Esittely
Päätöspuu on eräänlainen valvotun oppimisen algoritmi, jota voidaan käyttää sekä regressio- että luokitusongelmissa. Se toimii sekä kategorisille että jatkuville tulo- ja lähtömuuttujille.
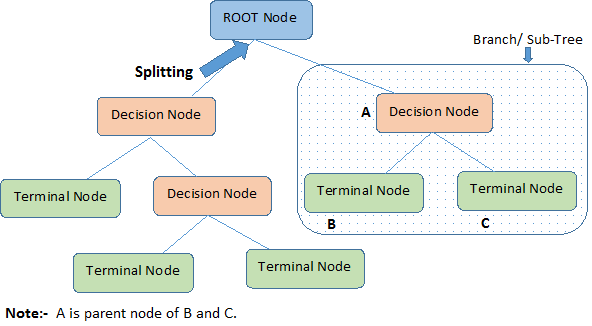
Tunnistetaan päätöksentekopuuhun liittyvät tärkeät termit yllä olevaa kuvaa tarkastelemalla:
-
Juurisolmu edustaa koko perusjoukkoa tai otosta. Se jaetaan edelleen kahteen tai useampaan homogeeniseen joukkoon.
-
Jako tarkoittaa solmun jakamista kahteen tai useampaan alisolmuun.
-
Kun alisolmu jakaantuu edelleen alisolmuiksi, sitä kutsutaan päätöksentekosolmuksi.
-
Solmua, joka ei jakaannu, kutsutaan päätesolmuksi tai lehdeksi.
-
Kun poistat päätöksentekosolmun alasolmuja, tätä prosessia kutsutaan karsimiseksi. Karsinnan vastakohta on Jakaminen.
-
Kokonaisen puun osa-aluetta kutsutaan haaraksi.
-
Solmua, joka on jaettu alisolmuihin, kutsutaan alisolmujen vanhemmaksi solmuksi; kun taas alisolmuja kutsutaan vanhemman solmun lapsiksi.
Päätöksentekopuiden tyypit
Regressiopuut
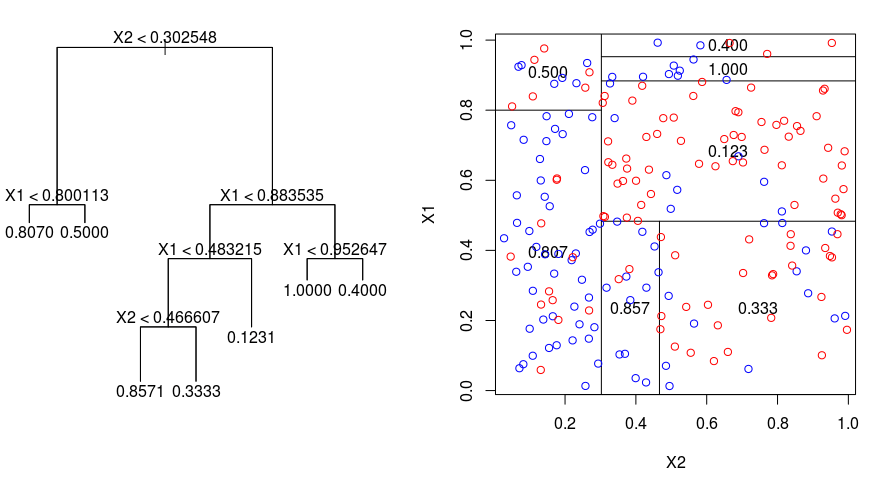
Katsotaanpa alla olevaa kuvaa, joka auttaa havainnollistamaan Regressiopuiden suorittaman osituksen luonnetta. Kuvassa näkyy karsimaton puu ja regressiopuu, joka on sovitettu satunnaiseen aineistoon. Molemmissa visualisoinneissa näkyy sarja jakosääntöjä, jotka alkavat puun huipulta. Huomaa, että jokainen toimialueen jako on linjassa yhden ominaisuusakselin kanssa. Akselien yhdensuuntaisen jakamisen käsite yleistyy suoraviivaisesti kahta suurempiin ulottuvuuksiin. Kooltaan $p$:n suuruiselle piirreavaruudelle, joka on $\mathbb{R}^p$:n osajoukko, avaruus jaetaan $M$:ään alueeseen, $R_{m}$, joista kukin on $p$-ulotteinen ”hyperlohko”.
Regressiopuun rakentamiseksi käytetään ensin rekursiivista binääristä pilkkomista kasvattamaan harjoitusaineistoon suuri puu, joka pysähtyy vasta, kun jokaisessa päätepisteessä on vähemmän kuin jokin vähimmäismäärä havaintoja. Rekursiivinen binäärijako on ahne ja ylhäältä alaspäin etenevä algoritmi, jota käytetään minimoimaan jäännösneliösummaa (RSS), joka on myös lineaarisessa regressiossa käytetty virhemittari. RSS, kun kyseessä on osioitu ominaisuusavaruus, jossa on M osiota, saadaan:
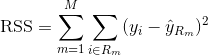
Aloitetaan puun huipulta ja jaetaan se kahteen haaraan, jolloin luodaan kahden tilan osio. Sitten suoritetaan tämä tietty jako puun huipulla useita kertoja ja valitaan ominaisuuksien jako, joka minimoi (nykyisen) RSS:n.
Sitten sovelletaan kustannuskompleksisuuden karsintaa suureen puuhun, jotta saadaan parhaiden alipuiden sarja $\alpha$:n funktiona. Perusidea tässä on ottaa käyttöön ylimääräinen viritysparametri, jota merkitään $\alpha$:lla ja joka tasapainottaa puun syvyyttä ja sen sopivuutta harjoitusaineistoon.
Voit käyttää $\alpha$:n valintaan K-kertaista ristiinvalidointia. Tässä tekniikassa koulutushavainnot yksinkertaisesti jaetaan K-kertaukseen alipuiden testivirheprosentin arvioimiseksi. Tavoitteenasi on valita se, joka johtaa pienimpään virheprosenttiin.
Luokittelupuut
Luokittelupuu on hyvin samankaltainen kuin regressiopuu, paitsi että sitä käytetään ennustamaan kvalitatiivista vastetta kvantitatiivisen vasteen sijaan.
Muistutetaan, että regressiopuiden tapauksessa havainnon ennustettu vaste saadaan samaan päätepisteen solmupisteeseen kuuluvien harjoitteluhavaintojen keskimääräisen vasteen perusteella. Sitä vastoin luokittelupuussa ennustetaan, että kukin havainto kuuluu harjoitushavaintojen yleisimmin esiintyvään luokkaan sillä alueella, johon se kuuluu.
Luokittelupuun tuloksia tulkittaessa ollaan usein kiinnostuneita paitsi tiettyä päätepisteen aluetta vastaavasta luokkaennusteesta myös luokkien osuuksista kyseiselle alueelle kuuluvien harjoitushavaintojen joukossa.
Luokittelupuun kasvattamistehtävä on varsin samankaltainen kuin regressiohavainnon kasvattamistehtävä. Aivan kuten regressioasetelmassa, luokittelupuun kasvattamiseen käytetään rekursiivista binäärijakoa. Luokitteluasetelmassa jäännösneliösummaa ei kuitenkaan voida käyttää kriteerinä binäärijakojen tekemisessä. Sen sijaan voit käyttää jompaakumpaa seuraavista kolmesta menetelmästä:
- Luokittelun virhetaso: Sen sijaan, että katsoisit, kuinka kaukana numeerinen vastaus on keskiarvosta, kuten regressioasetuksessa, voit sen sijaan määritellä ”osumisprosentin” tietyllä alueella olevien harjoitushavaintojen osuudeksi, jotka eivät kuulu yleisimmin esiintyvään luokkaan. Virhe saadaan tällä yhtälöllä:
E = 1 – argmaxc($\hat{\pi}_{mc}$)
jossa $\hat{\pi}_{mc}$ edustaa alueen Rm harjoitteluaineiston murto-osaa, joka kuuluu luokkaan c.
- Gini-indeksi: Gini-indeksi on vaihtoehtoinen virhemittari, jonka tarkoituksena on osoittaa, kuinka ”puhdas” alue on. ”Puhtaus” tarkoittaa tässä tapauksessa sitä, kuinka suuri osa tietyn alueen harjoitusaineistosta kuuluu yhteen luokkaan. Jos alue Rm sisältää dataa, joka on suurimmaksi osaksi yhdestä luokasta c, Gini-indeksin arvo on pieni:
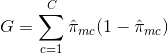
- Cross-Entropy: Kolmas vaihtoehto, joka on samanlainen kuin Gini-indeksi, tunnetaan nimellä risti-entropia tai poikkeavuus:
Risti-entropia saa arvon lähellä nollaa, jos $\hat{\pi}_{mc}$:n arvot ovat kaikki lähellä 0:ta tai lähellä 1:tä. Gini-indeksin tavoin risti-entropia saa siis pienen arvon, jos m:nneksi suurin solmu on puhdas. Itse asiassa käy ilmi, että Gini-indeksi ja risti-entropia ovat numeerisesti melko samankaltaisia.
Luokittelupuuta rakennettaessa käytetään tyypillisesti joko Gini-indeksiä tai risti-entropiaa arvioimaan tietyn jaon laatua, koska ne ovat herkempiä solmujen puhtaudelle kuin luokittelun virhetaso. Mitä tahansa näistä kolmesta lähestymistavasta voidaan käyttää karsittaessa puuta, mutta luokitteluvirheprosentti on suositeltavampi, jos lopullisen karsitun puun ennustetarkkuus on tavoitteena.
Päätöksentekopuiden edut ja haitat
Päätöksentekopuiden käytön suurimpana etuna on se, että ne ovat intuitiivisesti hyvin helposti selitettävissä. Ne peilaavat läheisesti ihmisen päätöksentekoa verrattuna muihin regressio- ja luokittelumenetelmiin. Ne voidaan esittää graafisesti, ja ne pystyvät helposti käsittelemään kvalitatiivisia ennusteita ilman, että on tarpeen luoda dummy-muuttujia.
Päätöspuilla ei kuitenkaan yleensä ole samaa ennustustarkkuutta kuin muilla lähestymistavoilla, koska ne eivät ole aivan kestäviä. Pieni muutos datassa voi aiheuttaa suuren muutoksen lopulliseen estimoituun puuhun.
Kokoamalla monia päätöspuita käyttämällä menetelmiä, kuten pussitus, satunnaismetsät ja boosting, päätöspuiden ennustuskykyä voidaan parantaa huomattavasti.
Päätöksentekopuihin perustuvat menetelmät
Päätöksentekopuiden pussittaminen
Edellä käsitellyt päätöspuut kärsivät suuresta varianssista, mikä tarkoittaa sitä, että jos harjoitusaineisto jaetaan kahteen osaan sattumanvaraisesti ja sovitetaan päätöspuu molempiin puolikkaisiin, saadut tulokset voivat olla hyvinkin erilaisia. Sen sijaan menettely, jolla on pieni varianssi, tuottaa samanlaisia tuloksia, jos sitä sovelletaan toistuvasti erilliseen aineistoon.
Baggaus eli bootstrap-aggregaatio on tekniikka, jota käytetään ennusteiden varianssin pienentämiseen yhdistämällä useiden saman aineiston eri osanäytteisiin mallinnettujen luokittelijoiden tulokset. Tässä on baggingin yhtälö:
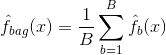
jossa luodaan $B$ erilaista bootstrapattua harjoitusaineistoa. Sitten harjoittelet menetelmääsi $bth$ bootstrapped-koulutusjoukolla saadaksesi $\hat{f}_{b}(x)$ ja lopuksi keskiarvoistat ennusteet.
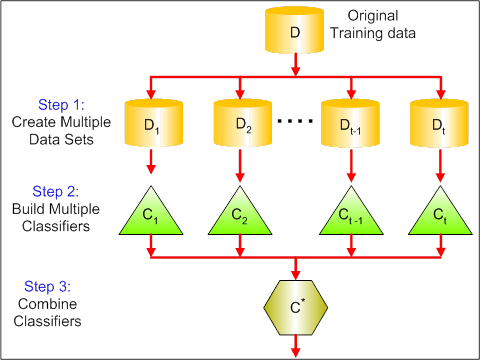
Oheisessa kuvassa näkyvät baggingin 3 eri vaihetta:
-
Vaihe 1: Tässä korvataan alkuperäinen data uudella datalla. Uudessa datassa on yleensä murto-osa alkuperäisen datan sarakkeista ja riveistä, joita voidaan sitten käyttää hyperparametreina bagging-mallissa.
-
Vaihe 2: Rakennetaan luokittelijat kullekin aineistolle. Yleensä voit käyttää samaa luokittelijaa mallien ja ennusteiden tekemiseen.
-
Vaihe 3: Lopuksi käytät keskiarvoa kaikkien luokittelijoiden ennusteiden yhdistämiseen ongelmasta riippuen. Yleensä nämä yhdistetyt arvot ovat kestävämpiä kuin yksittäinen malli.
Vaikka pussitus voi parantaa ennusteita monissa regressio- ja luokitusmenetelmissä, se on erityisen hyödyllinen päätöspuille. Jos haluat soveltaa pussitusmenetelmää regressio- tai luokittelupuihin, rakennat yksinkertaisesti $B$ regressio- tai luokittelupuita käyttäen $B$ bootstrapattuja harjoitusjoukkoja ja keskiarvoistat saadut ennusteet. Nämä puut kasvatetaan syviksi, eikä niitä karsita. Näin ollen jokaisella yksittäisellä puulla on suuri varianssi, mutta pieni harha. Näiden $B$ puiden keskiarvoistaminen pienentää varianssia.
Laaja-alaisesti sanottuna pussitus on osoittanut antavansa vaikuttavia parannuksia tarkkuuteen yhdistämällä satoja tai jopa tuhansia puita yhteen menettelyyn.
Satunnaismetsät
Satunnaismetsät on monipuolinen koneoppimismenetelmä, joka pystyy suorittamaan sekä regressio- että luokitustehtäviä. Se suorittaa myös dimensioiden pienentämismenetelmiä, käsittelee puuttuvia arvoja, outlier-arvoja ja muita datan tutkimisen olennaisia vaiheita, ja tekee melko hyvää työtä.
Random Forests tarjoaa parannuksen pussitettuihin puihin verrattuna pienellä virityksellä, joka dekorreloi puut. Kuten pussituksessa, rakennat useita päätöspuita bootstrapped-harjoitusnäytteistä. Mutta kun näitä päätöspuita rakennetaan, joka kerta kun puun jakoa harkitaan, valitaan satunnainen otos m:stä ennustajasta jakoehdokkaiksi koko $p$:n ennustajien joukosta. Jako saa käyttää vain yhtä näistä $m$ ennustajista. Tämä on tärkein ero satunnaismetsän ja pussitusmetsän välillä; sillä kuten pussitusmetsässä, ennustajan valinta $m = p$.
Satunnaismetsän kasvattamiseksi sinun tulee:
-
Esimerkiksi olettaa, että harjoitusjoukon tapausten lukumäärä on K. Ota sitten satunnaisotos näistä K tapauksesta ja käytä tätä otosta koulutusjoukkona puun kasvattamiseen.
-
Jos on $p$ tulomuuttujia, määritä sellainen luku $m < p$, että jokaisessa solmussa voit valita $m$ satunnaismuuttujaa $p$:stä. Parasta jakoa näistä $m$ käytetään solmun jakamiseen.
-
Jokaista puuta kasvatetaan tämän jälkeen mahdollisimman suureksi, eikä karsintaa tarvita.
-
Viimeiseksi aggregoidaan kohdepuiden ennusteet, jotta voidaan ennustaa uutta dataa.
Sattumanvaraiset metsät ovat erittäin tehokkaita puuttuvan datan arvioinnissa ja tarkkuuden säilyttämisessä silloin, kun datasta puuttuu suuri osuus. Se voi myös tasapainottaa virheitä aineistoissa, joissa luokat ovat epätasapainossa. Mikä tärkeintä, se pystyy käsittelemään massiivisia tietokokonaisuuksia, joissa on suuri dimensiotaso. Yksi satunnaismetsän käytön haittapuoli on kuitenkin se, että varsinkin regressiota tehtäessä saatetaan helposti ylisovittaa meluisia tietokokonaisuuksia.
Boosting
Boosting on toinen lähestymistapa, jolla parannetaan päätöspuun tuottamia ennusteita. Kuten pussitus ja satunnaismetsät, se on yleinen lähestymistapa, jota voidaan soveltaa moniin tilastollisiin oppimismenetelmiin regressiota tai luokittelua varten. Muistutetaan, että pussituksessa luodaan useita kopioita alkuperäisestä harjoitusaineistosta bootstrapin avulla, sovitetaan erillinen päätöspuu kuhunkin kopioon ja yhdistetään sitten kaikki puut yhden ennustemallin luomiseksi. Huomionarvoista on, että jokainen puu rakennetaan bootstrap-tietoaineistoon, joka on riippumaton muista puista.
Boosting toimii samalla tavalla, paitsi että puut kasvatetaan peräkkäin: kukin puu kasvatetaan käyttämällä aiemmin kasvatettujen puiden tietoja. Boosting ei sisällä bootstrap-näytteenottoa; sen sijaan jokainen puu sovitetaan alkuperäisen tietokokonaisuuden muunnettuun versioon.
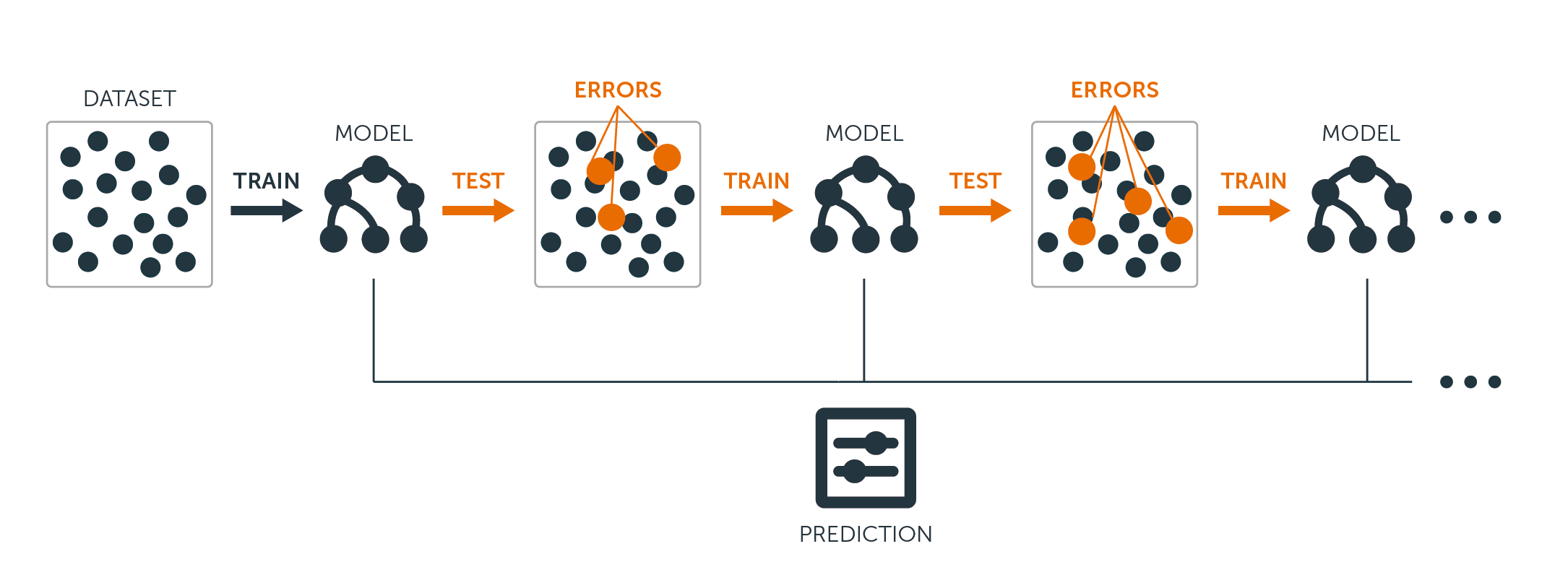
Sekä regressio- että luokittelupuiden osalta boosting toimii seuraavasti:
-
Vastoin kuin yhden suuren päätöspuun sovittaminen aineistoon, mikä tarkoittaa kovaa sovittamista aineistoon ja mahdollisesti ylisovittamista, boosting-menetelmä sen sijaan oppii hitaasti.
-
Sovitetaan nykyiseen malliin päätöksentekopuu mallin jäännöksille. Toisin sanoen sovitat puun, joka käyttää vastauksena nykyisiä residuaaleja eikä lopputulosta $Y$.
-
Sitten lisäät tämän uuden päätöspuun sovitettuun funktioon päivittääksesi residuaalit. Kukin näistä puista voi olla melko pieni, vain muutama päätepisteen solmu, joka määräytyy algoritmin parametrin $d$ mukaan. Sovittamalla pieniä puita residuaaleihin parannat hitaasti $\hat{f}$:ta niillä alueilla, joilla se ei suoriudu hyvin.
-
Supistamisparametri $\nu$ hidastaa prosessia entisestään, mikä mahdollistaa useampien ja erimuotoisten puiden hyökkäämisen residuaalien kimppuun.
Päätöksentekopuiden tehostaminen on erittäin hyödyllistä silloin, kun sinulla on paljon dataa, ja oletat päätöspuiden olevan hyvin monimutkaisia. Boostingia on käytetty monien haastavien luokittelu- ja regressio-ongelmien ratkaisemiseen, muun muassa riskianalyysissä, tunneanalyysissä, ennakoivassa mainonnassa, hintamallinnuksessa, myynnin arvioinnissa ja potilasdiagnostiikassa.
Päätöksentekopuut R:ssä
Luokittelupuut
Tässä osassa työskentelet Carseats-tietokannan parissa R:ssä tree-paketin avulla. Muista, että sinun on ensin asennettava R Studio -ympäristöösi ISLR– ja tree-ohjelmapaketit. Ladataan ensin Carseats-tietokanta ISLR-paketista.
library(ISLR)data(package="ISLR")carseats<-CarseatsLadataan myös tree-paketti.
require(tree)Datakokonaisuus Carseats on datakehys, jossa on 400 havaintoa seuraavista 11 muuttujasta:
-
Myynti: kappalemääräinen myynti tuhansina
-
CompPrice: Kilpailijan kussakin toimipisteessä veloittama hinta
-
Tulot: yhteisön tulotaso tuhansina dollareina
-
Mainonta: paikallinen mainosbudjetti kussakin toimipisteessä tuhansina dollareina
-
Väestö: alueen väkiluku tuhansina dollareina
-
Hinta: autopaikkojen hinta kussakin toimipisteessä
-
ShelveLoc: Bad, Good tai Medium kertoo hyllypaikan laadun
-
Age: väestön ikätaso
-
Education: ed level at location
-
Urban: Kyllä/Ei
-
Yhdyskunta: Kyllä/Ei
names(carseats)Katsotaanpa autojen myynnin histogrammia:
hist(carseats$Sales)Huomaa, että Sales on määrällinen muuttuja. Haluat havainnollistaa sen käyttämällä puita, joissa on binäärivaste. Tätä varten muutat Sales:n binäärimuuttujaksi, jonka nimi on High. Jos myynti on pienempi kuin 8, se ei ole korkea. Muussa tapauksessa se on korkea. Sitten voit laittaa tuon uuden muuttujan High takaisin datakehykseen.
High = ifelse(carseats$Sales<=8, "No", "Yes")carseats = data.frame(carseats, High)Täytetään nyt malli käyttäen päätöspuita. Tässä ei tietenkään voi olla muuttujaa Sales, koska vastemuuttujasi High luotiin muuttujasta Sales. Jätetään siis se pois ja sovitetaan puu.
tree.carseats = tree(High~.-Sales, data=carseats)Katsotaanpa luokittelupuusi yhteenveto:
summary(tree.carseats)Näet mukana olevat muuttujat, päätepisteiden solmujen lukumäärän, jäännöskeskiarvon poikkeaman sekä virheellisen luokittelun virhetason. Jotta asia olisi havainnollisempi, piirretään puu myös kaaviona ja kommentoidaan se sitten kätevällä text-funktiolla:
plot(tree.carseats)text(tree.carseats, pretty = 0)Muuttujia on niin paljon, että puun tarkastelu on hyvin monimutkaista. Ainakin näet, että jokaisessa päätepisteen solmussa on merkintä Yes tai No. Jokaisessa jakosolmussa näkyvät muuttujat ja jakovalinnan arvo (esimerkiksi Price < 92.5 tai Advertising < 13.5).
Jos haluat yksityiskohtaisen yhteenvedon puusta, tulosta se yksinkertaisesti. Se on kätevä, jos haluat poimia puusta yksityiskohtia muita tarkoituksia varten:
tree.carseatsOn aika karsia puu alas. Luodaan harjoitusjoukko ja testi jakamalla carseats-tietokehys 250 harjoitus- ja 150 testinäytteeseen. Asetetaan ensin siemen, jotta tulokset olisivat toistettavissa. Sitten otat satunnaisotoksen näytteiden ID (indeksi) -numeroista. Konkreettisesti tässä otat näytteen joukosta 1-n autopaikkojen rivien lukumäärä, joka on 400. Haluat otoksen, jonka koko on 250 (oletusarvoisesti otos käyttää ilman korvausta).
set.seed(101)train=sample(1:nrow(carseats), 250)Siten saat nyt tämän indeksin train, joka indeksoi 250 havaintoa 400:sta. Voit sovittaa mallin uudelleen tree:llä käyttäen samaa kaavaa paitsi käskemällä puun käyttää osajoukkoa, joka vastaa train. Tehdään sitten kuvaaja:
tree.carseats = tree(High~.-Sales, carseats, subset=train)plot(tree.carseats)text(tree.carseats, pretty=0)Kuvaaja näyttää hieman erilaiselta hieman erilaisen aineiston vuoksi. Puun monimutkaisuus näyttää kuitenkin suunnilleen samalta.
Nyt otetaan tämä puu ja ennustetaan se testijoukolle käyttäen predict-menetelmää puille. Tässä haluat oikeasti ennustaa class-tunnisteet.
tree.pred = predict(tree.carseats, carseats, type="class")Sitten voit arvioida virhettä käyttämällä vääräluokittelutaulukkoa.
with(carseats, table(tree.pred, High))Diagonaalien päällä ovat oikeat luokitukset, kun taas diagonaalien ulkopuolella ovat väärät luokitukset. Haluat kerrata vain oikeat luokitukset. Sitä varten voit ottaa 2 diagonaalin summan jaettuna kokonaismäärällä (150 testihavaintoa).
(72 + 43) / 150Ok, saat tällä puulla virheen 0.76.
Kun kasvatat isoa pensasmaista puuta, sillä voi olla liikaa varianssia. Käytetään siis ristiinvalidoinnin avulla karsitaan puu optimaalisesti. Käyttämällä cv.tree käytetään väärinluokitteluvirhettä karsinnan tekemisen perustana.
cv.carseats = cv.tree(tree.carseats, FUN = prune.misclass)cv.carseatsTulostamalla tulokset nähdään ristiinvalidoinnin polun yksityiskohdat. Näet puiden koot, kun niitä karsittiin takaisin, poikkeamat karsinnan edetessä sekä prosessissa käytetyn kustannuskompleksisuusparametrin.
Kuvioidaan tämä kaaviona:
plot(cv.carseats)Katsomalla kaaviota näet alaspäin suuntautuvan kierteisen osan, joka johtuu 250 ristiinvalidoidun pisteen virheellisestä luokitteluvirheestä. Valitaan siis arvo alaspäin suuntautuvassa portaassa (12). Tämän jälkeen karsitaan puu 12:n suuruiseksi, jotta tämä puu voidaan tunnistaa. Lopuksi piirretään ja merkitään tuo puu, jotta nähdään lopputulos.
prune.carseats = prune.misclass(tree.carseats, best = 12)plot(prune.carseats)text(prune.carseats, pretty=0)Se on hieman matalampi kuin aiemmat puut, ja voit itse asiassa lukea merkinnät. Arvioidaan sitä uudelleen testiaineistolla.
tree.pred = predict(prune.carseats, carseats, type="class")with(carseats, table(tree.pred, High))(74 + 39) / 150Näyttää siltä, että oikeat luokitukset putosivat hieman. Se on tehnyt suunnilleen saman kuin alkuperäinen puusi, joten karsiminen ei juurikaan haitannut väärinluokitteluvirheiden suhteen, ja antoi yksinkertaisemman puun.
Tiheässä tapauksessa puut eivät anna kovin hyviä ennustusvirheitä, joten mennäänpä eteenpäin katsomaan satunnaismetsiä ja boostingia, jotka yleensä päihittävät puut ennusteiden ja vääräluokittelun suhteen.
Satunnaismetsät
Tässä osassa käytät Boston housing data:tä tutkiaksesi satunnaismetsiä ja boostingia. Aineisto sijaitsee MASS-paketissa. Se antaa asuntoarvot ja muut tilastot jokaisessa Bostonin 506 lähiössä vuoden 1970 väestönlaskentaan perustuen.
library(MASS)data(package="MASS")boston<-Bostondim(boston)names(boston)Ladataan myös randomForest-paketti.
require(randomForest)Valmistellaksemme dataa satunnaismetsää varten asetetaan siemen ja luodaan 300 havainnon esimerkkiharjoitusjoukko.
set.seed(101)train = sample(1:nrow(boston), 300)Tämässä datasarjassa on 506 Bostonin lähiötä. Kunkin esikaupungin osalta on muuttujia, kuten rikollisuus asukasta kohti, teollisuustyypit, keskimääräinen huoneiden lukumäärä asuntoa kohti, talojen keskimääräinen ikäosuus jne. Käytetään vastemuuttujana medv – omistusasuntojen mediaaniarvoa kussakin näistä esikaupunkialueista.
Sovitetaan satunnaismetsä ja katsotaan, miten hyvin se toimii. Kuten sanottu, käytetään vastetta medv, asuntojen mediaaniarvoa (1 000 dollarin dollareina) ja harjoitusotosjoukkoa.
rf.boston = randomForest(medv~., data = boston, subset = train)rf.bostonSatunnaismetsän tulostaminen antaa sen yhteenvedon: puiden lukumäärä (puita kasvatettiin 500 kappaletta), residuaalien keskineliö (MSR) ja selitetyn varianssin prosenttiosuus. MSR ja selitetyn varianssin % perustuvat out-of-bag-estimaatteihin, mikä on satunnaismetsissä erittäin näppärä keino saada rehellisiä virheestimaatteja.
Ainut viritysparametri satunnaismetsässä on argumentti nimeltä mtry, joka on niiden muuttujien määrä, jotka valitaan jokaisen puun jokaisella jakokerralla tehtäessä jakoa. Kuten tässä nähdään, mtry on 4 Boston Housing -aineiston 13:sta tutkivasta muuttujasta (pois lukien medv) – mikä tarkoittaa, että joka kerta, kun puu tulee jakamaan solmua, 4 muuttujaa valitaan satunnaisesti, minkä jälkeen jako rajoittuu yhteen näistä neljästä muuttujasta. Näin randomForests dekorreloi puut.
Sovitetaan sarja satunnaismetsiä. Muuttujia on 13, joten annetaan mtry:n vaihdella 1:stä 13:een:
-
Virheiden kirjaamista varten asetat 2 muuttujaa
oob.errjatest.err. -
Silmukassa
mtry:n vaihteluväli on 1:stä 13:een, sovitat ensiksirandomForest:n kyseisellämtry:n arvollatrain:n tietokokonaisuuksiin rajoittamalla puiden määrän 350:een. -
Sitten poimit kohteen keskineliövirheen (out-of-bag-virhe).
-
Sitten ennustat testidatasetilla (
boston) käyttäenfit(sovitusrandomForest). -
Viimeiseksi lasket testivirheen: keskineliövirheen, joka on yhtä suuri kuin
mean( (medv - pred) ^ 2 ).
oob.err = double(13)test.err = double(13)for(mtry in 1:13){ fit = randomForest(medv~., data = boston, subset=train, mtry=mtry, ntree = 350) oob.err = fit$mse pred = predict(fit, boston) test.err = with(boston, mean( (medv-pred)^2 ))}Periaatteessa kasvatit juuri 4550 puuta (13 kertaa 350). Tehdään nyt kuvaaja käyttäen komentoa matplot. Testivirhe ja pussin ulkopuolinen virhe sidotaan yhteen 2-sarakkeiseksi matriisiksi. Matriisissa on muutama muukin argumentti, kuten piirtomerkin arvot (pch = 23 tarkoittaa täytettyä timanttia), värit (punainen ja sininen), type equals both (piirtää molemmat pisteet ja yhdistää ne viivoilla) ja y-akselin nimi (Mean Squared Error). Voit myös laittaa kuvaajan oikeaan yläkulmaan legendan.
matplot(1:mtry, cbind(test.err, oob.err), pch = 23, col = c("red", "blue"), type = "b", ylab="Mean Squared Error")legend("topright", legend = c("OOB", "Test"), pch = 23, col = c("red", "blue"))Itse asiassa näiden kahden käyrän pitäisi olla samassa linjassa, mutta näyttää siltä, että testivirhe on hieman pienempi. Näissä testivirhearvioissa on kuitenkin paljon vaihtelua. Koska out-of-bag-virhe-estimaatti laskettiin yhdestä aineistosta ja testivirhe-estimaatti laskettiin toisesta aineistosta, nämä erot ovat melko hyvin keskivirheiden sisällä.
Huomaa, että punainen käyrä on tasaisesti sinisen käyrän yläpuolella? Nämä virheestimaatit korreloivat hyvin paljon keskenään, koska randomForest ja mtry = 4 ovat hyvin samankaltaisia kuin mtry = 5. Siksi kumpikin käyrä on melko tasainen. Nähdään, että mtry noin 4 näyttää olevan optimaalisin valinta, ainakin testivirheen osalta. Tämä mtry:n arvo pussin ulkopuoliselle virheelle on yhtä kuin 9.
Siten hyvin harvoilla tasoilla olet sovittanut erittäin tehokkaan ennustemallin satunnaismetsiä käyttäen. Miten niin? Vasemmalla näkyy yhden puun suorituskyky. Out-of-bagin keskimääräinen neliövirhe on 26, ja olet pudottanut sen noin 15:een (hieman yli puoleen). Tämä tarkoittaa, että olet pienentänyt virheen puoleen. Samoin testivirheen osalta vähensit virhettä 20:stä 12:een.
Boosting
Vertailtuna satunnaismetsiin, boosting kasvattaa pienempiä ja järeämpiä puita ja menee vinoon. Käytät pakettia GBM (Gradient Boosted Modeling), R:ssä.
require(gbm)GBM kysyy jakaumaa, joka on Gaussin, koska teet neliövirhehäviön. Kysyt GBM:ltä 10 000 puuta, mikä kuulostaa paljolta, mutta nämä tulevat olemaan matalia puita. Vuorovaikutussyvyys on jakojen määrä, joten haluat 4 jakoa jokaiseen puuhun. Shrinkage on 0.01, eli kuinka paljon aiot kutistaa puun askelta taaksepäin.
boost.boston = gbm(medv~., data = boston, distribution = "gaussian", n.trees = 10000, shrinkage = 0.01, interaction.depth = 4)summary(boost.boston)Funktio summary antaa muuttujan tärkeysdiagrammin. Näyttää siltä, että on 2 muuttujaa, joilla on suuri suhteellinen merkitys: rm (huoneiden lukumäärä) ja lstat (alemman taloudellisen aseman omaavien ihmisten osuus yhteisössä). Piirretään nämä 2 muuttujaa:
plot(boost.boston,i="lstat")plot(boost.boston,i="rm")1. kuvaaja osoittaa, että mitä suurempi on alemman taloudellisen aseman ihmisten osuus lähiössä, sitä pienempi on asuntojen hintojen arvo. 2. kuvaaja osoittaa käänteisen suhteen huoneiden lukumäärän kanssa: keskimääräinen huoneiden lukumäärä talossa kasvaa, kun hinta nousee.
On aika ennustaa boostattu malli testiaineistolle. Tarkastellaan testin suorituskykyä puiden lukumäärän funktiona:
-
Aluksi tehdään puiden lukumäärän ruudukko 100:n askelin 100:sta 10 000:een.
-
Sitten ajetaan
predict-funktio boostattuun malliin. Se ottaa argumenttinan.treesja tuottaa testidatan ennustematriisin. -
Matriisin ulottuvuudet ovat 206 testihavaintoa ja 100 erilaista ennustevektoria 100:lla eri puun arvolla.
n.trees = seq(from = 100, to = 10000, by = 100)predmat = predict(boost.boston, newdata = boston, n.trees = n.trees)dim(predmat)
On aika laskea testivirhe jokaiselle ennustevektorille:
-
predmaton matriisi,medvon vektori, joten (predmat–medv) on erotusmatriisi. Voit käyttääapply-funktiota näiden neliöerojen sarakkeisiin (keskiarvo). Tämä laskisi sarakekohtaisen keskimääräisen neliövirheen ennustevektoreille. -
Sitten teet kuvaajan käyttäen samankaltaisia parametreja kuin Random Forestissa käytettiin. Se näyttäisi boosting error plotin.
boost.err = with(boston, apply( (predmat - medv)^2, 2, mean) )plot(n.trees, boost.err, pch = 23, ylab = "Mean Squared Error", xlab = "# Trees", main = "Boosting Test Error")abline(h = min(test.err), col = "red")
The boosting error pretty much drops down as the number of trees increases. Tämä on todiste siitä, että boosting on haluton ylisovittamaan. Otetaan kuvaajaan mukaan myös paras testivirhe randomForestista. Boostaus pääsee itse asiassa kohtuullisen paljon randomForestin testivirheen alapuolelle.
Conclusion
Se on siis tämän R-oppaan loppu päätöspuumallien rakentamisesta: luokittelupuut, satunnaismetsät ja boostatut puut. Jälkimmäiset 2 ovat tehokkaita menetelmiä, joita voit käyttää milloin tahansa tarpeen mukaan. Kokemukseni mukaan boosting yleensä päihittää RandomForestin, mutta RandomForest on helpompi toteuttaa. RandomForestissa ainoa viritysparametri on puiden lukumäärä, kun taas boostingissa tarvitaan puiden lukumäärän lisäksi useampia viritysparametreja, kuten kutistuma ja vuorovaikutussyvyys.
Jos haluat oppia lisää, käy katsomassa Machine Learning Toolbox -kurssimme R:lle.