program Files. Nyní máte ve svém současném pracovním adresáři textový soubor s názvem input.txt, jehož obsah je:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
V prvním řádku a ve druhém řádku.
Nyní, pokud chcete uložit obsah těchto dvou ručně psaných obrázků do textového souboru, stačí udělat následující:
tesseract input.txt output.txt -l eng
output.txt bude mít OCR obsah obou handwritten_photo_1.png a handwritten_photo_2.png, v tomto pořadí. Zde byste si měli uvědomit, že input.txt byl v aktuálním pracovním adresáři. Tesseract můžete použít i na textový soubor, který se nenachází v aktuálním pracovním adresáři, a to tak, že uvedete umístění adresáře jako zde:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt bude opět umístěn v aktuálním pracovním adresáři. Tento postup můžete provést i pro více než dvě fotografie. Všimněte si, že predikci pro novou fotografii v souboru output.txt bude předcházet nějaký symbol jako např:
V tomto případě je tedy Viral Calic predikce pro první snímek, CY am the king of the world predikce pro druhý snímek, Com and Serr predikce pro třetí snímek atd. Můžete zkontrolovat výstup pro všechny vstupní obrázky a ověřit přesnost předpovědí.
To je vše! Gratulujeme, nyní máte vše připraveno a můžete systém Tesseract používat v systému Windows 10.