Esittely
Asiakkaiden käyttäytymisen ymmärtäminen on ratkaisevan tärkeää millä tahansa alalla. Tajusin tämän viime vuonna, kun markkinointipäällikköni kysyi minulta – ”Voitko kertoa minulle, mihin nykyisiin asiakkaisiin meidän pitäisi kohdistaa uusi tuotteemme?”
Se oli minulle melkoinen oppimiskäyrä. Tajusin nopeasti datatieteilijänä, kuinka tärkeää on segmentoida asiakkaita, jotta organisaationi voi räätälöidä ja rakentaa kohdennettuja strategioita. Tässä kohtaa klusteroinnin käsite tuli erittäin tarpeeseen!
Asiakkaiden segmentoinnin kaltaiset ongelmat ovat usein petollisen hankalia, koska emme työskentele mitään tavoitemuuttujaa mielessä. Olemme virallisesti valvomattoman oppimisen maassa, jossa meidän on selvitettävä kuvioita ja rakenteita ilman tiettyä lopputulosta mielessä. Se on sekä haastavaa että jännittävää datatieteilijänä.
Nyt on olemassa muutamia eri tapoja suorittaa klusterointi (kuten näet jäljempänä). Tässä artikkelissa esittelen sinulle yhden tällaisen tyypin – hierarkkisen klusteroinnin.
Olemme oppineet, mitä hierarkkinen klusterointi on, sen edut muihin klusterointialgoritmeihin verrattuna, hierarkkisen klusteroinnin eri tyypit ja vaiheet sen suorittamiseksi. Lopuksi otamme käyttöön asiakassegmentointitietokannan ja toteutamme hierarkkisen klusteroinnin Pythonilla. Rakastan tätä tekniikkaa ja olen varma, että sinäkin rakastat sitä tämän artikkelin jälkeen!
Huomautus: Kuten mainittiin, klusterointi voidaan suorittaa monella eri tavalla. Kehotan sinua tutustumaan mahtavaan oppaaseemme eri klusterointityypeistä:
- An Introduction to Clustering and different methods of clustering
Jos haluat oppia lisää klusteroinnista ja muista koneoppimisen algoritmeista (sekä valvotuista että valvomattomista), tutustu seuraavaan kattavaan ohjelmaan-
- Certified AI & ML Blackbelt+ Program
Sisällysluettelo
- Valvottu vs. valvomaton oppiminen
- Miksi hierarkkinen klusterointi?
- Mitä on hierarkkinen klusterointi?
- Hierarkkisen klusteroinnin tyypit
- Agglomeratiivinen hierarkkinen klusterointi
- Divissiivinen hierarkkinen klusterointi
- Vaiheet hierarkkisen klusteroinnin suorittamiseen
- Miten klustereiden määrä valitaan hierarkkisessa klusteroinnissa?
- Tukkukaupan asiakassegmentointiongelman ratkaiseminen hierarkkisen klusteroinnin avulla
Valvottu vs. valvomaton oppiminen
On tärkeää ymmärtää valvotun ja valvomattoman oppimisen eroValvomattoman oppimisen ero ennen kuin sukellamme hierarkkiseen klusterointiin. Selitän tämän eron yksinkertaisen esimerkin avulla.
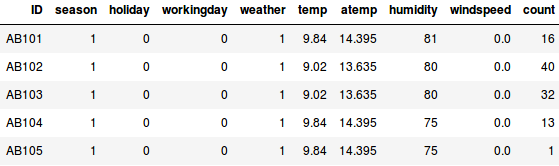
Asettakaamme, että haluamme arvioida kaupungissa päivittäin vuokrattavien polkupyörien lukumäärän:
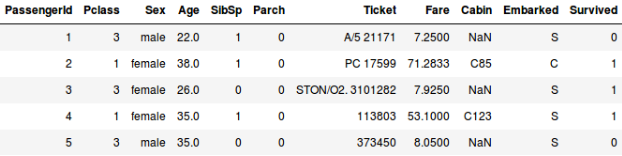
Tai sanotaan, että haluamme ennustaa, jäikö Titanicin kyydissä ollut henkilö henkiin vai ei:
Meillä on molemmissa esimerkeissä kiinteä tavoite, joka on saavutettava:
- Ensimmäisessä esimerkissä meidän on ennustettava polkupyörien lukumäärää sellaisten ominaisuuksien perusteella kuin vuodenaika, loma, työpäivä, sää, lämpötila jne.
- Tässä toisessa esimerkissä ennustetaan, onko matkustaja selvinnyt hengissä vai ei. Muuttujassa ’Survived’ 0 tarkoittaa, että henkilö ei selvinnyt hengissä ja 1 tarkoittaa, että henkilö selvisi hengissä. Riippumattomia muuttujia ovat tässä Pclass, Sex, Age, Fare jne.
Kun meille siis annetaan tavoitemuuttuja (count ja Survival kahdessa edellä mainitussa tapauksessa), joka meidän on ennustettava tietyn joukon ennusteiden tai riippumattomien muuttujien perusteella (kausi, loma, sukupuoli, ikä jne.), tällaisia ongelmia kutsutaan valvotun oppimisen ongelmiksi.
Katsotaanpa alla olevaa kuviota, jotta ymmärrämme tämän visuaalisesti:
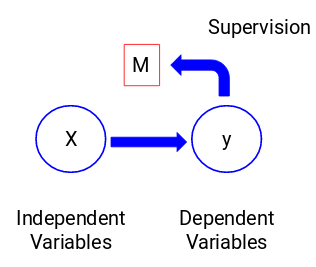
Tässä y on riippuvainen tai tavoitemuuttujamme, ja X edustaa riippumattomia muuttujia. Tavoitemuuttuja on riippuvainen X:stä ja siksi sitä kutsutaan myös riippuvaksi muuttujaksi. Koulutamme malliamme käyttämällä riippumattomia muuttujia kohdemuuttujan valvonnassa ja tästä johtuu nimi valvottu oppiminen.
Mallia koulutettaessa tavoitteenamme on tuottaa funktio, joka kuvaa riippumattomat muuttujat haluttuun kohteeseen. Kun malli on koulutettu, voimme välittää uusia havaintosarjoja ja malli ennustaa niille kohteen. Tämä on lyhyesti sanottuna valvottua oppimista.
Voi olla tilanteita, joissa meillä ei ole mitään ennustettavaa kohdemuuttujaa. Tällaisia ongelmia, joissa ei ole nimenomaista kohdemuuttujaa, kutsutaan valvomattomiksi oppimisongelmiksi. Meillä on näissä ongelmissa vain riippumattomat muuttujat eikä kohde-/riippuvaismuuttujaa.

Yritämme näissä tapauksissa jakaa koko aineiston joukoksi ryhmiä. Näitä ryhmiä kutsutaan klustereiksi ja näiden klustereiden tekemistä kutsutaan klusteroinniksi.
Tätä tekniikkaa käytetään yleensä perusjoukon klusterointiin eri ryhmiin. Muutamia yleisiä esimerkkejä ovat asiakkaiden segmentointi, samankaltaisten asiakirjojen klusterointi yhteen, samankaltaisten kappaleiden tai elokuvien suositteleminen jne.
Valvomattoman oppimisen sovelluksia on PALJON enemmän. Jos törmäät johonkin mielenkiintoiseen sovellukseen, voit jakaa ne alla olevissa kommenteissa!
Nyt on olemassa erilaisia algoritmeja, jotka auttavat meitä tekemään näitä klustereita. Yleisimmin käytetyt klusterointialgoritmit ovat K-means ja hierarkkinen klusterointi.
Miksi hierarkkinen klusterointi?
Meidän pitäisi ensin tietää, miten K-means toimii ennen kuin sukellamme hierarkkiseen klusterointiin. Luota minuun, se tekee hierarkkisen klusteroinnin käsitteen entistä helpommaksi.
Tässä on lyhyt katsaus siihen, miten K-means toimii:
- Päättää klusterien lukumäärän (k)
- Valitsee aineistosta k satunnaista pistettä keskipisteiksi
- Asettaa kaikki pisteet keskipisteisiin
- . lähimpään klusterin keskipisteeseen
- Lasketaan vasta muodostettujen klustereiden keskipisteet
- Kertaa vaiheet 3 ja 4
Tämä on iteratiivinen prosessi. Sitä jatketaan, kunnes äskettäin muodostettujen klustereiden keskipisteet eivät muutu tai iteraatioiden enimmäismäärä on saavutettu.
K-means-menetelmään liittyy kuitenkin tiettyjä haasteita. Se pyrkii aina muodostamaan samankokoisia klustereita. Lisäksi klusterien lukumäärä on päätettävä algoritmin alussa. Ihannetapauksessa emme tietäisi, kuinka monta klusteria meillä pitäisi olla, algoritmin alussa ja siksi se on haaste K-meansin kanssa.
Tämä on aukko, jonka hierarkkinen klusteroinnilla kurotaan umpeen. Se poistaa ongelman, joka liittyy klusterien lukumäärän ennalta määrittelyyn. Kuulostaa unelmalta! Katsotaanpa, mitä hierarkkinen klusterointi on ja miten se parantaa K-meansia.
Mitä hierarkkinen klusterointi on?
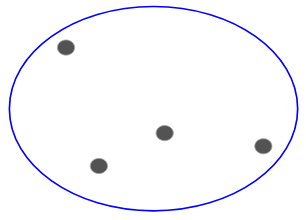
Esitettäköön, että meillä on alla olevat pisteet ja haluamme klusteroida ne ryhmiin:

Voidaan määrittää jokainen näistä pisteistä erilliseen klusteriin:

Nyt voimme näiden klustereiden samankaltaisuuden perusteella yhdistää samankaltaisimmat klusterit yhteen ja toistaa tätä prosessia, kunnes jäljelle jää vain yksi klusteri:
Rakennamme periaatteessa klustereiden hierarkiaa. Siksi tätä algoritmia kutsutaan hierarkkiseksi klusteroinniksi. Käsittelen klusterien lukumäärän päättämistä myöhemmässä kappaleessa. Tarkastellaan nyt hierarkkisen klusteroinnin eri tyyppejä.
Hierarkkisen klusteroinnin tyypit
Hierarkkista klusterointia on pääasiassa kahta tyyppiä:
- Agglomeratiivinen hierarkkinen klusterointi
- Divissiivinen hierarkkinen klusterointi
Ymmärretäänpä kumpaa tahansa tyyppiä tarkemmin.
Agglomeratiivinen hierarkkinen klusterointi
Tässä tekniikassa osoitamme jokaisen pisteen yksittäiseen klusteriin. Oletetaan, että datapisteitä on 4. Määritämme jokaisen näistä pisteistä klusteriin ja näin ollen meillä on alussa 4 klusteria:
Sitten jokaisella iteraatiokerralla yhdistämme lähimmän klusteriparin ja toistamme tämän vaiheen, kunnes jäljelle jää vain yksi klusteri:
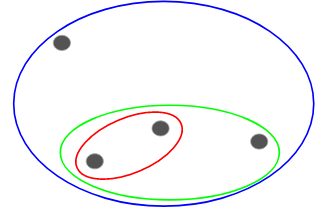
Olemmehan yhdistämässä (tai lisäämässä) klustereita jokaisessa vaiheessa? Näin ollen tämäntyyppinen klusterointi tunnetaan myös nimellä additiivinen hierarkkinen klusterointi.
Divissiivinen hierarkkinen klusterointi
Divissiivinen hierarkkinen klusterointi toimii päinvastoin. Sen sijaan, että aloittaisimme n klusterilla (jos havaintoja on n), aloitamme yhdellä klusterilla ja osoitamme kaikki pisteet tähän klusteriin.
Siten ei ole väliä, onko meillä 10 vai 1000 datapistettä. Kaikki nämä pisteet kuuluvat aluksi samaan klusteriin:
Nyt jokaisella iteraatiokerralla jaamme klusterin kauimmaisen pisteen ja toistamme tämän prosessin, kunnes kussakin klusterissa on vain yksi piste:
Jakaamme (tai jaamme) klusterit jokaisessa vaiheessa, mistä nimitys divisioiva hierarkkinen klusterointi.
Agglomeratiivinen klusterointi on laajalti käytössä teollisuudessa, ja siihen keskitytään tässä artikkelissa. Jakava hierarkkinen klusterointi on lastenleikkiä, kunhan agglomeratiivinen tyyppi on hallussa.
Vaiheet hierarkkisen klusteroinnin suorittamiseksi
Hierarkkisessa klusteroinnissa yhdistetään samankaltaisimmat pisteet tai klusterit – tämän tiedämme. Nyt kysymys kuuluu – miten päätämme, mitkä pisteet ovat samankaltaisia ja mitkä eivät? Se on yksi tärkeimmistä kysymyksistä klusteroinnissa!
Tässä on yksi tapa laskea samankaltaisuus – Otetaan etäisyys näiden klusterien keskipisteiden välillä. Pisteitä, joilla on pienin etäisyys, kutsutaan samankaltaisiksi pisteiksi ja voimme yhdistää ne. Voimme kutsua tätä myös etäisyyteen perustuvaksi algoritmiksi (koska laskemme klusterien väliset etäisyydet).
Hierarkkisessa klusteroinnissa meillä on käsite nimeltä läheisyysmatriisi. Siihen tallennetaan kunkin pisteen väliset etäisyydet. Otetaan esimerkki, jotta ymmärretään tämä matriisi sekä hierarkkisen klusteroinnin suorittamisen vaiheet.
Esimerkin asettaminen

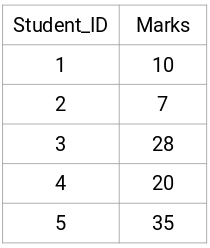
Esitellään, että opettaja haluaa jakaa oppilaansa eri ryhmiin. Hänellä on tiedossaan kunkin opiskelijan tehtävässä saamat arvosanat, ja näiden arvosanojen perusteella hän haluaa jakaa opiskelijat ryhmiin. Tässä ei ole mitään kiinteää tavoitetta sille, kuinka monta ryhmää pitää olla. Koska opettaja ei tiedä, minkälaiset oppilaat pitäisi jakaa mihinkin ryhmään, asiaa ei voida ratkaista valvotun oppimisen ongelmana. Yritämme siis soveltaa tässä hierarkkista klusterointia ja segmentoida opiskelijat eri ryhmiin.
Voidaan ottaa viiden opiskelijan otos:
Läheisyysmatriisin luominen
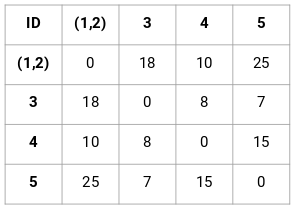
Luotaan ensin läheisyysmatriisi, joka kertoo etäisyyden näiden pisteiden välillä. Koska laskemme kunkin pisteen etäisyyden kustakin muusta pisteestä, saamme neliömatriisin, jonka muoto on n X n (missä n on havaintojen lukumäärä).
Tehdään 5 x 5 läheisyysmatriisi esimerkkiämme varten:
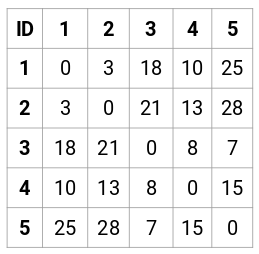
Tämän matriisin diagonaalielementit ovat aina 0, koska pisteen etäisyys itseensä on aina 0. Muiden etäisyyksien laskemiseen käytämme euklidista etäisyyskaavaa. Sanotaan siis, että haluamme laskea pisteen 1 ja 2 välisen etäisyyden:
√(10-7)^2 = √9 = 3
Voidaan vastaavasti laskea kaikki etäisyydet ja täyttää läheisyysmatriisi.
Vaiheet hierarkkisen klusteroinnin suorittamiseksi
Vaihe 1: Määritämme ensin kaikki pisteet yksittäiseen klusteriin:
![]()
Erilaiset värit edustavat tässä eri klustereita. Näet, että meillä on 5 eri klusteria aineistomme 5 pisteelle.
Vaihe 2: Seuraavaksi tarkastelemme pienintä etäisyyttä läheisyysmatriisissa ja yhdistämme ne pisteet, joiden etäisyys on pienin. Tämän jälkeen päivitämme läheisyysmatriisin:
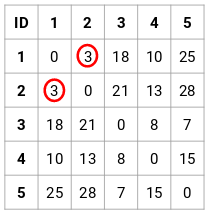
Tässä pienin etäisyys on 3, joten yhdistämme pisteet 1 ja 2:
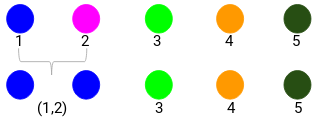
Katsotaan päivitettyjä klustereita ja vastaavasti päivitämme läheisyysmatriisin:
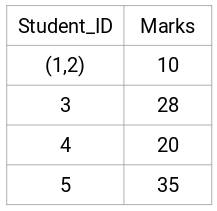
Tässä otimme kahden merkin (7, 10) maksimin korvataksemme merkit tähän klusteriin. Maksimin sijasta voimme ottaa myös minimiarvon tai keskiarvot. Nyt laskemme jälleen läheisyysmatriisin näille klustereille:
Vaihe 3: Toistamme vaihetta 2, kunnes jäljelle jää vain yksi klusteri.
Selvitämme siis ensin pienimmän etäisyyden läheisyysmatriisissa ja yhdistämme sitten lähimmän klusteriparin. Saamme yhdistetyt klusterit alla esitetyllä tavalla, kun olemme toistaneet nämä vaiheet:
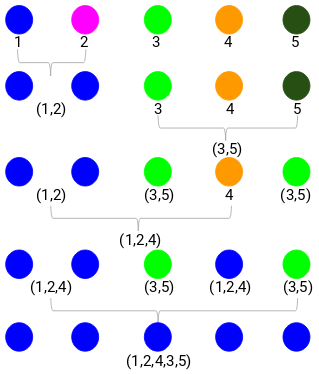
Aloitimme viidestä klusterista, ja lopulta meillä on vain yksi klusteri. Näin agglomeratiivinen hierarkkinen klusterointi toimii. Mutta polttava kysymys on edelleen jäljellä – miten päätämme klusterien määrän? Ymmärrämme sen seuraavassa osiossa.
Miten klusterien määrä valitaan hierarkkisessa klusteroinnissa?
Valmis vihdoin vastaamaan tähän kysymykseen, joka on roikkunut mielessämme siitä asti, kun aloitimme oppimisen? Saadaksemme klusterien lukumäärän hierarkkista klusterointia varten hyödynnämme mahtavaa käsitettä nimeltä Dendrogrammi.
Dendrogrammi on puumainen kaavio, johon on kirjattu yhdistymisten tai jakautumisten peräkkäiset tapahtumat.
Palaamme takaisin opettaja-oppilas-esimerkkiimme. Aina kun yhdistämme kaksi klusteria, dendrogrammi tallentaa näiden klusterien välisen etäisyyden ja esittää sen graafisessa muodossa. Katsotaanpa, miltä dendrogrammi näyttää:
Meillä on aineiston näytteet x-akselilla ja etäisyys y-akselilla. Aina kun kaksi klusteria yhdistetään, liitämme ne tähän dendrogrammiin ja liitoksen korkeus on näiden pisteiden välinen etäisyys. Rakennetaan dendrogrammi esimerkillemme:
Käsittele hetki yllä olevaa kuvaa. Aloitimme yhdistämällä näytteet 1 ja 2, ja näiden kahden näytteen välinen etäisyys oli 3 (katso ensimmäinen läheisyysmatriisi edellisessä kappaleessa). Piirretään tämä dendrogrammi:
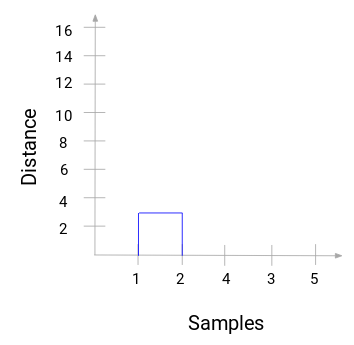
Tässä näemme, että olemme yhdistäneet näytteet 1 ja 2. Pystyviiva kuvaa näiden näytteiden välistä etäisyyttä. Vastaavasti piirrämme kaikki vaiheet, joissa yhdistimme klusterit, ja lopulta saamme tällaisen dendrogrammin:
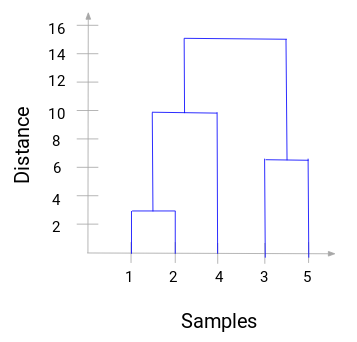
Voidaan selvästi havainnollistaa hierarkkisen klusteroinnin vaiheet. Mitä suurempi on pystysuorien viivojen etäisyys dendrogrammissa, sitä suurempi on näiden klusterien välinen etäisyys.
Nyt voimme asettaa kynnysetäisyyden ja piirtää vaakasuoran viivan (Yleensä pyrimme asettamaan kynnysarvon siten, että se leikkaa korkeimman pystysuoran viivan). Asetetaan tälle kynnysarvolle 12 ja piirretään vaakasuora viiva:
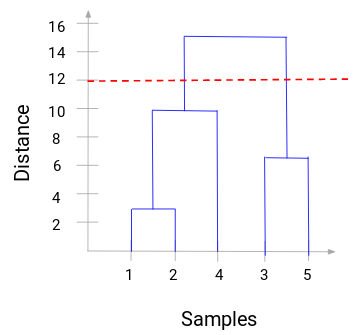
Ryhmien lukumäärä on niiden pystysuorien viivojen lukumäärä, jotka kynnysarvon avulla piirretty viiva leikkaa. Yllä olevassa esimerkissä, koska punainen viiva leikkaa 2 pystysuoraa viivaa, meillä on 2 klusteria. Toisessa klusterissa on näyte (1,2,4) ja toisessa (3,5). Aika suoraviivaista, eikö?
Näin voimme päättää klustereiden määrän käyttämällä dendrogrammia hierarkkisessa klusteroinnissa. Seuraavassa osiossa toteutamme hierarkkisen klusteroinnin, joka auttaa sinua ymmärtämään kaikki tässä artikkelissa oppimamme käsitteet.
Tukkumyyntiasiakkaiden segmentointiongelman ratkaiseminen hierarkkisen klusteroinnin avulla
Aika liata kätemme Pythonissa!
Työstämme tukkumyyntiasiakkaiden segmentointiongelmaa. Voit ladata datasetin tästä linkistä. Dataa säilytetään UCI:n Machine Learning -rekisterissä. Tämän ongelman tavoitteena on segmentoida tukkukaupan jakelijan asiakkaat sen perusteella, kuinka paljon he käyttävät vuosittain rahaa erilaisiin tuotekategorioihin, kuten maitoon, päivittäistavaroihin, alueeseen jne.
Tutkiskellaan ensin dataa ja sovelletaan sitten hierarkkista klusterointia asiakkaiden segmentointiin.
Tuomme ensin tarvittavat kirjastot:
Lataamme datan ja tarkastelemme ensimmäisiä rivejä:
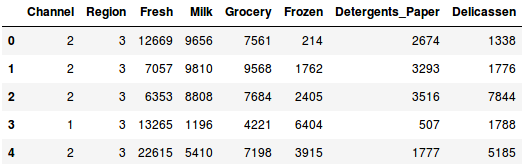
Tuotekategorioita on useita – Tuore, Maito, Päivittäistavarakauppa jne. Arvot edustavat kunkin asiakkaan ostamien yksiköiden määrää kunkin tuotteen osalta. Tavoitteenamme on muodostaa näistä tiedoista klustereita, joilla samankaltaiset asiakkaat voidaan segmentoida yhteen. Käytämme tietysti hierarkkista klusterointia tähän ongelmaan.
Mutta ennen kuin sovellamme hierarkkista klusterointia, meidän on normalisoitava tiedot niin, että jokaisen muuttujan asteikko on sama. Miksi tämä on tärkeää? No, jos muuttujien mittakaava ei ole sama, malli saattaa vinoutua kohti muuttujia, joilla on suurempi suuruusluokka, kuten Fresh tai Milk (katso yllä olevaa taulukkoa).
Normalisoidaan siis ensin tiedot ja saatetaan kaikki muuttujat samaan mittakaavaan:
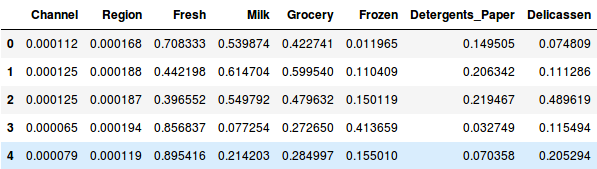
Tässä näemme, että kaikkien muuttujien mittakaava on melkein samanlainen. Nyt olemme valmiita lähtemään liikkeelle. Piirretään ensin dendrogrammi, joka auttaa meitä päättämään klustereiden määrän tässä nimenomaisessa ongelmassa:
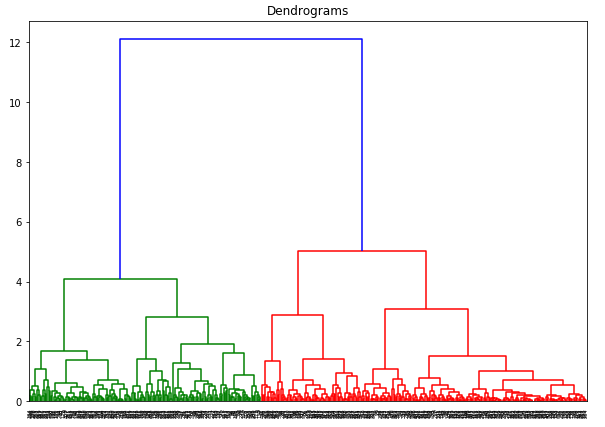
X-akselilla on näytteet ja y-akselilla näiden näytteiden välinen etäisyys. Pystysuora viiva, jonka etäisyys on suurin, on sininen viiva, joten voimme päättää kynnysarvoksi 6 ja leikata dendrogrammin:
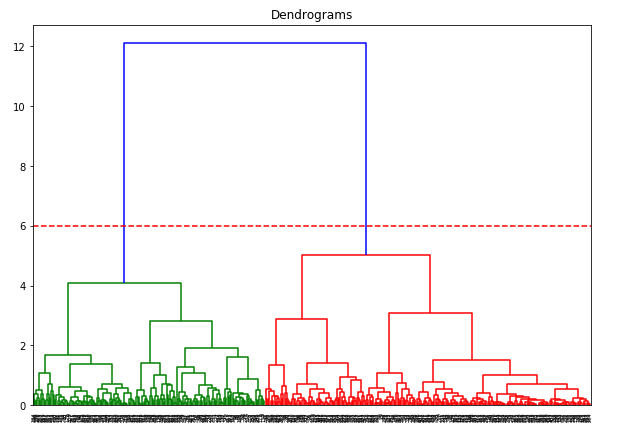
Meillä on kaksi klusteria, koska tämä viiva leikkaa dendrogrammin kahdessa pisteessä. Sovelletaan nyt hierarkkista klusterointia kahdelle klusterille:
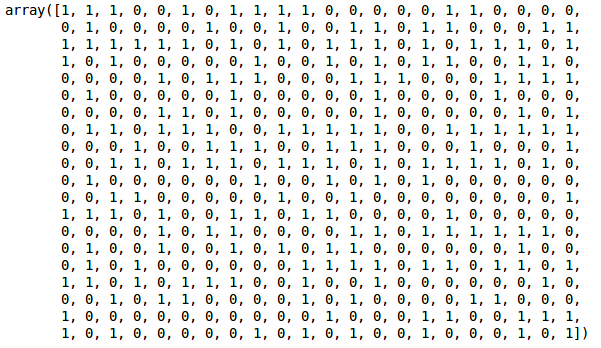
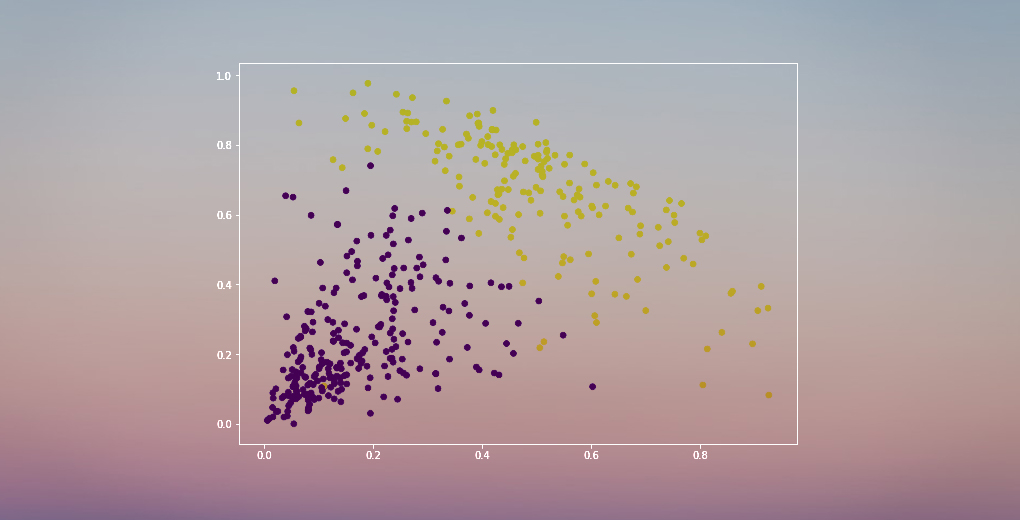
Näemme tulosteessa 0:n ja 1:n arvot, koska määrittelimme kaksi klusteria. 0 edustaa ensimmäiseen klusteriin kuuluvia pisteitä ja 1 edustaa toiseen klusteriin kuuluvia pisteitä. Visualisoidaan nyt kaksi klusteria:
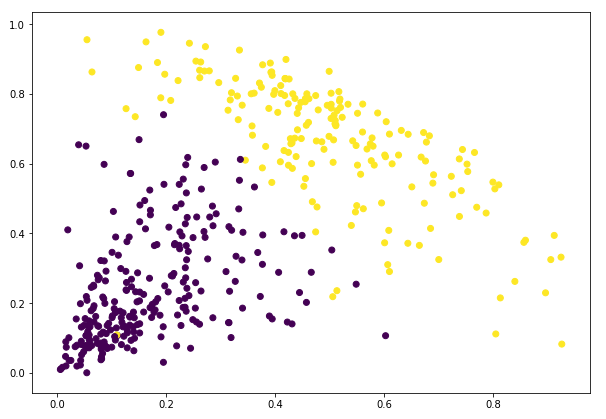
Hienoa! Voimme visualisoida tässä selvästi kaksi klusteria. Näin voimme toteuttaa hierarkkisen klusteroinnin Pythonissa.
Loppuhuomautukset
Hierarkkinen klusterointi on erittäin hyödyllinen tapa segmentoida havaintoja. Etu siitä, että klustereiden määrää ei tarvitse määritellä etukäteen, antaa sille melkoisen etulyöntiaseman k-Meansiin verrattuna.
Jos olet vielä suhteellisen uusi datatieteissä, suosittelen lämpimästi Applied Machine Learning -kurssin käymistä. Se on yksi kattavimmista kokonaisvaltaisista koneoppimisen kursseista, joita löydät mistään. Hierarkkinen klusterointi on vain yksi monipuolisista aiheista, joita käsittelemme kurssilla.