Úvod
V každém odvětví je důležité porozumět chování zákazníků. Uvědomil jsem si to loni, když se mě můj šéf marketingu zeptal – „Můžete mi říct, na které stávající zákazníky bychom měli zacílit náš nový produkt?“
To pro mě byla docela velká škola. Jako datový vědec jsem si rychle uvědomil, jak důležité je segmentovat zákazníky, aby moje organizace mohla přizpůsobit a vytvořit cílené strategie. Tady se mi koncept shlukování náramně hodil!
Problémy, jako je segmentace zákazníků, jsou často ošidné, protože nepracujeme s žádnou cílovou proměnnou na mysli. Oficiálně se nacházíme v zemi neřízeného učení, kde musíme přijít na vzory a struktury, aniž bychom měli na mysli stanovený výsledek. Pro datového vědce je to náročné a vzrušující zároveň.
Nyní existuje několik různých způsobů, jak provádět shlukování (jak uvidíte níže). V tomto článku vás seznámím s jedním takovým typem – hierarchickým shlukováním.
Dozvíte se, co je hierarchické shlukování, jaká je jeho výhoda oproti ostatním algoritmům shlukování, jaké jsou různé typy hierarchického shlukování a jak postupovat při jeho provádění. Nakonec se ujmeme datové sady pro segmentaci zákazníků a poté implementujeme hierarchické shlukování v jazyce Python. Tuto techniku miluji a jsem si jistý, že po tomto článku ji budete milovat i vy!“
Poznámka: Jak již bylo zmíněno, existuje více způsobů, jak shlukování provádět. Doporučuji vám, abyste se podívali na našeho úžasného průvodce různými typy shlukování:
- Úvod do shlukování a různé metody shlukování
Chcete-li se dozvědět více o shlukování a dalších algoritmech strojového učení (pod dohledem i bez dohledu), podívejte se na následující komplexní program-
- Certifikovaný program AI & ML Blackbelt+
Obsah
- Supervised vs Unsupervised Learning
- Proč hierarchické shlukování?
- Co je to hierarchické shlukování?
- Typy hierarchického shlukování
- Aglomerativní hierarchické shlukování
- Divizní hierarchické shlukování
- Kroky při provádění hierarchického shlukování
- Jak zvolit počet shluků při hierarchickém shlukování?
- Řešení problému segmentace velkoobchodních zákazníků pomocí hierarchického shlukování
Učení pod dohledem vs. učení bez dohledu
Než se ponoříme do hierarchického shlukování, je důležité pochopit rozdíl mezi učením bez dohledu a s dohledem. Vysvětlím tento rozdíl na jednoduchém příkladu.
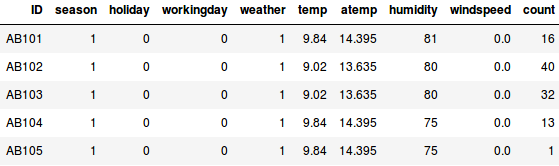
Předpokládejme, že chceme odhadnout počet jízdních kol, která se budou každý den ve městě půjčovat:
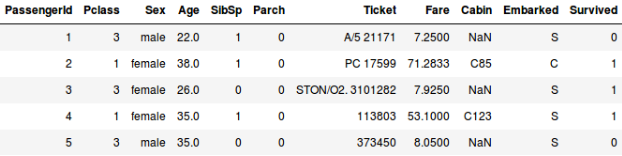
Nebo řekněme, že chceme předpovědět, zda osoba na palubě Titaniku přežila, nebo ne:
V obou těchto příkladech máme pevně stanovený cíl, kterého chceme dosáhnout:
- V prvním příkladu musíme předpovědět počet kol na základě vlastností, jako je roční období, svátek, pracovní den, počasí, teplota atd.
- V druhém příkladu předpovídáme, zda cestující přežil, nebo ne. V proměnné „Přežil“ znamená 0, že osoba nepřežila, a 1, že osoba přežila. Nezávislé proměnné zde zahrnují Pclass, Sex, Age, Fare atd.
Pokud tedy máme zadanou cílovou proměnnou (počet a Survival ve výše uvedených dvou případech), kterou máme předpovědět na základě daného souboru prediktorů neboli nezávislých proměnných (sezóna, dovolená, Sex, Age atd.), takové problémy se nazývají problémy učení pod dohledem.
Podívejme se na následující obrázek, abychom to názorně pochopili:
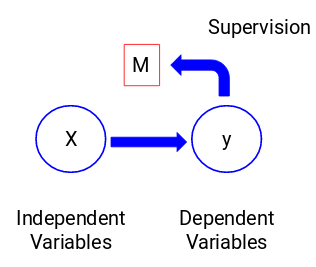
Zde je y naše závislá nebo cílová proměnná a X představuje nezávislé proměnné. Cílová proměnná je závislá na X, a proto se také nazývá závislá proměnná. Náš model trénujeme pomocí nezávislých proměnných při dohledu nad cílovou proměnnou a odtud název učení s dohledem.
Naším cílem při trénování modelu je vytvořit funkci, která mapuje nezávislé proměnné na požadovanou cílovou proměnnou. Jakmile je model natrénován, můžeme mu předávat nové sady pozorování a model pro ně bude předpovídat cíl. To je ve zkratce učení pod dohledem.
Mohou nastat situace, kdy nemáme k dispozici žádnou cílovou proměnnou, kterou bychom mohli předpovídat. Takové problémy bez explicitní cílové proměnné se nazývají problémy učení bez dohledu. V těchto problémech máme pouze nezávislé proměnné a žádnou cílovou/závislou proměnnou.

V těchto případech se snažíme rozdělit celá data do množiny skupin. Tyto skupiny se nazývají shluky a proces vytváření těchto shluků je znám jako shlukování.
Tato technika se obecně používá pro shlukování populace do různých skupin. Několik běžných příkladů zahrnuje segmentaci zákazníků, shlukování podobných dokumentů, doporučování podobných písní nebo filmů atd.
Použití učení bez dohledu je mnohem více. Pokud narazíte na nějakou zajímavou aplikaci, neváhejte se o ni podělit v komentářích níže!
Nyní existují různé algoritmy, které nám pomáhají tyto shluky vytvářet. Nejčastěji používané shlukovací algoritmy jsou K-means a hierarchické shlukování.
Proč hierarchické shlukování?
Nejprve bychom měli vědět, jak funguje K-means, než se ponoříme do hierarchického shlukování. Věřte mi, že díky tomu bude koncept hierarchického shlukování o to jednodušší.
Tady je stručný přehled toho, jak K-means funguje:
- Rozhodněte o počtu shluků (k)
- Vyberte k náhodných bodů z dat jako centroidy
- Přiřaďte všechny body do nejbližší centroid shluku
- Vypočítejte centroidy nově vytvořených shluků
- Zopakujte kroky 3 a 4
Jedná se o iterační proces. Bude probíhat tak dlouho, dokud se centroidy nově vytvořených shluků nezmění nebo dokud nebude dosaženo maximálního počtu iterací
S K-means jsou však spojeny určité problémy. Vždy se snaží vytvořit shluky stejné velikosti. Také musíme na začátku algoritmu rozhodnout o počtu shluků. V ideálním případě bychom na začátku algoritmu nevěděli, kolik shluků máme mít, a proto je to u K-means výzva.
Tato mezera hierarchické shlukování překlenuje s přehledem. Odstraňuje problém nutnosti předem definovat počet shluků. Zní to jako sen! Podívejme se tedy, co je hierarchické shlukování a jak vylepšuje K-means.
Co je to hierarchické shlukování?
Řekněme, že máme níže uvedené body a chceme je shlukovat do skupin:

Každý z těchto bodů můžeme přiřadit do samostatného shluku:

Nyní můžeme na základě podobnosti těchto shluků spojit nejpodobnější shluky dohromady a tento proces opakovat, dokud nezbude pouze jediný shluk:
V podstatě vytváříme hierarchii shluků. Proto se tento algoritmus nazývá hierarchické shlukování. O tom, jak rozhodnout o počtu shluků, pojednám v některém z dalších oddílů. Prozatím se podívejme na různé typy hierarchického shlukování.
Typy hierarchického shlukování
Existují především dva typy hierarchického shlukování:
- Aglomerativní hierarchické shlukování
- Divizní hierarchické shlukování
Pochopme každý typ podrobně.
Aglomerativní hierarchické shlukování
V této technice přiřazujeme každý bod k jednotlivému shluku. Předpokládejme, že existují 4 datové body. Každý z těchto bodů přiřadíme ke shluku, a proto budeme mít na začátku 4 shluky:
Poté v každé iteraci sloučíme nejbližší dvojici shluků a tento krok opakujeme, dokud nezůstane pouze jediný shluk:
Slučujeme (nebo přidáváme) shluky v každém kroku, že? Proto se tento typ shlukování nazývá také aditivní hierarchické shlukování.
Divizní hierarchické shlukování
Divizní hierarchické shlukování funguje opačným způsobem. Místo toho, abychom začali s n shluky (v případě n pozorování), začneme s jedním shlukem a do něj přiřadíme všechny body.
Nezáleží tedy na tom, zda máme 10 nebo 1000 datových bodů. Všechny tyto body budou na začátku patřit do stejného shluku:
Nyní při každé iteraci rozdělíme nejvzdálenější bod ve shluku a tento proces opakujeme, dokud každý shluk neobsahuje pouze jeden bod:
V každém kroku rozdělujeme (nebo dělíme) shluky, odtud název divizní hierarchické shlukování.
Aglomerativní shlukování je v průmyslu hojně využíváno a právě na něj se zaměříme v tomto článku. Divizivní hierarchické shlukování bude hračka, jakmile zvládneme aglomerativní typ.
Kroky při provádění hierarchického shlukování
Při hierarchickém shlukování spojujeme nejpodobnější body neboli shluky – to víme. Nyní otázka zní – jak rozhodneme, které body jsou podobné a které ne? Je to jedna z nejdůležitějších otázek při shlukování!“
Jednou z možností, jak vypočítat podobnost, je vzít vzdálenost mezi centroidy těchto shluků. Body, které mají nejmenší vzdálenost, označíme jako podobné body a můžeme je sloučit. Můžeme to také označit jako algoritmus založený na vzdálenosti (protože počítáme vzdálenosti mezi shluky).
V hierarchickém shlukování máme pojem zvaný matice blízkosti. Ta uchovává vzdálenosti mezi jednotlivými body. Podívejme se na příklad, abychom pochopili tuto matici i kroky k provedení hierarchického shlukování.
Nastavení příkladu

Předpokládejme, že učitel chce rozdělit své studenty do různých skupin. Má k dispozici známky, které každý student získal v zadání, a na základě těchto známek je chce rozdělit do skupin. Neexistuje zde žádný pevný cíl, kolik skupin má mít. Protože učitel neví, jaký typ studentů by měl být zařazen do které skupiny, nelze to řešit jako problém učení pod dohledem. Pokusíme se zde tedy použít hierarchické shlukování a segmentovat studenty do různých skupin.
Vezměme vzorek 5 studentů:
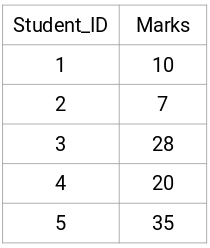
Vytvoření matice blízkosti
Nejprve vytvoříme matici blízkosti, která nám řekne vzdálenost mezi jednotlivými body. Protože počítáme vzdálenost každého bodu od každého z ostatních bodů, dostaneme čtvercovou matici tvaru n X n (kde n je počet pozorování).
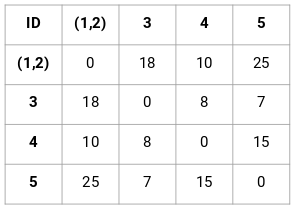
Pro náš příklad vytvoříme matici přiblížení 5 x 5:
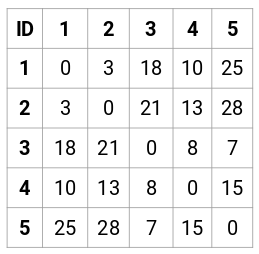
Diagonální prvky této matice budou vždy 0, protože vzdálenost bodu se sebou samým je vždy 0. Pro výpočet ostatních vzdáleností použijeme vzorec pro euklidovskou vzdálenost. Řekněme tedy, že chceme vypočítat vzdálenost mezi body 1 a 2:
√(10-7)^2 = √9 = 3
Podobně můžeme vypočítat všechny vzdálenosti a vyplnit matici blízkosti.
Kroky provedení hierarchického shlukování
Krok 1: Nejprve přiřadíme všechny body k jednotlivým shlukům:
![]()
Různé barvy zde představují různé shluky. Vidíte, že pro 5 bodů v našich datech máme 5 různých shluků.
Krok 2: Dále se podíváme na nejmenší vzdálenost v matici blízkosti a body s nejmenší vzdáleností sloučíme. Poté aktualizujeme matici blízkosti:
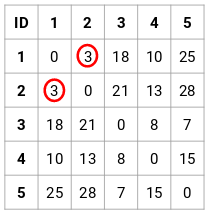
Zde je nejmenší vzdálenost 3, a proto sloučíme bod 1 a 2:
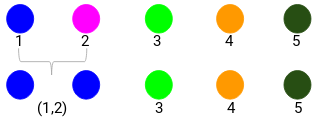
Podíváme se na aktualizované shluky a podle toho aktualizujeme matici blízkosti:
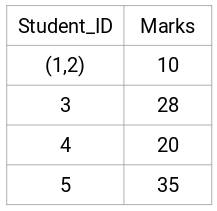
Zde jsme vzali maximum ze dvou značek (7, 10), které nahradí značky pro tento shluk. Místo maxima můžeme také vzít minimální hodnotu nebo také průměrné hodnoty. Nyní opět vypočítáme matici blízkosti pro tyto shluky:
Krok 3: Budeme opakovat krok 2, dokud nezbude pouze jediný shluk.
Takže se nejprve podíváme na minimální vzdálenost v matici blízkosti a poté sloučíme nejbližší dvojici shluků. Po opakování těchto kroků získáme sloučené shluky podle následujícího obrázku:
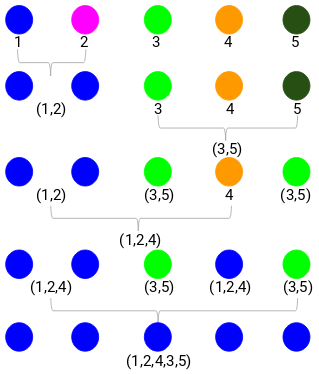
Začali jsme s 5 shluky a nakonec máme jediný shluk. Takto funguje aglomerativní hierarchické shlukování. Stále však zůstává palčivá otázka – jak rozhodneme o počtu shluků? Tomu porozumíme v následující části.
Jak máme zvolit počet shluků při hierarchickém shlukování?“
Jste připraveni konečně odpovědět na tuto otázku, která se s námi táhne od začátku výuky? Abychom zjistili počet shluků pro hierarchické shlukování, využijeme úžasný koncept zvaný dendrogram.
Dendrogram je stromový diagram, který zaznamenává posloupnosti sloučení nebo rozdělení.
Vraťme se k našemu příkladu učitel-student. Kdykoli sloučíme dva shluky, dendrogram zaznamená vzdálenost mezi těmito shluky a znázorní ji ve formě grafu. Podívejme se, jak vypadá dendrogram:
Na ose x máme vzorky souboru dat a na ose y vzdálenost. Kdykoli dojde ke sloučení dvou shluků, spojíme je v tomto dendrogramu a výškou spojení bude vzdálenost mezi těmito body. Sestavme dendrogram pro náš příklad:
Zpracujte chvíli výše uvedený obrázek. Začali jsme sloučením vzorku 1 a 2 a vzdálenost mezi těmito dvěma vzorky byla 3 (viz první matice blízkosti v předchozí části). Vyneseme to do dendrogramu:
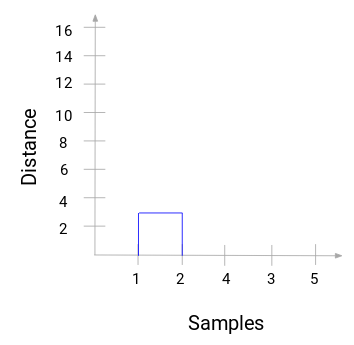
Zde vidíme, že jsme sloučili vzorek 1 a vzorek 2. V tomto grafu je vidět, že jsme sloučili vzorek 1 a vzorek 2. Svislá čára představuje vzdálenost mezi těmito vzorky. Podobně vykreslíme všechny kroky, ve kterých jsme sloučili shluky, a nakonec dostaneme dendrogram takto:
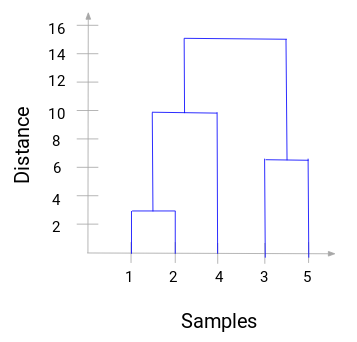
Můžeme jasně vizualizovat kroky hierarchického shlukování. Větší vzdálenost svislých čar v dendrogramu znamená větší vzdálenost mezi těmito shluky.
Nyní můžeme nastavit vzdálenost prahu a nakreslit vodorovnou čáru (Obecně se snažíme nastavit práh tak, aby protínal nejvyšší svislou čáru). Nastavme tento práh na hodnotu 12 a nakresleme vodorovnou čáru:
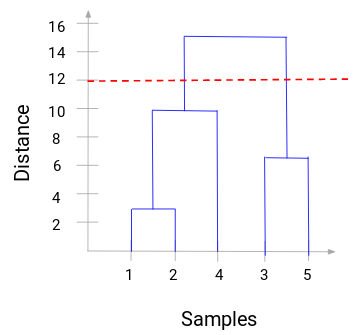
Počet shluků bude odpovídat počtu svislých čar, které protíná čára nakreslená pomocí prahu. Ve výše uvedeném příkladu, protože červená čára protíná 2 svislé čáry, budeme mít 2 shluky. Jeden shluk bude mít vzorek (1,2,4) a druhý bude mít vzorek (3,5). Celkem jednoduché, že?“
Takto můžeme rozhodnout o počtu shluků pomocí dendrogramu v hierarchickém shlukování. V následující části budeme implementovat hierarchické shlukování, které vám pomůže pochopit všechny pojmy, které jsme se v tomto článku naučili.
Řešení problému segmentace velkoobchodních zákazníků pomocí hierarchického shlukování
Čas zašpinit si ruce v jazyce Python!
Budeme řešit problém segmentace velkoobchodních zákazníků. Datovou sadu si můžete stáhnout pomocí tohoto odkazu. Data jsou umístěna na úložišti UCI Machine Learning. Cílem tohoto problému je segmentovat klienty velkoobchodního distributora na základě jejich ročních výdajů na různé kategorie produktů, jako je mléko, potraviny, region atd.
Nejprve data prozkoumáme a poté použijeme Hierarchické shlukování k segmentaci klientů.
Nejprve naimportujeme potřebné knihovny:
Načteme data a podíváme se na několik prvních řádků:
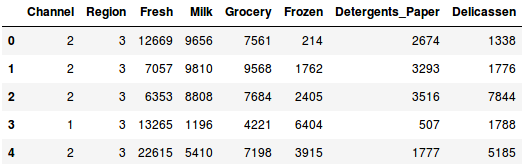
Je zde více kategorií produktů – čerstvé, mléko, potraviny atd. Hodnoty představují počet jednotek zakoupených jednotlivými klienty pro každý výrobek. Naším cílem je vytvořit z těchto dat shluky, které mohou segmentovat podobné klienty dohromady. Pro tento problém samozřejmě použijeme hierarchické shlukování.
Před použitím hierarchického shlukování však musíme data normalizovat, aby měřítka jednotlivých proměnných byla stejná. Proč je to důležité? Inu, pokud by měřítko proměnných nebylo stejné, model by se mohl vychýlit směrem k proměnným s vyšší velikostí, jako je Čerstvé nebo Mléko (viz výše uvedená tabulka).
Nejprve tedy data normalizujme a uveďme všechny proměnné do stejného měřítka:
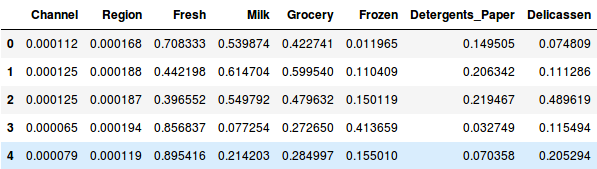
Zde vidíme, že měřítko všech proměnných je téměř podobné. Nyní můžeme začít. Nejprve nakreslíme dendrogram, který nám pomůže rozhodnout o počtu shluků pro tento konkrétní problém:
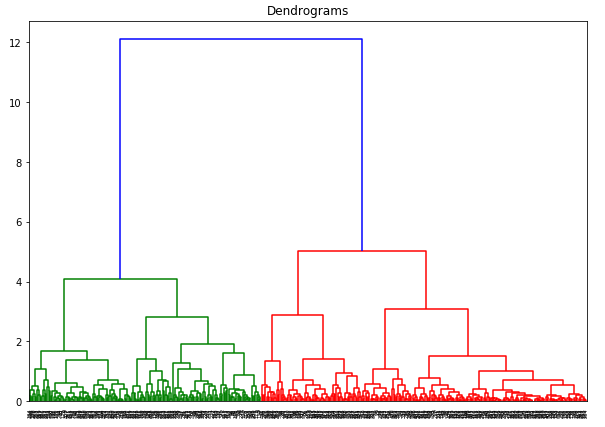
Osa x obsahuje vzorky a osa y představuje vzdálenost mezi těmito vzorky. Svislá čára s maximální vzdáleností je modrá čára, a proto můžeme rozhodnout o prahu 6 a dendrogram rozříznout:
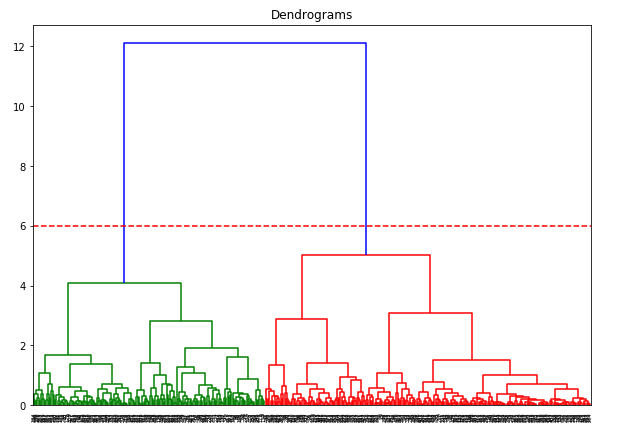
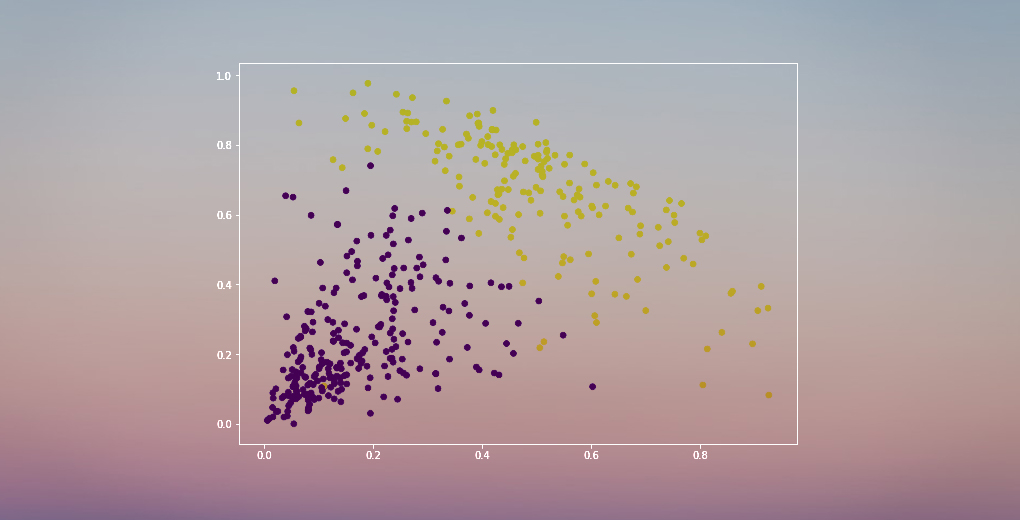
Máme dva shluky, protože tato čára rozřezává dendrogram ve dvou bodech. Nyní použijeme hierarchické shlukování pro 2 shluky:
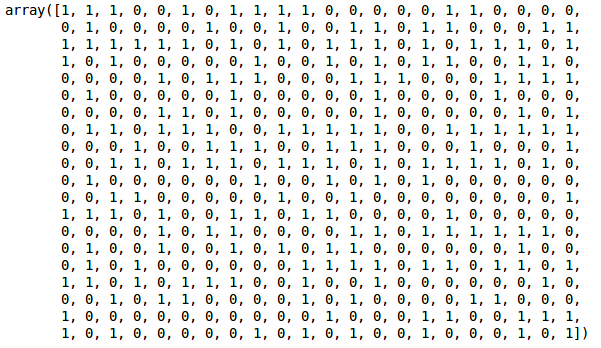
Ve výstupu vidíme hodnoty 0 a 1, protože jsme definovali 2 shluky. Hodnota 0 představuje body, které patří do prvního shluku, a hodnota 1 představuje body ve druhém shluku. Nyní si oba shluky vizualizujme:
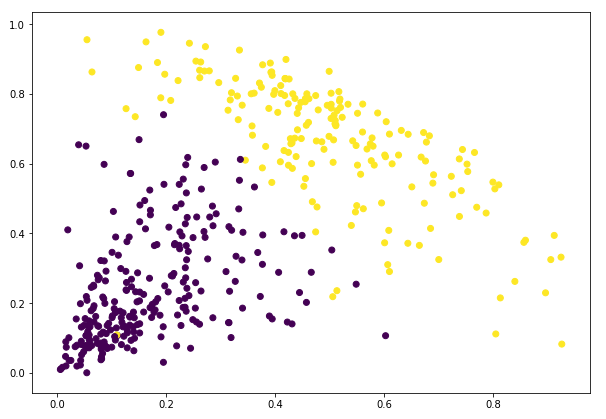
Úžasné! Zde můžeme jasně vizualizovat oba shluky. Takto můžeme implementovat hierarchické shlukování v jazyce Python.
Koncové poznámky
Hierarchické shlukování je super užitečný způsob segmentace pozorování. Výhoda toho, že nemusíte předem definovat počet shluků, mu dává oproti k-Means docela výhodu.
Pokud jste v datové vědě ještě relativně noví, vřele doporučuji absolvovat kurz Aplikované strojové učení. Je to jeden z nejkomplexnějších komplexních kurzů strojového učení, jaký kde najdete. Hierarchické shlukování je jen jedním z rozmanitých témat, kterým se v kurzu věnujeme.