Quantrium-oppaat
>

Tesseract on optinen merkintunnistusmoottori, jota voidaan käyttää eri käyttöjärjestelmissä. Se on vapaa ohjelmisto, joka on julkaistu Apache-lisenssillä. Alun perin Hewlett-Packard kehitti Tesseractin omana ohjelmistona 1980-luvulla, myöhemmin se julkaistiin avoimen lähdekoodin ohjelmistona vuonna 2005. Vuodesta 2006 lähtien sen kehittämistä on sponsoroinut Google. Tässä oppaassa käyn läpi vaiheet, joita noudatin asentaakseni Tesseractin Windows 10 -koneeseeni. Näytän myös, miten voit käyttää tesseractia komentoriviltä, kun olet onnistuneesti asentanut sen.
Asenntaaksesi Tesseract 4:n Windows-järjestelmäämme, siirry seuraavaan linkkiin:
Lataa windowsin suoritettava tiedosto napsauttamalla hyperlinkkiä nimeltä tesseract-ocr-w64-setup-v4.1.0.20190314.exe. Näyttöön tulee ilmoitus, jossa pyydetään tallentamaan exe-tiedosto nimeltä ”Tesseract-ocr-w64-setup-v4.1.0.20190314.exe”. Tallenna tämä .exe-tiedosto sinne, missä sinulla on tarpeeksi tallennustilaa.
Avaa tämä exe-tiedosto. Jos ikkuna kysyy ”Haluatko sallia tämän ohjelmiston tehdä muutoksia järjestelmääsi”, napsauta kyllä. Sinut ohjataan asennusosioon.
Paina Seuraava, klikkaa Hyväksyn ehdot ja sen jälkeen, kun olet valinnut kenelle ja kenelle haluat asentaa Tesseractin (kaikille, jotka käyttävät tätä tietokonetta / vain minulle. Voit valita jommankumman), klikkaa Seuraava.
Rastita ruudut, joissa lukee ”ScrollView” (Vieritysnäkymä), ”Training Tools” (Harjoittelutyökalut), ”Shortcuts creation (Pikakuvakkeiden luominen)” (Pikakuvakkeiden luominen), ja tärkeintä on lisätä ”Language data” (Kielitiedot). Näiden pitäisi olla oletusarvoisesti rastitettuna, mutta tee ne vain siltä varalta, että niitä ei ole rastitettu järjestelmässäsi.
Nyt jos haluat tehdä ennusteita vierailla kielillä, kuten japaniksi, kiinaksi, kurdiksi tai intialaisilla kielillä, kuten hindiksi, tamiliksi, bengaliksi jne. rastita myös ”additional script data” (lisäkirjoitustiedot) ja ”additional language data” (lisäkielitiedot). Jos haluat tehdä ennusteita vain englannin kielelle, sinun ei tarvitse rastittaa tätä vaihtoehtoa.
Klikkaa Seuraava. Valitse hakemisto, johon haluat asentaa Tesseractin. Oletusarvoisesti se näyttää minulle C:\Program Files\Tesseract-OCR ja sinne asensin sen. Voit asentaa sen valintasi mukaan. Ota kuitenkin huomioon polku, johon olet asentanut Tesseractin koneellesi. Tämä on tärkeää.
Nyt voit valita Käynnistä-valikon kansion, johon haluat luoda ohjelmien pikakuvakkeen. Minä loin sen kansioon nimeltä ”Tesseract-OCR”. Jos haluat sen uuteen kansioon, kirjoita kansion nimi tyhjään tilaan oikealle ”Valitse Käynnistä-valikon kansio, johon haluat ….” -tekstin alle.
Voit myös rastittaa vasemmassa alareunassa olevan ”Älä luo pikakuvakkeita” -ruudun, jos et halua luoda mitään pikakuvakkeita. Kun olet valinnut haluamasi vaihtoehdon, napsauta Asenna. Asennuksen pitäisi kestää muutama minuutti.
Kun asennus on valmis, siirry hakemistoon, johon olet asentanut Tesseractin. Haluamme käyttää Tesseractia Windowsin komentoriviltä ja sitä varten meidän on lisättävä Tesseract polkuumme järjestelmän ympäristömuuttujaan.
Tehdäksesi niin, klikkaa Windowsin Käynnistä-painiketta ja etsi ”ympäristömuuttuja”. Näet tuloksen ”Muokkaa järjestelmän ympäristömuuttujia”. Klikkaa sitä. Kun olet napsauttanut tätä, sinun pitäisi olla ”Järjestelmän ominaisuudet” -osion ”Lisäasetukset” -kohdassa ja oikeassa alareunassa pitäisi näkyä painike nimeltä ”Ympäristömuuttujat ….”. Klikkaa tuota painiketta.
Nyt näet tässä kaksi taulukkoa. Toisen nimi on User variables for <username>. Tässä <username> on muuttuja, joka tarkoittaa PC:tä tällä hetkellä käyttävää käyttäjänimeä. Toinen taulukko on nimeltään ”Järjestelmämuuttujat”. Napsauta ”System variables” -taulukossa muuttujaa nimeltä ”Path” ja napsauta sitten tätä painiketta nimeltä ”Edit” (Muokkaa) aivan ”OK”-painikkeen yläpuolella, kuten alla olevassa kuvakaappauksessa näkyy.
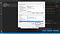
Kun olet saanut tämän tehtyä, saat näkyviin sivun nimeltä ”Muokkaa ympäristömuuttuja”. Täällä oikeassa yläkulmassa näet painikkeen nimeltä ”New”. Napsauta tuota ”New”-painiketta. Saat tyhjän tilan, johon voit lisätä tekstiä. Lisää tähän hakemistosi nimi, johon kaikki Tesseract-OCR-tiedostot on tallennettu.
Kun olet kirjoittanut hakemiston nimen, paina ”Enter” ja tarkista, onko hakemistosi nimi lisätty ”Edit environment variable table” -taulukkoon. Kun se on lisätty, napsauta ”OK”. Napsauta OK uudelleen ”Ympäristömuuttujat”-sivulla. Napsauta ”OK” ”Järjestelmän ominaisuudet” -sivulla uudelleen. Sinun on nyt poistuttava kaikista asetusvaihtoehdoista.
Avaa komentorivi ja kirjoita komentoriville tesseract --version ja paina enteriä. Näet jotain tällaista:
Jos näet virheen tesseract command not found kaltaisen virheen, olet luultavasti tehnyt jonkun virheen seuratessasi tätä opasta. Palaa takaisin ja katso, missä olet mennyt pieleen ja yritä korjata se. Vaihtoehtoisesti voit toistaa koko prosessin uudelleen.
Hienoa! Nyt sinulla on Tesseract asennettuna koneellesi. Voit alkaa leikkiä sillä ja tutkia sitä tarkemmin.
How to use Tesseract 4 using Command Line on a Windows Machine
Aluksi varmista, että sinulla on jokin käsinkirjoitettu asiakirja tai jokin koneella kirjoitettu asiakirja kuvan muodossa. Oletetaan, että sinulla on työpöydälläsi jokin png-muotoinen kuva nimeltä handwritten_photo_1 ja haluat testata Tesseractia sen avulla. Avaa komentorivi. Aloitat tästä hakemistosta:
C:\Users\username>
jossa username on käyttäjänimesi kyseisessä järjestelmässä. Minun on mentävä työpöydän hakemistoon. Käytän siis seuraavaa komentoa:
C:\Users\username> cd Desktop
Nyt olen Desktop-hakemistossa, jossa kuvani sijaitsee. Voit nähdä, mitä Tesseract ennustaa asiakirjan tekstiksi seuraavalla komennolla:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseract tulostaa tekstin suoraan itse komentoriville. Parametrilla -l määritetään kieli. Tässä olemme määritelleet sen englanniksi, joka on joka tapauksessa oletusarvoisesti käytössä, joten -l eng:n käyttäminen oli tässä tapauksessa tarpeetonta. Jos haluat käyttää jotain muuta kieltä OCR:ää varten, tarkista tämä linkki, jossa on kaikki .traineddata-tiedostot, jotka määrittelevät kielen:
Esimerkiksi sinulla on hindiksi kirjoitettu tekstiasiakirja. Mene sitten tähän yllä olevaan linkkiin, napsauta tiedostoa hin.traineddata ja lataa se. Kun olet ladannut sen, sinun on siirrettävä ”tessdata”-kansioon, joka on hakemistosi sisällä, johon olit alun perin asentanut tesseractin. Kun olet tehnyt tämän, voit suorittaa Hindi-asiakirjojen OCR-tulostuksen käyttämällä seuraavaa komentoa:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
Sen sijaan, että näyttäisit OCR-tulostuksen itse komentorivillä, sanotaan, että haluat OCR-tulostuksen tallentuvan tekstitiedostoon. Siinä tapauksessa voit sen sijaan antaa seuraavan komennon:
tesseract handwritten_photo_1.png output.txt
Teksti handwritten_photo_1.png tallennetaan tekstitiedostoon nimeltä output.txt, joka sijaitsee nykyisessä työhakemistossasi, joka minun tapauksessani oli Desktop.
Tesseract voi ottaa syötteenä myös tekstitiedoston, jossa tekstin on sisällettävä kaikki niiden kuvien absoluuttiset polut, joita haluat käsitellä.
Tämä on erityisen hyödyllistä silloin, kun sinulla on vaikkapa kaksi englanninkielistä käsinkirjoitettua kuvaa handwritten_photo_1.png ja handwritten_photo_2.png hakemistossa C:\Program Files. Nyt sinulla on nykyisessä työhakemistossasi tekstitiedosto nimeltä input.txt, jonka sisältö on:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
Ensimmäisellä ja toisella rivillä vastaavasti.
Nyt jos haluat tallentaa näiden kahden käsinkirjoitetun kuvan sisällön tekstitiedostoon, voit tehdä vain seuraavasti:
tesseract input.txt output.txt -l eng
output.txt saat OCR-sisällön molemmista kuvista handwritten_photo_1.png ja handwritten_photo_2.png, tässä järjestyksessä. Tässä kannattaa huomata, että input.txt oli nykyisessä työhakemistossa. Voit käyttää tesseractia myös sellaiseen tekstitiedostoon, joka ei ole nykyisessä työhakemistossasi, lisäämällä hakemiston sijainnin kuten tässä:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt on taas nykyisessä työhakemistossa. Voit tehdä tämän myös useammalle kuin kahdelle valokuvalle. Huomaa, että output.txt-tiedostossa olevan uuden valokuvan ennustetta edeltää jokin symboli kuten esim:
Tässä tapauksessa siis Viral Calic on ensimmäisen kuvan ennuste, CY am the king of the world toisen kuvan ennuste, Com and Serr kolmannen kuvan ennuste ja niin edelleen. Voit tarkistaa tuloksen kaikille syöttämillesi kuville ja tarkistaa ennusteiden tarkkuuden.
Se on siinä! Onnittelut, olet nyt valmis käyttämään Tesseractia Windows 10 -järjestelmässäsi.