Quantrium Guides
.

Tesseract to silnik optycznego rozpoznawania znaków, który może być używany w różnych systemach operacyjnych. Jest to wolne oprogramowanie, wydane na licencji Apache. Pierwotnie, Tesseract został opracowany przez Hewlett-Packard jako oprogramowanie własnościowe w latach 80-tych, później, w 2005 roku, został wydany jako oprogramowanie open source. Następnie, od 2006 roku, jego rozwój jest sponsorowany przez Google. W tym przewodniku przeprowadzę Cię przez kroki, które wykonałem, aby zainstalować Tesseract na moim komputerze z systemem Windows 10. Pokażę wam również, jak można korzystać z tesseract z wiersza poleceń po pomyślnym zainstalowaniu go.
Aby zainstalować Tesseract 4 na naszym systemie Windows, przejdź do następującego linku:
Ściągnij plik wykonywalny Windows, klikając hiperłącze zatytułowane tesseract-ocr-w64-setup-v4.1.0.20190314.exe. Pojawi się powiadomienie z prośbą o zapisanie pliku exe o nazwie „Tesseract-ocr-w64-setup-v4.1.0.20190314.exe”. Zapisz ten plik .exe gdziekolwiek masz wystarczająco dużo miejsca do przechowywania.
Otwórz ten plik exe. Jeśli w oknie pojawi się pytanie „Czy chcesz zezwolić temu oprogramowaniu na wprowadzenie zmian w systemie”, kliknij „Tak”. Zostaniesz przeniesiony do sekcji instalacji.
Kliknij Next, kliknij I agree to the terms and conditions and after selecting for whom and all you want to install Tesseract (anyone using this computer/just for me. You can select either one), click next.
Tick the boxes that say „ScrollView”, „Training Tools”, „Shortcuts creation” and importantly „Language data”. Powinny one być domyślnie zaznaczone, ale zrób to na wszelki wypadek, gdyby nie były zaznaczone w twoim systemie.
Teraz, jeśli chcesz tworzyć przewidywania w językach obcych, takich jak japoński, chiński, kurdyjski lub językach indyjskich, takich jak hindi, tamilski, bengalski itp. zaznacz również „dodatkowe dane skryptów” i „dodatkowe dane językowe”. Jeśli chcesz tworzyć prognozy tylko dla języka angielskiego, nie musisz zaznaczać tej opcji.
Kliknij Dalej. Wybierz katalog, w którym chcesz zainstalować Tesseract. Domyślnie pokazuje C:\Program Files\Tesseract-OCR dla mnie i tam właśnie go zainstalowałem. Możesz zainstalować go według własnego uznania. Ale zwróć uwagę na ścieżkę, gdzie zainstalowałeś Tesseract na swoim komputerze. To jest ważne.
Teraz możesz wybrać folder menu start, w którym chcesz utworzyć skrót do programów. Ja utworzyłem go w folderze o nazwie „Tesseract-OCR”. Jeśli chcesz go w nowym folderze, po prostu wpisz nazwę folderu w puste miejsce tuż pod tekstem „Wybierz folder menu Start, w którym chcesz ….”.
Możesz również zaznaczyć pole „Nie twórz skrótów” w lewym dolnym rogu, jeśli nie chcesz tworzyć żadnych skrótów. Po zakończeniu wybierania preferowanej opcji, kliknij zainstaluj. Instalacja powinna potrwać kilka minut.
Po zakończeniu instalacji przejdź do katalogu, w którym zainstalowałeś swój Tesseract. Chcemy używać Tesseract z naszego wiersza poleceń systemu Windows i aby to zrobić, musimy dodać Tesseract do naszej ścieżki w zmiennej środowiskowej systemu.
Aby to zrobić, kliknij na przycisk start w systemie Windows i wyszukaj „zmienna środowiskowa”. Zobaczysz wynik o nazwie „Edytuj zmienne środowiskowe systemu”. Kliknij na to. Po kliknięciu na to, powinieneś być w sekcji „Zaawansowane” „Właściwości systemu” i przycisk o nazwie „Zmienne środowiskowe ….” powinien być widoczny na dole po prawej stronie. Kliknij na ten przycisk.
Teraz zobaczysz tutaj dwie tabele. Jedna o nazwie User variables for <username>. Tutaj <username> jest zmienną, która oznacza nazwę użytkownika, który aktualnie korzysta z komputera. Druga tabela nazywa się „Zmienne systemowe”. W tabeli „Zmienne systemowe” kliknij na zmienną o nazwie „Ścieżka”, a następnie kliknij ten przycisk o nazwie „Edytuj” tuż nad przyciskiem „OK”, jak pokazano na poniższym zrzucie ekranu.
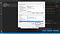
Gdy skończysz z tym, zobaczysz stronę o nazwie „Edytuj zmienną środowiskową”. Tutaj, w prawym górnym rogu, zobaczysz przycisk o nazwie „Nowy”. Kliknij na ten przycisk „Nowy”. Pojawi się puste miejsce, gdzie można dodać trochę tekstu. Tutaj dodaj nazwę katalogu, w którym przechowywane są wszystkie pliki Tesseract-OCR.
Po wpisaniu nazwy katalogu, naciśnij „Enter” i sprawdź, czy nazwa katalogu została dodana do „Tabeli zmiennych środowiskowych”. Gdy tak się stało, kliknij „OK”. Kliknij ponownie na OK na stronie „Zmienne środowiskowe”. Ponownie kliknij „OK” na stronie „Właściwości systemu”. Musisz mieć wyszedł z wszystkich opcji ustawień teraz.
Otwórz wiersz poleceń i wpisz tesseract --version w wierszu poleceń i naciśnij enter. Zobaczysz coś takiego:
Jeśli widzisz jakikolwiek błąd jak tesseract command not found, najprawdopodobniej popełniłeś jakiś błąd podczas podążania za tym przewodnikiem. Wróć i zobacz gdzie popełniłeś błąd i spróbuj go naprawić. Alternatywnie, możesz powtórzyć cały proces jeszcze raz.
Dobrze! Teraz masz Tesseract zainstalowany na swoim komputerze. Możesz zacząć bawić się z nim i zbadać go dalej.
Jak korzystać z Tesseract 4 używając Wiersza poleceń na maszynie Windows
Po pierwsze, upewnij się, że masz jakiś odręczny dokument lub jakiś wpisany dokument w formie obrazu. Załóżmy, że masz jakieś zdjęcie w formie png o nazwie handwritten_photo_1 na pulpicie i chcesz przetestować Tesseract z nim. Otwórz wiersz poleceń. Zaczniesz w tym katalogu:
C:\Users\username>
gdzie username jest twoją nazwą użytkownika w tym systemie. Muszę przejść do katalogu z pulpitem. Więc używam następującego polecenia:
C:\Users\username> cd Desktop
Teraz jestem w katalogu Desktop, gdzie znajduje się mój obraz. Możesz zobaczyć, co Tesseract przewiduje tekst w dokumencie za pomocą następującego polecenia:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseract będzie bezpośrednio wyprowadzać tekst w samym wierszu poleceń. Parametr -l jest używany do określenia języka. Tutaj określiliśmy go jako angielski, który i tak jest domyślny, więc użycie -l eng było zbędne w tym przypadku. Jeśli chcesz użyć innego języka dla OCR, sprawdź ten link tutaj, który ma wszystkie pliki .traineddata, które określają język:
Powiedzmy, że masz dokument tekstowy napisany w języku hindi. Następnie przejdź do tego powyższego linku, kliknij na plik o tytule hin.traineddata i pobierz go. Po pobraniu pliku należy przenieść go do folderu „tessdata”, który będzie znajdował się w katalogu, w którym pierwotnie zainstalowano program tesseract. Po wykonaniu tych czynności, można wykonać OCR dokumentów Hindi za pomocą następującego polecenia:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
Zamiast wyświetlać wynik OCR w wierszu poleceń, powiedzmy, że chcesz, aby wynik OCR był przechowywany w pliku tekstowym. W takim przypadku możesz wpisać następujące polecenie:
tesseract handwritten_photo_1.png output.txt
Tekst w handwritten_photo_1.png zostanie zapisany w pliku tekstowym o nazwie output.txt, który będzie znajdował się w twoim obecnym katalogu roboczym, którym w moim przypadku był Pulpit.
Tesseract może również przyjąć plik tekstowy jako dane wejściowe, gdzie tekst musi zawierać wszystkie bezwzględne ścieżki do obrazów, które chcesz przetworzyć.
Jest to szczególnie przydatne, gdy, powiedzmy, masz dwa obrazy napisane odręcznie w języku angielskim o nazwach handwritten_photo_1.png i handwritten_photo_2.png w katalogu C:\Program Files. Teraz, w twoim obecnym katalogu roboczym, masz plik tekstowy o nazwie input.txt, którego zawartość to:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
Odpowiednio w pierwszej i drugiej linii.
Teraz, jeśli chcesz przechowywać zawartość tych dwóch odręcznie napisanych zdjęć w pliku tekstowym, możesz po prostu wykonać następujące czynności:
tesseract input.txt output.txt -l eng
output.txt będzie mieć zawartość OCR obu handwritten_photo_1.png i handwritten_photo_2.png, w tej kolejności. W tym miejscu należy zauważyć, że input.txt znajdował się w bieżącym katalogu roboczym. Możesz użyć tesseract na pliku tekstowym, który nie znajduje się w bieżącym katalogu roboczym, włączając lokalizację katalogu, jak tutaj:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt ponownie będzie znajdować się w bieżącym katalogu roboczym. Można to zrobić również dla więcej niż dwóch zdjęć. Zauważ, że zapowiedź nowego zdjęcia w pliku output.txt będzie poprzedzona jakimś symbolem, jak np:
Więc w tym przypadku, Viral Calic jest predykcją dla pierwszego zdjęcia, CY am the king of the world predykcją dla drugiego zdjęcia, Com and Serr predykcją dla trzeciego zdjęcia i tak dalej. Możesz sprawdzić dane wyjściowe dla wszystkich obrazów wejściowych i sprawdzić dokładność przewidywań.
To jest to! Gratulacje, teraz wszystko jest gotowe do użycia Tesseract w systemie Windows 10.
.