Úvod
Rozhodovací strom je typ algoritmu učení pod dohledem, který lze použít v regresních i klasifikačních úlohách. Funguje jak pro kategoriální, tak pro spojité vstupní a výstupní proměnné.
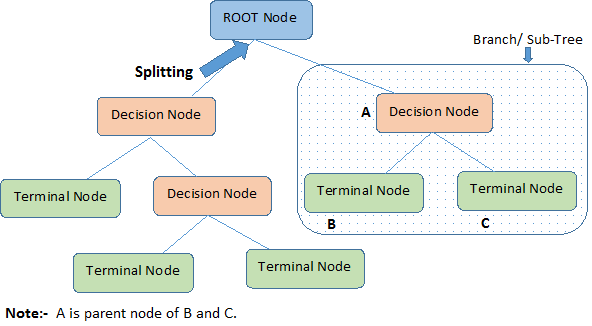
Podíváme-li se na obrázek výše, určíme důležité pojmy týkající se rozhodovacího stromu:
-
Kořenový uzel představuje celou populaci nebo vzorek. Dále se dělí na dva nebo více homogenních souborů.
-
Rozdělení je proces rozdělení uzlu na dva nebo více dílčích uzlů.
-
Když se dílčí uzel rozdělí na další dílčí uzly, nazývá se rozhodovací uzel.
-
Uzly, které se nerozdělují, se nazývají koncový uzel nebo list.
-
Když odstraníte dílčí uzly rozhodovacího uzlu, nazývá se tento proces prořezávání. Opakem prořezávání je Rozdělení.
-
Dílčí úsek celého stromu se nazývá Větev.
-
Uzel, který je rozdělen na dílčí uzly, se nazývá rodičovský uzel dílčích uzlů; zatímco dílčí uzly se nazývají potomci rodičovského uzlu.
Typy rozhodovacích stromů
Regresní stromy
Podívejme se na následující obrázek, který pomáhá vizualizovat povahu rozdělení prováděného regresním stromem. Je na něm zobrazen neprořezaný strom a regresní strom přizpůsobený náhodnému souboru dat. Obě vizualizace ukazují řadu pravidel rozdělení, počínaje vrcholem stromu. Všimněte si, že každé rozdělení domény je zarovnáno s jednou z os prvků. Koncept paralelního dělení podle os se přímočaře zobecňuje na dimenze větší než dvě. Pro prostor příznaků o velikosti $p$, podmnožinu $\mathbb{R}^p$, je prostor rozdělen na $M$ oblastí, $R_{m}$, z nichž každá je „hyperblok“ o velikosti $p$.
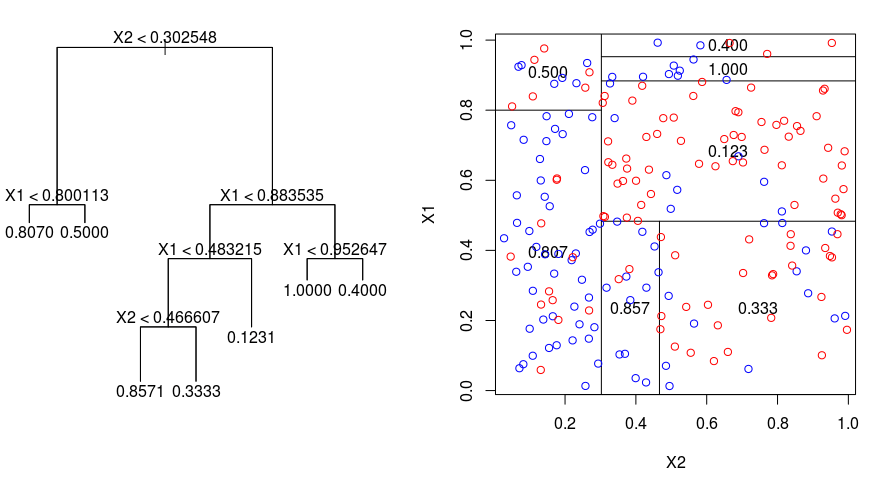
Pro sestavení regresního stromu nejprve použijete rekurzivní binární splititng k růstu velkého stromu na trénovacích datech, který se zastaví pouze tehdy, když každý koncový uzel má méně než nějaký minimální počet pozorování. Rekurzivní binární rozdělení je chamtivý algoritmus shora dolů, který se používá k minimalizaci zbytkové sumy čtverců (RSS), což je míra chyby používaná také v nastavení lineární regrese. RSS je v případě rozděleného prostoru příznaků s M oddíly dána vztahem:
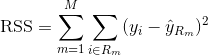
Začínáte-li na vrcholu stromu, rozdělíte jej na 2 větve, čímž vytvoříte rozdělení 2 prostorů. Toto konkrétní rozdělení v horní části stromu pak provedete vícekrát a vyberete takové rozdělení funkcí, které minimalizuje (aktuální) RSS.
Následujícím krokem aplikujete na velký strom prořezávání složitosti nákladů, abyste získali posloupnost nejlepších podstromů jako funkci $\alfa$. Základní myšlenkou je zavedení dalšího ladicího parametru označeného $\alfa$, který vyvažuje hloubku stromu a jeho dobrou shodu s trénovacími daty.
K volbě $\alfa$ můžete použít K-násobnou křížovou validaci. Tato technika jednoduše spočívá v rozdělení trénovacích pozorování na K záhybů, aby bylo možné odhadnout chybovost testovacích podstromů. Vaším cílem je vybrat ten, který vede k nejnižší chybovosti.
Klasifikační stromy
Klasifikační strom je velmi podobný regresnímu stromu s tím rozdílem, že se používá k předpovědi kvalitativní odpovědi, nikoli kvantitativní.
Připomeňte si, že u regresního stromu je předpovězená odpověď pro pozorování dána průměrnou odpovědí trénovacích pozorování, která patří do stejného koncového uzlu. Naproti tomu u klasifikačního stromu předpovídáte, že každé pozorování patří do nejčastěji se vyskytující třídy trénovacích pozorování v oblasti, do které patří.
Při interpretaci výsledků klasifikačního stromu vás často zajímá nejen předpověď třídy odpovídající určité oblasti terminálního uzlu, ale také proporce tříd mezi trénovacími pozorováními, která do této oblasti patří.
Úloha pěstování klasifikačního stromu je dosti podobná úloze pěstování regresního stromu. Stejně jako v případě regrese se k růstu klasifikačního stromu používá rekurzivní binární rozdělení. V klasifikačním nastavení však nelze jako kritérium pro provedení binárního rozdělení použít zbytkový součet čtverců. Místo toho můžete použít některou z těchto 3 níže uvedených metod:
- Míra chybovosti klasifikace: Místo toho, abyste zjišťovali, jak daleko je číselná odpověď od střední hodnoty, jako je tomu v nastavení regrese, můžete místo toho definovat „míru zásahu“ jako podíl trénovacích pozorování v určité oblasti, která nepatří do nejčastěji se vyskytující třídy. Chyba je dána touto rovnicí:
E = 1 – argmaxc($\hat{\pi}_{mc}$)
v níž $\hat{\pi}_{mc}$ představuje podíl trénovacích dat v oblasti Rm, která patří do třídy c.
- Giniho index: Giniho index je alternativní chybová metrika, která má ukázat, jak „čistá“ je daná oblast. „Čistota“ v tomto případě znamená, jak velká část trénovacích dat v daném regionu patří do jedné třídy. Pokud oblast Rm obsahuje data, která jsou většinou z jediné třídy c, pak hodnota Giniho indexu bude malá:
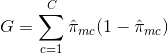
- Křížová antropie: Třetí alternativa, která je podobná Giniho indexu, je známá jako křížová entropie nebo odchylka:
Křížová entropie bude nabývat hodnoty blízké nule, pokud budou všechny hodnoty $\hat{\pi}_{mc}$ blízké 0 nebo blízké 1. Podobně jako Giniho index bude tedy křížová entropie nabývat malé hodnoty, pokud je m-tý uzel čistý. Ve skutečnosti se ukazuje, že Giniho index a křížová entropie jsou si číselně docela podobné.
Při sestavování klasifikačního stromu se k hodnocení kvality určitého rozdělení obvykle používá buď Giniho index, nebo křížová entropie, protože jsou citlivější na čistotu uzlů než chybovost klasifikace. Při ořezávání stromu lze použít kterýkoli z těchto tří přístupů, ale míra chybovosti klasifikace je vhodnější, pokud je cílem přesnost predikce konečného ořezaného stromu.
Výhody a nevýhody rozhodovacích stromů
Hlavní výhodou použití rozhodovacích stromů je, že se intuitivně velmi snadno vysvětlují. Ve srovnání s jinými regresními a klasifikačními přístupy věrně odrážejí lidské rozhodování. Lze je zobrazit graficky a snadno pracují s kvalitativními prediktory bez nutnosti vytvářet fiktivní proměnné.
Rozhodovací stromy však obecně nemají stejnou úroveň přesnosti predikce jako jiné přístupy, protože nejsou zcela robustní. Malá změna v datech může způsobit velkou změnu ve výsledném odhadovaném stromu.
Agregací mnoha rozhodovacích stromů pomocí metod, jako jsou bagging, random forests a boosting, lze predikční výkonnost rozhodovacích stromů podstatně zlepšit.
Metody založené na stromech
Bagging
Výše zmíněné rozhodovací stromy trpí velkým rozptylem, což znamená, že pokud tréninková data náhodně rozdělíte na dvě části a na obě poloviny napasujete rozhodovací strom, výsledky, které dostanete, se mohou značně lišit. Naproti tomu postup s nízkým rozptylem poskytne podobné výsledky, pokud bude opakovaně aplikován na odlišný soubor dat.
Sdružování neboli bootstrapová agregace je technika používaná ke snížení rozptylu vašich předpovědí kombinací výsledků více klasifikátorů modelovaných na různých dílčích vzorcích téhož souboru dat. Zde je rovnice pro bagging:
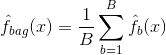
při kterém vytvoříte $B$ různých bootstrapovaných trénovacích souborů dat. Poté trénujete svou metodu na $b-té$ bootstrapované trénovací množině, abyste získali $\hat{f}_{b}(x)$, a nakonec předpovědi zprůměrujete.
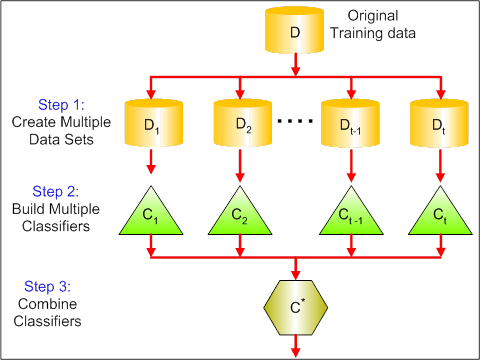
Následující obrázek ukazuje 3 různé kroky při baggingu:
-
Krok 1: Zde nahradíte původní data novými daty. Nová data obvykle obsahují zlomek sloupců a řádků původních dat, které pak lze použít jako hyperparametry v modelu baggingu.
-
Krok 2: Na každém souboru dat sestavíte klasifikátory. Obecně můžete pro tvorbu modelů a předpovědí použít stejný klasifikátor.
-
Krok 3: Nakonec použijete průměrnou hodnotu pro kombinaci předpovědí všech klasifikátorů v závislosti na problému. Obecně platí, že tyto kombinované hodnoty jsou robustnější než jeden model.
Přestože metoda bagging může zlepšit předpovědi u mnoha regresních a klasifikačních metod, je užitečná zejména u rozhodovacích stromů. Chcete-li použít bagging pro regresní/klasifikační stromy, jednoduše zkonstruujete $B$ regresních/klasifikačních stromů pomocí $B$ bootstrapovaných trénovacích sad a výsledné předpovědi zprůměrujete. Tyto stromy jsou pěstovány do hloubky a nejsou ořezávány. Proto má každý jednotlivý strom vysoký rozptyl, ale nízké zkreslení. Zprůměrování těchto $B$ stromů snižuje rozptyl.
Všeobecně řečeno, bylo prokázáno, že metoda bagging poskytuje působivé zlepšení přesnosti spojením stovek nebo dokonce tisíců stromů do jediného postupu.
Náhodné lesy
Náhodné lesy jsou univerzální metoda strojového učení schopná provádět jak regresní, tak klasifikační úlohy. Provádí také metody redukce dimenzí, ošetřuje chybějící hodnoty, odlehlé hodnoty a další nezbytné kroky zkoumání dat a odvádí poměrně dobrou práci.
Random Forests poskytuje vylepšení oproti stromům v pytlích malou úpravou, která stromy dekoruje. Stejně jako v případě baggingu sestavíte řadu rozhodovacích stromů na bootstrapovaných trénovacích vzorcích. Při sestavování těchto rozhodovacích stromů se však při každém zvažování rozdělení stromu vybere náhodný vzorek m prediktorů jako kandidátů na rozdělení z celé množiny $p$ prediktorů. Pro rozdělení je povoleno použít pouze jeden z těchto $m$ prediktorů. To je hlavní rozdíl mezi náhodným lesem a sáčkovým lesem; protože stejně jako u sáčkového lesa je výběr prediktorů $m = p$.
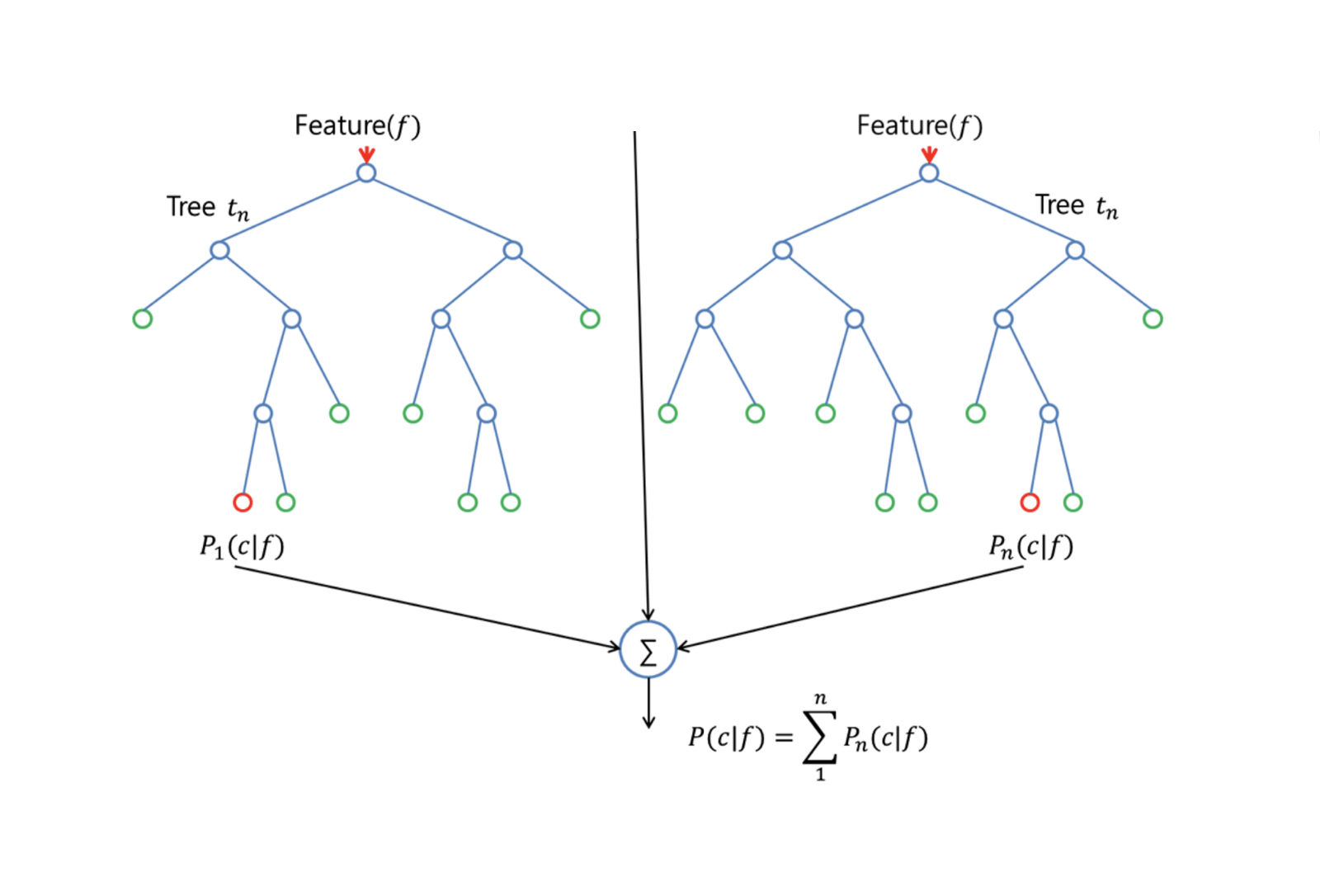
Pro pěstování náhodného lesa byste měli:
-
Nejprve předpokládat, že počet případů v trénovací množině je K. Pak z těchto K případů odeberte náhodný vzorek a tento vzorek použijte jako trénovací množinu pro růst stromu.
-
Pokud je $p$ vstupních proměnných, zadejte číslo $m < p$ takové, abyste v každém uzlu mohli vybrat $m$ náhodných proměnných z $p$. Pro rozdělení uzlu se použije nejlepší rozdělení na těchto $m$.
-
Každý strom se následně rozroste do největšího možného rozsahu a není nutné žádné prořezávání.
-
Nakonec agregujte předpovědi cílových stromů pro předpověď nových dat.
Náhodné lesy jsou velmi efektivní při odhadu chybějících dat a zachování přesnosti, když chybí velká část dat. Dokáže také vyrovnávat chyby v souborech dat, kde jsou třídy nevyvážené. A co je nejdůležitější, dokáže si poradit s masivními datovými sadami s velkou dimenzionalitou. Jednou z nevýhod použití náhodných lesů je však to, že můžete snadno nadměrně přizpůsobit zašuměné datové sady, zejména v případě provádění regrese.
Boosting
Boosting je další přístup ke zlepšení předpovědí vyplývajících z rozhodovacího stromu. Podobně jako u baggingu a náhodných lesů se jedná o obecný přístup, který lze použít u mnoha statistických metod učení pro regresi nebo klasifikaci. Připomeňme, že bagging zahrnuje vytvoření více kopií původního trénovacího souboru dat pomocí bootstrapu, přiřazení samostatného rozhodovacího stromu každé kopii a následné zkombinování všech stromů za účelem vytvoření jediného predikčního modelu. Je pozoruhodné, že každý strom je vytvořen na bootstrapované množině dat, nezávisle na ostatních stromech.
Boosting funguje podobným způsobem s tím rozdílem, že stromy jsou pěstovány postupně: každý strom je pěstován s využitím informací z dříve pěstovaných stromů. Boosting nezahrnuje bootstrapové vzorkování; místo toho je každý strom napasován na upravenou verzi původního souboru dat.
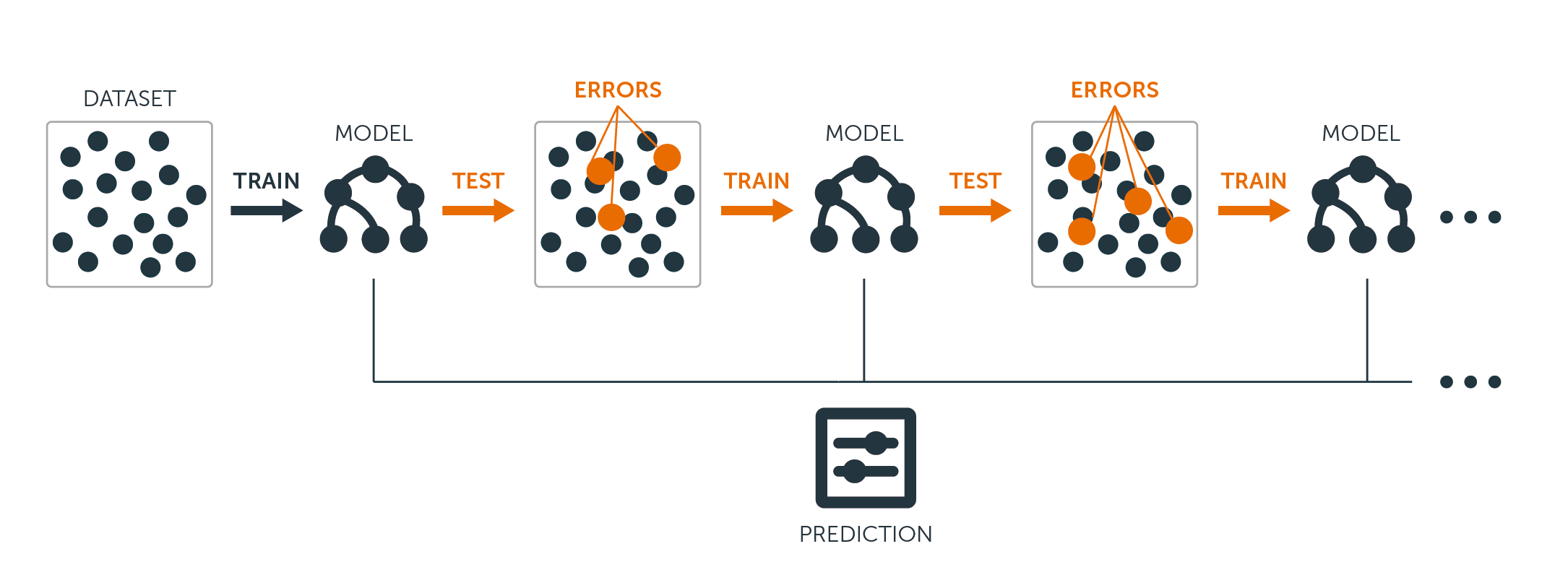
Pro regresní i klasifikační stromy funguje boostování takto:
-
Na rozdíl od přizpůsobení jediného velkého rozhodovacího stromu datům, které se rovná tvrdému přizpůsobení datům a potenciálně nadměrnému přizpůsobení, se přístup boostování místo toho učí pomalu.
-
Díky aktuálnímu modelu přizpůsobíte rozhodovací strom reziduím modelu. To znamená, že fitujete strom s použitím aktuálních reziduí, nikoli výsledku $Y$, jako odpovědi.
-
Tento nový rozhodovací strom pak přidáte do fitované funkce, abyste aktualizovali rezidua. Každý z těchto stromů může být poměrně malý, jen s několika koncovými uzly, které jsou v algoritmu určeny parametrem $d$. Napasováním malých stromů na rezidua pomalu vylepšujete $\hat{f}$ v oblastech, kde nepracuje dobře.
-
Parametr smršťování $\nu$ proces ještě více zpomaluje a umožňuje, aby na rezidua útočilo více stromů různého tvaru.
Boosting je velmi užitečný, pokud máte k dispozici velké množství dat a očekáváte, že rozhodovací stromy budou velmi složité. Boosting se používá k řešení mnoha náročných klasifikačních a regresních problémů, mimo jiné k analýze rizik, analýze sentimentu, prediktivní reklamě, modelování cen, odhadu prodeje a diagnostice pacientů.
Rozhodovací stromy v R
Klasifikační stromy
V této části budete pracovat s datovou sadou Carseats pomocí balíčku tree v R. Mějte na paměti, že nejprve musíte do prostředí R Studio nainstalovat balíčky ISLR a tree. Nejprve načteme datový rámec Carseats z balíčku ISLR.
library(ISLR)data(package="ISLR")carseats<-CarseatsNačteme také balíček tree.
require(tree)Datový soubor Carseats je datový rámec se 400 pozorováními následujících 11 proměnných:
-
Prodej: jednotkový prodej v tisících
-
Cena: cena účtovaná konkurentem na každém místě
-
Příjem: úroveň příjmu komunity v tisících dolarů
-
Reklama: místní rozpočet na reklamu v každé lokalitě v tisících dolarů
-
Populace: počet obyvatel regionu v tisících
-
Cena: cena za autosedačky v každé lokalitě
-
ShelveLoc: Špatná, dobrá nebo střední označuje kvalitu umístění regálů
-
Věk: věková úroveň obyvatelstva
-
Vzdělání: úroveň vzdělání v místě
-
Městské: Ano/Ne
-
US: Ano/Ne
names(carseats)Podívejme se na histogram prodejů automobilů:
hist(carseats$Sales)Všimněte si, že Sales je kvantitativní proměnná. Chcete ji demonstrovat pomocí stromů s binární odpovědí. Za tímto účelem změníte Sales na binární proměnnou, která se bude jmenovat High. Pokud je prodej menší než 8, nebude vysoký. V opačném případě bude vysoká. Pak můžete tuto novou proměnnou High vložit zpět do datového rámce.
High = ifelse(carseats$Sales<=8, "No", "Yes")carseats = data.frame(carseats, High)Nyní naplníme model pomocí rozhodovacích stromů. Samozřejmě zde nemůžete mít proměnnou Sales, protože vaše proměnná odpovědi High byla vytvořena z Sales. Vyloučíme ji tedy a dosadíme strom.
tree.carseats = tree(High~.-Sales, data=carseats)Podívejme se na shrnutí vašeho klasifikačního stromu:
summary(tree.carseats)Můžete vidět zapojené proměnné, počet terminálních uzlů, zbytkovou střední odchylku a také chybovost chybné klasifikace. Aby to bylo názornější, vyneseme strom také do grafu a poté jej opatříme poznámkami pomocí šikovné funkce text:
plot(tree.carseats)text(tree.carseats, pretty = 0)Proměnných je mnoho, takže pohled na strom je velmi komplikovaný. Alespoň vidíte, že u každého z koncových uzlů jsou označeny Yes nebo No. U každého uzlu rozdělení jsou zobrazeny proměnné a hodnota volby rozdělení (například Price < 92.5 nebo Advertising < 13.5).
Pro podrobný přehled stromu jej stačí vytisknout. Bude se vám hodit, pokud budete chtít ze stromu vytáhnout podrobnosti pro jiné účely:
tree.carseatsJe čas strom ořezat. Vytvoříme trénovací a testovací sadu rozdělením datového rámce carseats na 250 trénovacích a 150 testovacích vzorků. Nejprve nastavte semeno, aby byly výsledky reprodukovatelné. Poté vyberete náhodný vzorek ID (indexových) čísel vzorků. Konkrétně zde vyberete vzorek z množiny 1 až n řádků počtu řad autosedaček, což je 400. Chcete vzorek o velikosti 250 (ve výchozím nastavení se vzorek používá bez náhrady).
set.seed(101)train=sample(1:nrow(carseats), 250)Takže nyní dostanete tento index train, který indexuje 250 ze 400 pozorování. Můžete znovu sestavit model s tree, přičemž použijete stejný vzorec, jen stromu řeknete, aby použil podmnožinu rovnou train. Poté vytvoříme graf:
tree.carseats = tree(High~.-Sales, carseats, subset=train)plot(tree.carseats)text(tree.carseats, pretty=0)Díky mírně odlišné množině dat vypadá graf trochu jinak. Nicméně složitost stromu vypadá zhruba stejně.
Nyní vezmete tento strom a předpovíte ho na testovací množině pomocí metody predict pro stromy. Zde budete chtít skutečně předpovědět class štítky.
tree.pred = predict(tree.carseats, carseats, type="class")Poté můžete vyhodnotit chybu pomocí tabulky chybné klasifikace.
with(carseats, table(tree.pred, High))Na diagonálách jsou správné klasifikace, zatímco mimo diagonály jsou nesprávné. Chcete překódovat pouze ty správné. K tomu můžete vzít součet dvou diagonál vydělený celkovým počtem (150 testovacích pozorování).
(72 + 43) / 150Ok, s tímto stromem dostanete chybu 0,76.
Při pěstování velkého košatého stromu by mohl mít příliš velký rozptyl. Použijme tedy křížovou validaci k optimálnímu ořezání stromu. Pomocí cv.tree použijeme chybu chybné klasifikace jako základ pro provedení ořezání.
cv.carseats = cv.tree(tree.carseats, FUN = prune.misclass)cv.carseatsVýpis výsledků zobrazí podrobnosti o průběhu křížové validace. Vidíte velikosti stromů, jak byly ořezávány zpět, odchylky, jak ořezávání probíhalo, a také parametr složitosti nákladů použitý v tomto procesu.
Vyneseme to do grafu:
plot(cv.carseats)Při pohledu na graf vidíte klesající část spirály kvůli chybě klasifikace na 250 křížově validovaných bodech. Zvolme tedy hodnotu v sestupných krocích (12). Poté ořežme strom na velikost 12, abychom tento strom identifikovali. Nakonec tento strom vykreslíme a opatříme poznámkami, abychom viděli výsledek.
prune.carseats = prune.misclass(tree.carseats, best = 12)plot(prune.carseats)text(prune.carseats, pretty=0)Je o něco mělčí než předchozí stromy a můžete si skutečně přečíst popisky. Vyhodnoťme jej znovu na testovací sadě dat.
tree.pred = predict(prune.carseats, carseats, type="class")with(carseats, table(tree.pred, High))(74 + 39) / 150Vypadá to, že správných klasifikací trochu ubylo. Udělal zhruba totéž co váš původní strom, takže ořezání příliš neublížilo s ohledem na chyby chybné klasifikace a dalo jednodušší strom.
Často se stává, že stromy nedávají příliš dobré chyby predikce, takže se pojďme podívat na náhodné lesy a boosting, které mají tendenci překonávat stromy, co se týče predikce a chybné klasifikace.
Náhodné lesy
V této části budete pomocí Boston housing data zkoumat náhodné lesy a boosting. Datová sada se nachází v balíčku MASS. Uvádí hodnoty bydlení a další statistiky v každém z 506 předměstí Bostonu na základě sčítání lidu z roku 1970.
library(MASS)data(package="MASS")boston<-Bostondim(boston)names(boston)Nahrajeme také balíček randomForest.
require(randomForest)Pro přípravu dat pro náhodný les nastavíme semeno a vytvoříme ukázkovou trénovací množinu o 300 pozorováních.
set.seed(101)train = sample(1:nrow(boston), 300)V této datové sadě je 506 předměstí Bostonu. Pro každý surburb máte proměnné, jako je kriminalita na obyvatele, typy průmyslu, průměrné # místností na byt, průměrný podíl stáří domů atd. Jako proměnnou odezvy použijme medv – průměrnou hodnotu obydlených domů vlastníky pro každý z těchto surburbs.
Připravme náhodný les a podívejme se, jak dobře funguje. Jak již bylo řečeno, použijete odpověď medv, mediánovou hodnotu bydlení (v dolarech 1 000 USD) a soubor trénovacích vzorků.
rf.boston = randomForest(medv~., data = boston, subset = train)rf.bostonVytisknutím náhodného lesa získáte jeho shrnutí: # stromů (vyrostlo jich 500), střední kvadratická rezidua (MSR) a procento vysvětleného rozptylu. MSR a % vysvětleného rozptylu jsou založeny na odhadech z pytle, což je v náhodných lesích velmi chytré zařízení pro získání poctivých odhadů chyb.
Jediným ladicím parametrem v náhodném lese je argument nazvaný mtry, což je počet proměnných, které jsou vybrány při každém rozdělení každého stromu, když provedete rozdělení. Jak je vidět zde, mtry jsou 4 z 13 zkoumaných proměnných (kromě medv) v datech Boston Housing – to znamená, že pokaždé, když strom přijde k rozdělení uzlu, budou náhodně vybrány 4 proměnné, pak se rozdělení omezí na 1 z těchto 4 proměnných. Takto randomForests odkoriguje stromy.
Přistoupíte k fitování řady náhodných lesů. Proměnných je 13, takže nechť se mtry pohybuje v rozmezí od 1 do 13:
-
Pro zaznamenání chyb nastavíte 2 proměnné
oob.erratest.err. -
V cyklu
mtryod 1 do 13 nejprve napasujeterandomForests touto hodnotoumtryna datovou sadutrain, čímž omezíte počet stromů na 350. -
Na základě toho, že se
mtrypohybuje v rozmezí od 1 do 13, napasujeterandomForestna datovou sadutrain. -
Poté získáte střední kvadratickou chybu na objektu (chyba mimo soubor).
-
Poté předpovídáte na testovacím souboru dat (
boston) pomocífit(fitrandomForest). -
Nakonec vypočtete chybu testu: střední kvadratickou chybu, která se rovná
mean( (medv - pred) ^ 2 ).
oob.err = double(13)test.err = double(13)for(mtry in 1:13){ fit = randomForest(medv~., data = boston, subset=train, mtry=mtry, ntree = 350) oob.err = fit$mse pred = predict(fit, boston) test.err = with(boston, mean( (medv-pred)^2 ))}V podstatě jste právě vypěstovali 4550 stromů (13 krát 350). Nyní vytvoříme graf pomocí příkazu matplot. Chybu testu a chybu mimo pytel spojíme dohromady a vytvoříme dvousloupcovou matici. V matici je několik dalších argumentů, včetně hodnot vykreslovacích znaků (pch = 23 znamená vyplněný kosočtverec), barev (červená a modrá), typu rovná se obě (vykreslení obou bodů a jejich spojení čarami) a názvu osy y (Mean Squared Error). Do pravého horního rohu grafu můžete také umístit legendu.
matplot(1:mtry, cbind(test.err, oob.err), pch = 23, col = c("red", "blue"), type = "b", ylab="Mean Squared Error")legend("topright", legend = c("OOB", "Test"), pch = 23, col = c("red", "blue"))V podstatě by se tyto dvě křivky měly srovnat, ale zdá se, že chyba testu je o něco nižší. V těchto odhadech testovací chyby je však velká variabilita. Vzhledem k tomu, že odhad chyby mimo soubor byl vypočten na jednom souboru dat a odhad chyby testu byl vypočten na jiném souboru dat, jsou tyto rozdíly do značné míry v rámci standardních chyb.
Všimli jste si, že červená křivka je plynule nad modrou křivkou? Tyto odhady chyb jsou velmi korelované, protože randomForest s mtry = 4 je velmi podobný odhadu s mtry = 5. Proto je každá z křivek poměrně hladká. Vidíte, že mtry kolem 4 se zdá být nejoptimálnější volbou, alespoň pro chybu testu. Tato hodnota mtry pro chybu mimo sáček se rovná 9.
Takže s velmi malým počtem úrovní jste vybavili velmi výkonný predikční model pomocí náhodných lesů. Jak je to možné? Levá strana ukazuje výkonnost jediného stromu. Střední kvadratická chyba out-of-bag je 26 a vy jste klesli na přibližně 15 (jen o něco málo nad polovinu). To znamená, že jste chybu snížili na polovinu. Stejně tak u chyby testu jste chybu snížili z 20 na 12.
Boosting
V porovnání s náhodnými lesy roste boosting menší a strnulejší stromy a jde na zkreslení. Použijete balíček GBM (Gradient Boosted Modeling), v R.
require(gbm)GBM se ptá na rozdělení, které je Gaussovo, protože budete dělat kvadratickou ztrátu chyby. Budete žádat GBM o 10 000 stromů, což zní jako hodně, ale budou to mělké stromy. Hloubka interakce je počet rozdělení, takže chcete 4 rozdělení v každém stromu. Smrštění je 0,01, což je hodnota, o kolik budete zmenšovat krok stromu zpět.
boost.boston = gbm(medv~., data = boston, distribution = "gaussian", n.trees = 10000, shrinkage = 0.01, interaction.depth = 4)summary(boost.boston)Funkce summary poskytuje graf proměnné důležitosti. Zdá se, že existují 2 proměnné, které mají vysokou relativní důležitost: rm (počet místností) a lstat (procento lidí s nižším ekonomickým statusem v obci). Vyneseme tyto 2 proměnné do grafu:
plot(boost.boston,i="lstat")plot(boost.boston,i="rm")1. graf ukazuje, že čím vyšší je podíl lidí s nižším ekonomickým statusem v obci, tím nižší je hodnota ceny bydlení. 2. graf ukazuje obrácený vztah s počtem místností: průměrný počet místností v domě se zvyšuje s rostoucí cenou.
Nastal čas předpovědět posílený model na testovacím souboru dat. Podívejme se na výkonnost testu v závislosti na počtu stromů:
-
Nejprve vytvoříte mřížku počtu stromů v krocích po 100 od 100 do 10 000.
-
Poté spustíte funkci
predictna boostovaném modelu. Jako argument přijmen.treesa vytvoří matici predikcí na testovacích datech. -
Rozměry matice jsou 206 testovacích pozorování a 100 různých predikčních vektorů při 100 různých hodnotách stromů.
n.trees = seq(from = 100, to = 10000, by = 100)predmat = predict(boost.boston, newdata = boston, n.trees = n.trees)dim(predmat)
Je čas vypočítat chybu testu pro každý z predikčních vektorů:
-
predmatje matice,medvje vektor, tedy (predmat–medv) je matice rozdílů. Na sloupce těchto čtvercových rozdílů (průměr) můžete použít funkciapply. Tím byste vypočítali sloupcovou střední kvadratickou chybu pro predikované vektory. -
Poté vytvoříte graf s použitím podobných parametrů, jaké se používají pro Random Forest. Zobrazil by se graf chyby zesílení.
boost.err = with(boston, apply( (predmat - medv)^2, 2, mean) )plot(n.trees, boost.err, pch = 23, ylab = "Mean Squared Error", xlab = "# Trees", main = "Boosting Test Error")abline(h = min(test.err), col = "red")
S rostoucím počtem stromů chyba zesílení pěkně klesá. To je důkaz, který ukazuje, že boosting se zdráhá nadměrně přizpůsobovat. Do grafu zahrňme také nejlepší testovací chybu z randomForest. Boosting se skutečně dostává o rozumnou částku pod testovací chybu pro randomForest.
Závěr
Takže to je konec tohoto R tutoriálu o sestavování modelů rozhodovacích stromů: klasifikační stromy, náhodné lesy a boostované stromy. Poslední 2 jmenované jsou výkonné metody, které můžete použít kdykoli podle potřeby. Podle mých zkušeností boosting obvykle předčí RandomForest, ale RandomForest je jednodušší na implementaci. V případě RandomForest je jediným ladicím parametrem počet stromů, zatímco v případě boostingu je kromě počtu stromů vyžadováno více ladicích parametrů, včetně smrštění a hloubky interakce.
Pokud se chcete dozvědět více, určitě se podívejte na náš kurz Machine Learning Toolbox for R.