Indledning
Det er afgørende at forstå kundeadfærd i enhver branche. Jeg indså dette sidste år, da min marketingchef spurgte mig – “Kan du fortælle mig, hvilke eksisterende kunder vi skal målrette til vores nye produkt?”
Det var noget af en læringskurve for mig. Jeg indså hurtigt som datalog, hvor vigtigt det er at segmentere kunderne, så min organisation kan skræddersy og opbygge målrettede strategier. Det er her, at begrebet clustering kom meget belejligt!
Problemer som segmentering af kunder er ofte bedragerisk vanskelige, fordi vi ikke arbejder med nogen målvariabel i tankerne. Vi befinder os officielt i landet for uovervåget læring, hvor vi skal finde frem til mønstre og strukturer uden at have et bestemt resultat i tankerne. Det er både udfordrende og spændende som datalog.
Nu er der et par forskellige måder at udføre clustering på (som du vil se nedenfor). Jeg vil introducere dig til en af disse typer i denne artikel – hierarkisk clustering.
Vi vil lære, hvad hierarkisk clustering er, dens fordel i forhold til de andre clustering-algoritmer, de forskellige typer af hierarkisk clustering og trinene til at udføre den. Vi vil endelig tage et datasæt til kundesegmentering op og derefter implementere hierarkisk clustering i Python. Jeg elsker denne teknik, og jeg er sikker på, at du også vil gøre det efter denne artikel!
Note: Som nævnt er der flere måder at udføre clustering på. Jeg opfordrer dig til at tjekke vores fantastiske guide til de forskellige typer af clustering:
- An Introduction to Clustering and different methods of clustering
For at lære mere om clustering og andre maskinlæringsalgoritmer (både overvåget og uovervåget) kan du tjekke følgende omfattende program-
- Certified AI & ML Blackbelt+ Program
Indholdsfortegnelse
- Supervised vs Unsupervised Learning
- Why Hierarchical Clustering?
- Hvad er hierarkisk clustering?
- Typer af hierarkisk clustering
- Agglomerativ hierarkisk clustering
- Divisiv hierarkisk clustering
- Stræk til at udføre hierarkisk clustering
- Hvordan vælger man antallet af klynger i hierarkisk clustering?
- Løsning af et problem med segmentering af engroskunder ved hjælp af hierarkisk clustering
Supervised vs Unsupervised Learning
Det er vigtigt at forstå forskellen mellem supervised og unsupervised learningunsupervised learning, før vi dykker ned i hierarkisk clustering. Lad mig forklare denne forskel ved hjælp af et enkelt eksempel.
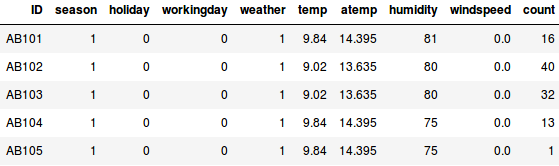
Sæt, at vi ønsker at estimere antallet af cykler, der vil blive udlejet i en by hver dag:
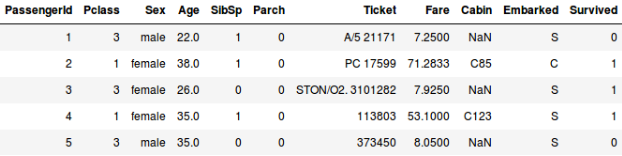
Og lad os sige, at vi ønsker at forudsige, om en person om bord på Titanic overlevede eller ej:
Vi har et fast mål at nå i begge disse eksempler:
- I det første eksempel skal vi forudsige antallet af cykler baseret på funktioner som sæson, ferie, arbejdsdag, vejr, temperatur osv.
- I det andet eksempel skal vi forudsige, om en passager har overlevet eller ej. I variablen “Overlevede” repræsenterer 0, at personen ikke overlevede, og 1 betyder, at personen slap ud i live. De uafhængige variabler her omfatter Pclass, køn, alder, billetpris osv.
Så når vi får en målvariabel (antal og Overlevelse i de to ovenstående tilfælde), som vi skal forudsige på baggrund af et givet sæt af prædiktorer eller uafhængige variabler (sæson, ferie, køn, alder osv.), kaldes sådanne problemer for superviserede indlæringsproblemer.
Lad os se på nedenstående figur for at forstå dette visuelt:
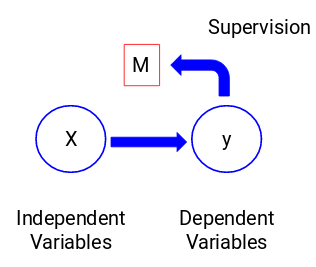
Her er y vores afhængige eller målvariabel, og X repræsenterer de uafhængige variabler. Målvariablen er afhængig af X, og derfor kaldes den også en afhængig variabel. Vi træner vores model ved hjælp af de uafhængige variabler i overvågningen af målvariablen og deraf navnet supervised learning.
Vores mål, når vi træner modellen, er at generere en funktion, der kortlægger de uafhængige variabler til den ønskede målvariabel. Når modellen er trænet, kan vi videregive nye sæt af observationer, og modellen vil forudsige målet for dem. Dette er kort fortalt supervised learning.
Der kan være situationer, hvor vi ikke har nogen målvariabel at forudsige. Sådanne problemer, uden nogen eksplicit målvariabel, kaldes uovervågede indlæringsproblemer. Vi har kun de uafhængige variabler og ingen mål/afhængige variabler i disse problemer.

Vi forsøger i disse tilfælde at opdele hele dataene i et sæt af grupper. Disse grupper er kendt som klynger, og processen med at lave disse klynger er kendt som klyngedannelse.
Denne teknik anvendes generelt til klyngedannelse af en population i forskellige grupper. Nogle få almindelige eksempler omfatter segmentering af kunder, klynge lignende dokumenter sammen, anbefaling af lignende sange eller film osv.
Der er MANGE andre anvendelser af uovervåget læring. Hvis du støder på en interessant anvendelse, er du velkommen til at dele dem i kommentarfeltet nedenfor!
Nu er der forskellige algoritmer, der hjælper os med at lave disse klynger. De mest almindeligt anvendte clustering-algoritmer er K-means og hierarkisk clustering.
Hvorfor hierarkisk clustering?
Vi bør først vide, hvordan K-means fungerer, før vi dykker ned i hierarkisk clustering. Tro mig, det vil gøre begrebet hierarkisk clustering så meget desto nemmere.
Her er en kort oversigt over, hvordan K-means fungerer:
- Beslut antallet af klynger (k)
- Vælg k tilfældige punkter fra dataene som centroider
- Tildel alle punkterne til den nærmeste klyngecentroid
- Beregn centroid for de nyligt dannede klynger
- Gentag trin 3 og 4
Det er en iterativ proces. Den bliver ved med at køre, indtil centroiderne af de nyligt dannede klynger ikke ændres, eller det maksimale antal iterationer er nået.
Men der er visse udfordringer med K-means. Den forsøger altid at lave klynger af samme størrelse. Desuden skal vi beslutte antallet af klynger i begyndelsen af algoritmen. Ideelt set ville vi ikke vide, hvor mange klynger vi skal have i begyndelsen af algoritmen, og derfor er det en udfordring med K-means.
Dette er en kløft hierarkisk clustering overbygger med bravour. Det fjerner problemet med at skulle foruddefinere antallet af klynger. Lyder som en drøm! Så lad os se, hvad hierarkisk clustering er, og hvordan den forbedrer K-means.
Hvad er hierarkisk clustering?
Lad os sige, at vi har nedenstående punkter, og at vi ønsker at klynge dem i grupper:

Vi kan tildele hvert af disse punkter til en separat klynge:

Nu kan vi, baseret på ligheden mellem disse klynger, kombinere de mest ens klynger sammen og gentage denne proces, indtil der kun er en enkelt klynge tilbage:
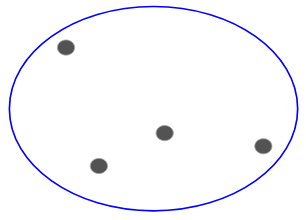
Vi opbygger i bund og grund et hierarki af klynger. Det er derfor, at denne algoritme kaldes hierarkisk clustering. Jeg vil diskutere, hvordan man bestemmer antallet af klynger i et senere afsnit. Lad os nu se på de forskellige typer af hierarkisk clustering.
Typer af hierarkisk clustering
Der findes hovedsageligt to typer af hierarkisk clustering:
- Agglomerativ hierarkisk clustering
- Divisiv hierarkisk clustering
Lad os forstå hver type i detaljer.
Agglomerativ hierarkisk klyngedannelse
Vi tildeler hvert punkt til en individuel klynge i denne teknik. Lad os antage, at der er 4 datapunkter. Vi tildeler hvert af disse punkter til en klynge og vil derfor have 4 klynger i begyndelsen:
Så sammenlægger vi ved hver iteration det nærmeste par klynger og gentager dette trin, indtil der kun er en enkelt klynge tilbage:
Vi sammenlægger (eller tilføjer) klyngerne ved hvert trin, ikke sandt? Derfor er denne type clustering også kendt som additiv hierarkisk clustering.
Divisiv hierarkisk clustering
Divisiv hierarkisk clustering fungerer på den modsatte måde. I stedet for at starte med n klynger (i tilfælde af n observationer), starter vi med en enkelt klynge og tildeler alle punkterne til denne klynge.
Så det er ligegyldigt, om vi har 10 eller 1000 datapunkter. Alle disse punkter vil tilhøre den samme klynge i begyndelsen:
Nu deler vi ved hver iteration det fjerneste punkt i klyngen og gentager denne proces, indtil hver klynge kun indeholder et enkelt punkt:
Vi deler (eller opdeler) klyngerne ved hvert trin, deraf navnet divisive hierarchical clustering.
Agglomerative Clustering er meget anvendt i industrien, og det vil være fokus i denne artikel. Divisive hierarchical clustering vil være et stykke kage, når vi først har styr på den agglomerative type.
Stræk til udførelse af hierarkisk clustering
Vi sammenlægger de mest ens punkter eller klynger i hierarkisk clustering – det ved vi godt. Nu er spørgsmålet så – hvordan beslutter vi, hvilke punkter der ligner hinanden, og hvilke der ikke gør det? Det er et af de vigtigste spørgsmål inden for clustering!
Her er en måde at beregne ligheden på – Tag afstanden mellem centroiderne af disse klynger. De punkter, der har den mindste afstand, betegnes som lignende punkter, og vi kan slå dem sammen. Vi kan også henvise til dette som en afstandsbaseret algoritme (da vi beregner afstandene mellem klyngerne).
I hierarkisk clustering har vi et begreb, der kaldes en nærhedsmatrix. Dette gemmer afstandene mellem de enkelte punkter. Lad os tage et eksempel for at forstå denne matrix samt trinene til at udføre hierarkisk clustering.
Sæt eksemplet op

Sæt, at en lærer ønsker at opdele sine elever i forskellige grupper. Hun har de karakterer, som hver enkelt elev har scoret i en opgave, og på baggrund af disse karakterer ønsker hun at opdele dem i grupper. Der er ikke noget fast mål her for, hvor mange grupper der skal være. Da læreren ikke ved, hvilken type elever der skal inddeles i hvilken gruppe, kan det ikke løses som et problem med overvåget læring. Så vi vil forsøge at anvende hierarkisk clustering her og segmentere eleverne i forskellige grupper.
Lad os tage en stikprøve på 5 elever:
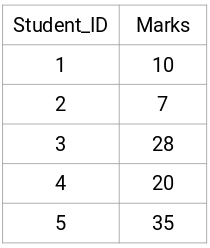
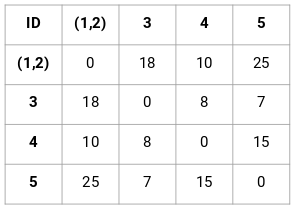
Skabelse af en nærhedsmatrix
Først vil vi skabe en nærhedsmatrix, som vil fortælle os afstanden mellem hvert af disse punkter. Da vi beregner afstanden mellem hvert punkt og hvert af de andre punkter, vil vi få en kvadratisk matrix af formen n X n (hvor n er antallet af observationer).
Lad os lave en 5 x 5 nærhedsmatrix for vores eksempel:
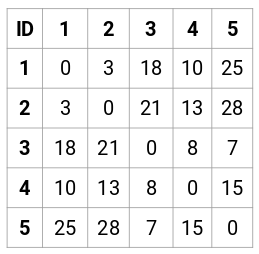
De diagonale elementer i denne matrix vil altid være 0, da afstanden mellem et punkt og sig selv altid er 0. Vi vil bruge den euklidiske afstandsformel til at beregne resten af afstandene. Så lad os sige, at vi ønsker at beregne afstanden mellem punkt 1 og 2:
√(10-7)^2 = √9 = 3
Sådan kan vi beregne alle afstandene og udfylde nærhedsmatricen.
Stræk til udførelse af hierarkisk clustering
Stræk 1: Først tildeler vi alle punkterne til en individuel klynge:
![]()
Differente farver repræsenterer her forskellige klynger. Du kan se, at vi har 5 forskellige klynger for de 5 punkter i vores data.
Stræk 2: Dernæst kigger vi på den mindste afstand i nærhedsmatricen og fletter punkterne med den mindste afstand sammen. Derefter opdaterer vi nærhedsmatricen:
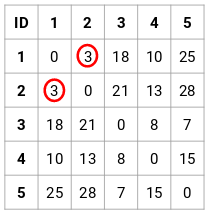
Her er den mindste afstand 3, og derfor vil vi slå punkt 1 og 2 sammen:
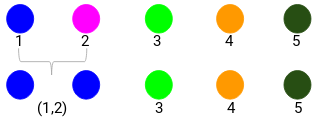
Lad os se på de opdaterede klynger og tilsvarende opdatere nærhedsmatricen:
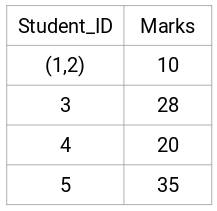
Her har vi taget det maksimale af de to mærker (7, 10) for at erstatte mærkerne for denne klynge. I stedet for maksimum kan vi også tage minimumsværdien eller gennemsnitsværdierne. Nu vil vi igen beregne nærhedsmatricen for disse klynger:
Strin 3: Vi gentager trin 2, indtil der kun er en enkelt klynge tilbage.
Så vi vil først se på den mindste afstand i nærhedsmatricen og derefter slå det nærmeste par klynger sammen. Vi får de sammenlagte klynger som vist nedenfor efter gentagelse af disse trin:
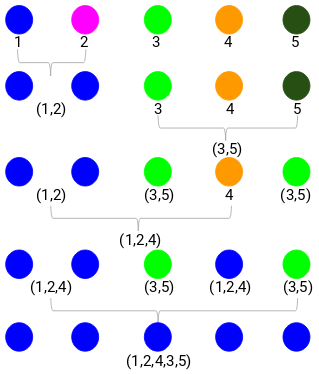
Vi startede med 5 klynger og har til sidst en enkelt klynge. Sådan fungerer agglomerativ hierarkisk klyngedannelse. Men det brændende spørgsmål er stadig tilbage – hvordan bestemmer vi antallet af klynger? Lad os forstå det i næste afsnit.
Hvordan skal vi vælge antallet af klynger i hierarkisk clustering?
Er du klar til endelig at besvare dette spørgsmål, der har hængt rundt omkring, siden vi begyndte at lære? For at få antallet af klynger til hierarkisk clustering gør vi brug af et fantastisk koncept kaldet et Dendrogram.
Et dendrogram er et trælignende diagram, der registrerer sekvenserne af sammenlægninger eller opdelinger.
Lad os vende tilbage til vores lærer-elev-eksempel. Hver gang vi sammenlægger to klynger, vil et dendrogram registrere afstanden mellem disse klynger og repræsentere den i diagramform. Lad os se, hvordan et dendrogram ser ud:
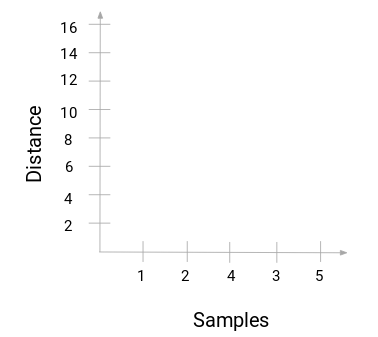
Vi har prøverne i datasættet på x-aksen og afstanden på y-aksen. Når to klynger slås sammen, vil vi sammenføje dem i dette dendrogram, og højden af sammenføjningen vil være afstanden mellem disse punkter. Lad os opbygge dendrogrammet for vores eksempel:
Tag et øjeblik til at behandle ovenstående billede. Vi startede med at slå prøve 1 og 2 sammen, og afstanden mellem disse to prøver var 3 (se den første nærhedsmatrix i det foregående afsnit). Lad os plotte dette i dendrogrammet:
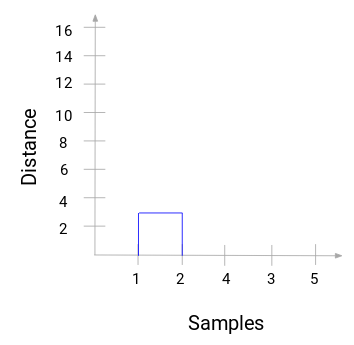
Her kan vi se, at vi har slået prøve 1 og 2 sammen. Den lodrette linje repræsenterer afstanden mellem disse prøver. På samme måde plotter vi alle de trin, hvor vi har slået klyngerne sammen, og til sidst får vi et dendrogram som dette:
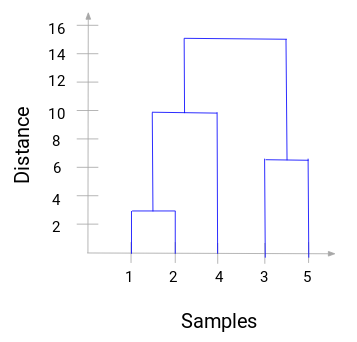
Vi kan tydeligt visualisere trinene i den hierarkiske klyngedannelse. Jo større afstanden mellem de lodrette linjer i dendrogrammet er, desto større er afstanden mellem disse klynger.
Nu kan vi indstille en tærskelafstand og tegne en vandret linje (generelt forsøger vi at indstille tærsklen på en sådan måde, at den skærer den højeste lodrette linje). Lad os sætte denne tærskelværdi til 12 og tegne en vandret linje:
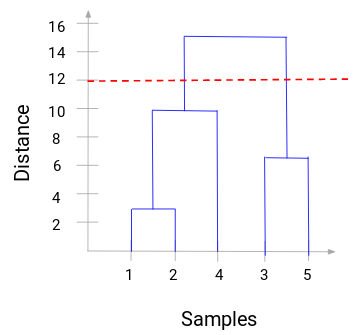
Antallet af klynger vil være antallet af lodrette linjer, som bliver skåret af den linje, der er tegnet ved hjælp af tærskelværdien. I ovenstående eksempel vil vi have 2 klynger, da den røde linje skærer 2 lodrette linjer, da den røde linje skærer 2 lodrette linjer. Den ene klynge vil have en prøve (1,2,4) og den anden vil have en prøve (3,5). Ret ligetil, ikke sandt?
Sådan kan vi bestemme antallet af klynger ved hjælp af et dendrogram i hierarkisk klyngedannelse. I næste afsnit vil vi implementere hierarkisk clustering, som vil hjælpe dig med at forstå alle de begreber, som vi har lært i denne artikel.
Løsning af problemet med segmentering af engroskunder ved hjælp af hierarkisk clustering
Det er tid til at få hænderne beskidte i Python!
Vi vil arbejde på et problem med segmentering af engroskunder. Du kan downloade datasættet ved hjælp af dette link. Dataene er hostet på UCI Machine Learning repository. Formålet med dette problem er at segmentere kunderne hos en engrosforhandler på grundlag af deres årlige udgifter til forskellige produktkategorier, såsom mælk, dagligvarer, region osv.
Lad os først udforske dataene og derefter anvende hierarkisk clustering til at segmentere kunderne.
Vi vil først importere de nødvendige biblioteker:
Lad dataene, og se på de første par rækker:
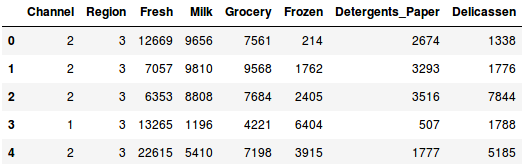
Der er flere produktkategorier – frisk, mælk, dagligvarer osv. Værdierne repræsenterer det antal enheder, der er købt af hver kunde for hvert produkt. Vores mål er at lave klynger ud fra disse data, som kan segmentere lignende kunder sammen. Vi vil naturligvis bruge Hierarchical Clustering til dette problem.
Men før vi anvender Hierarchical Clustering, skal vi normalisere dataene, så skalaen for hver variabel er den samme. Hvorfor er dette vigtigt? Jo, hvis skalaen for variablerne ikke er den samme, kan modellen blive skævvredet i retning af variabler med en højere størrelse som f.eks. frisk eller mælk (se ovenstående tabel).
Så lad os først normalisere dataene og bringe alle variablerne til den samme skala:
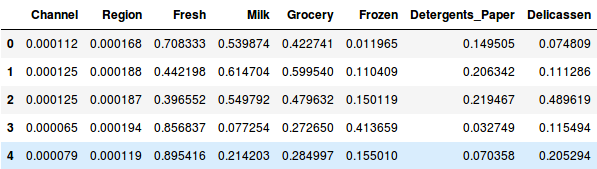
Her kan vi se, at skalaen for alle variablerne er næsten ens. Nu er vi klar til at gå i gang. Lad os først tegne dendrogrammet for at hjælpe os med at beslutte antallet af klynger for dette særlige problem:
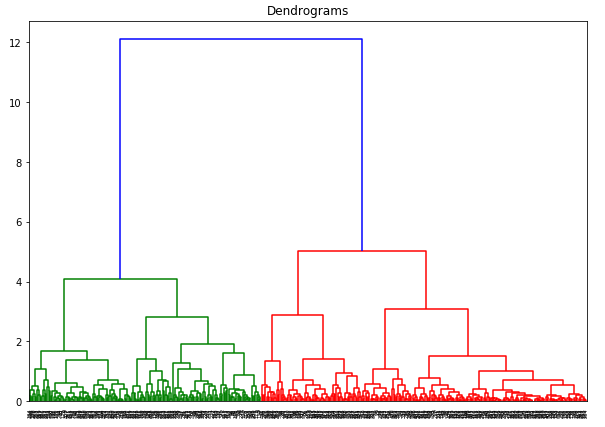
X-aksen indeholder prøverne, og y-aksen repræsenterer afstanden mellem disse prøver. Den lodrette linje med den maksimale afstand er den blå linje, og derfor kan vi beslutte en tærskelværdi på 6 og skære dendrogrammet:
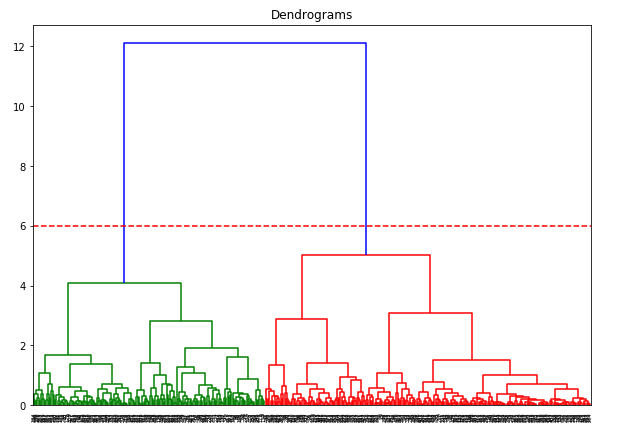
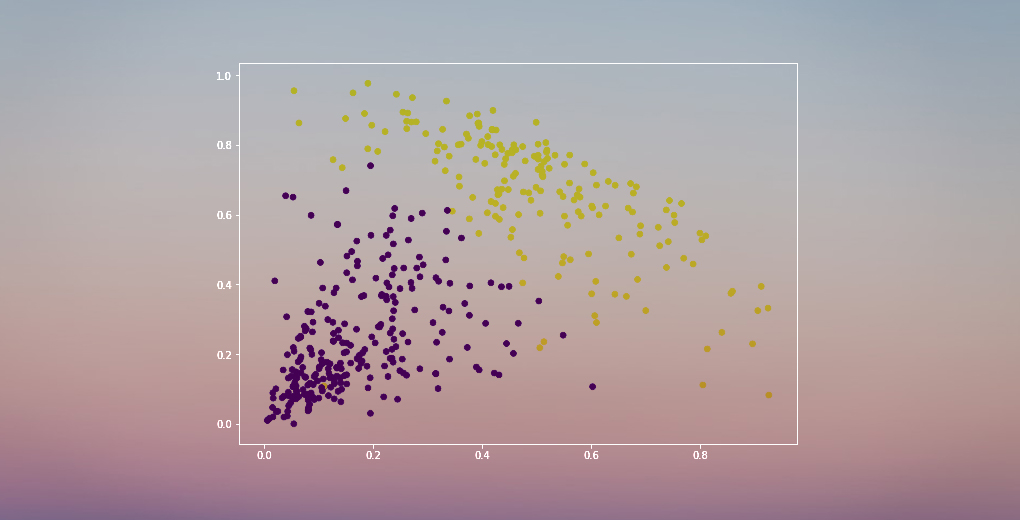
Vi har to klynger, da denne linje skærer dendrogrammet i to punkter. Lad os nu anvende hierarkisk clustering for 2 klynger:
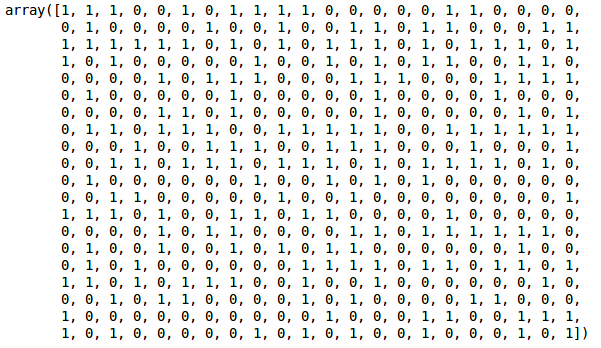
Vi kan se værdierne af 0’er og 1’er i output, da vi har defineret 2 klynger. 0 repræsenterer de punkter, der hører til den første klynge, og 1 repræsenterer punkter i den anden klynge. Lad os nu visualisere de to klynger:
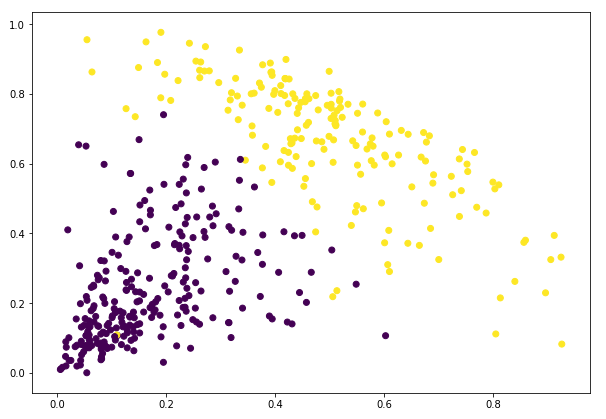
Awesome! Vi kan tydeligt visualisere de to klynger her. Sådan kan vi implementere hierarkisk clustering i Python.
Slutnoter
Hierarkisk clustering er en superbrugelig måde at segmentere observationer på. Fordelen ved ikke at skulle foruddefinere antallet af klynger giver den en ganske god fordel i forhold til k-Means.
Hvis du stadig er relativt ny inden for datalogi, kan jeg varmt anbefale at tage kurset Applied Machine Learning. Det er et af de mest omfattende end-to-end maskinlæringskurser, du kan finde nogen steder. Hierarkisk clustering er blot et af en række forskellige emner, som vi dækker på kurset.