Wprowadzenie
Zrozumienie zachowań klientów w każdej branży jest kluczowe. Zdałem sobie z tego sprawę w zeszłym roku, kiedy mój szef marketingu zapytał mnie – „Czy możesz mi powiedzieć, którzy istniejący klienci powinni być celem dla naszego nowego produktu?”
To była dla mnie dość krzywa uczenia się. Szybko zdałem sobie sprawę, jak ważne jest segmentowanie klientów, aby moja organizacja mogła dopasować i zbudować ukierunkowane strategie. To właśnie tutaj koncepcja klastrowania okazała się bardzo przydatna!
Problemy takie jak segmentacja klientów są często zwodniczo podchwytliwe, ponieważ nie pracujemy z żadną zmienną docelową w umyśle. Oficjalnie znajdujemy się w krainie uczenia nienadzorowanego, gdzie musimy rozgryźć wzorce i struktury bez ustalonego wyniku w umyśle. Jest to zarówno wymagające, jak i ekscytujące dla naukowca zajmującego się danymi.
Teraz istnieje kilka różnych sposobów na wykonanie grupowania (jak zobaczysz poniżej). W tym artykule przedstawię Ci jeden z takich typów – klasteryzację hierarchiczną.
Dowiemy się czym jest klasteryzacja hierarchiczna, jaka jest jej przewaga nad innymi algorytmami klasteryzacji, poznamy różne typy klasteryzacji hierarchicznej oraz kroki do jej wykonania. Na koniec zajmiemy się zbiorem danych segmentacji klientów, a następnie zaimplementujemy klasteryzację hierarchiczną w Pythonie. Uwielbiam tę technikę i jestem pewien, że po tym artykule ty też to zrobisz!
Uwaga: Jak wspomniano, istnieje wiele sposobów na przeprowadzenie klasteryzacji. Zachęcam do zapoznania się z naszym wspaniałym przewodnikiem po różnych typach klastrowania:
- Wprowadzenie do klastrowania i różne metody klastrowania
Aby dowiedzieć się więcej o klastrowaniu i innych algorytmach uczenia maszynowego (zarówno nadzorowanych jak i nienadzorowanych) sprawdź następujący kompleksowy program-.
- Certified AI & ML Blackbelt+ Program
Table of Contents
- Supervised vs Unsupervised Learning
- Why Hierarchical Clustering?
- Co to jest klasteryzacja hierarchiczna?
- Types of Hierarchical Clustering
- Agglomerative Hierarchical Clustering
- Divisive Hierarchical Clustering
- Steps to perform Hierarchical Clustering
- How to Choose the Number of Clusters in Hierarchical Clustering?
- Rozwiązanie problemu segmentacji klientów hurtowych przy użyciu klastrowania hierarchicznego
Uczenie nadzorowane vs nienadzorowane
Ważne jest, aby zrozumieć różnicę pomiędzy uczeniem nadzorowanym i nienadzorowanym, zanim zagłębimy się w klasteryzację hierarchiczną. Pozwól mi wyjaśnić tę różnicę na prostym przykładzie.
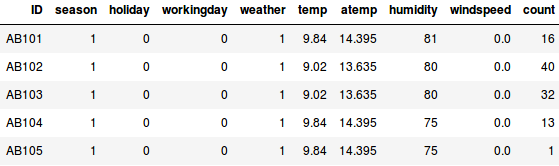
Załóżmy, że chcemy oszacować liczbę rowerów, które zostaną wypożyczone w mieście każdego dnia:
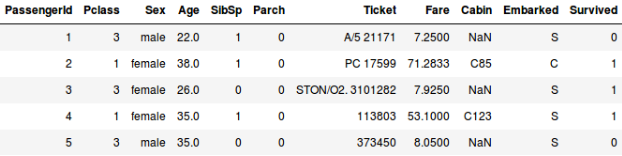
Albo, powiedzmy, że chcemy przewidzieć, czy osoba na pokładzie Titanica przeżyła, czy nie:
Mamy ustalony cel do osiągnięcia w obu tych przykładach:
- W pierwszym przykładzie musimy przewidzieć liczbę rowerów na podstawie cech takich jak pora roku, święto, dzień roboczy, pogoda, temp itp.
- W drugim przykładzie przewidujemy, czy pasażer przeżył, czy nie. W zmiennej „Przeżył” 0 oznacza, że dana osoba nie przeżyła, a 1 oznacza, że udało jej się wydostać żywą. Zmienne niezależne obejmują tutaj Pclass, Sex, Age, Fare, etc.
Więc, kiedy otrzymujemy zmienną docelową (count i Survival w dwóch powyższych przypadkach), którą musimy przewidzieć w oparciu o dany zestaw predyktorów lub zmiennych niezależnych (sezon, wakacje, Sex, Age, etc.), takie problemy nazywane są problemami uczenia nadzorowanego.
Spójrzmy na poniższy rysunek, aby zrozumieć to wizualnie:
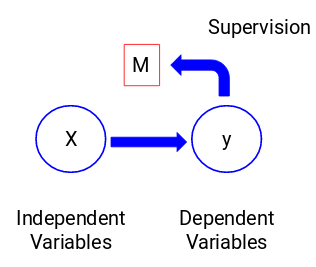
Tutaj, y jest naszą zmienną zależną lub docelową, a X reprezentuje zmienne niezależne. Zmienna docelowa jest zależna od X i dlatego jest również nazywana zmienną zależną. Szkolimy nasz model używając zmiennych niezależnych w nadzorze zmiennej docelowej i stąd nazwa uczenie nadzorowane.
Naszym celem, podczas szkolenia modelu, jest wygenerowanie funkcji, która mapuje zmienne niezależne do pożądanego celu. Gdy model jest już wytrenowany, możemy przekazywać nowe zestawy obserwacji, a model będzie dla nich przewidywał cel. To, w dużym uproszczeniu, jest uczenie nadzorowane.
Mogą zdarzyć się sytuacje, w których nie mamy żadnej zmiennej docelowej do przewidzenia. Takie problemy, bez żadnej jawnej zmiennej docelowej, nazywamy problemami uczenia nienadzorowanego. Mamy tylko zmienne niezależne i nie mamy zmiennej docelowej/zależnej w tych problemach.

Próbujemy w tych przypadkach podzielić całe dane na zbiór grup. Grupy te są znane jako klastry, a proces tworzenia tych klastrów jest znany jako klastrowanie.
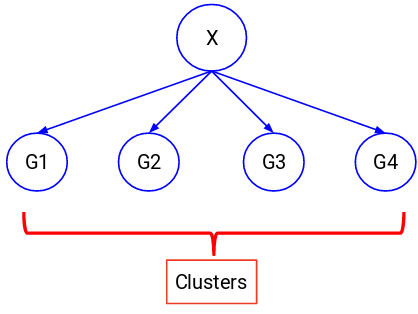
Ta technika jest ogólnie stosowana do grupowania populacji na różne grupy. Kilka typowych przykładów to segmentacja klientów, grupowanie podobnych dokumentów razem, polecanie podobnych piosenek lub filmów, itp.
Istnieje o wiele więcej zastosowań uczenia nienadzorowanego. Jeśli natkniesz się na jakieś ciekawe zastosowanie, nie krępuj się podzielić nimi w sekcji komentarzy poniżej!
Teraz istnieją różne algorytmy, które pomagają nam tworzyć te klastry. Najczęściej używanymi algorytmami klastrowania są K-means i klastrowanie hierarchiczne.
Dlaczego klastrowanie hierarchiczne?
Powinniśmy najpierw wiedzieć, jak działa K-means, zanim zanurkujemy w klastrowanie hierarchiczne. Zaufaj mi, to sprawi, że koncepcja hierarchicznego grupowania będzie tym łatwiejsza.
Oto krótki przegląd tego, jak działa K-means:
- Decydujemy o liczbie klastrów (k)
- Wybieramy k losowych punktów z danych jako centroidy
- Przypisujemy wszystkie punkty do. najbliższej centroidy klastra
- Oblicz centroidy nowo utworzonych klastrów
- Powtórz kroki 3 i 4
Jest to proces iteracyjny. Będzie on działał aż do momentu, gdy centroidy nowo utworzonych klastrów nie zmienią się lub osiągnięta zostanie maksymalna liczba iteracji. Zawsze stara się tworzyć klastry o tym samym rozmiarze. Ponadto, musimy zdecydować o liczbie klastrów na początku algorytmu. Idealnie, nie wiedzielibyśmy, ile klastrów powinniśmy mieć, na początku algorytmu i stąd to wyzwanie z K-means.
To jest luka hierarchiczne mosty klastrowania z aplomb. Zdejmuje problem konieczności wstępnego zdefiniowania liczby klastrów. Brzmi jak marzenie! Zobaczmy więc, czym jest klastrowanie hierarchiczne i jak poprawia się ono w stosunku do K-means.
Co to jest klastrowanie hierarchiczne?
Powiedzmy, że mamy poniższe punkty i chcemy je pogrupować w grupy:

Możemy przypisać każdy z tych punktów do osobnego klastra:

Teraz, na podstawie podobieństwa tych klastrów, możemy połączyć najbardziej podobne klastry razem i powtarzać ten proces, aż pozostanie tylko jeden klaster:
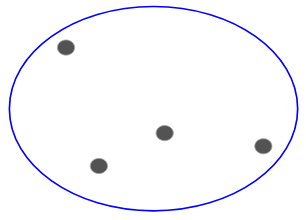
W zasadzie budujemy hierarchię klastrów. Dlatego algorytm ten nazywany jest klasteryzacją hierarchiczną. O tym, jak decydować o liczbie klastrów, opowiem w dalszej części rozdziału. Na razie przyjrzyjmy się różnym typom klastrowania hierarchicznego.
Typy klastrowania hierarchicznego
Istnieją głównie dwa typy klastrowania hierarchicznego:
- Agglomeracyjne klastrowanie hierarchiczne
- Dywizjonistyczne klastrowanie hierarchiczne
Zrozummy każdy typ szczegółowo.
Agglomeracyjne grupowanie hierarchiczne
W tej technice przypisujemy każdy punkt do indywidualnego klastra. Załóżmy, że istnieją 4 punkty danych. Przypiszemy każdy z tych punktów do klastra i w ten sposób będziemy mieli 4 klastry na początku:
Następnie, w każdej iteracji, łączymy najbliższą parę klastrów i powtarzamy ten krok, aż pozostanie tylko jeden klaster:
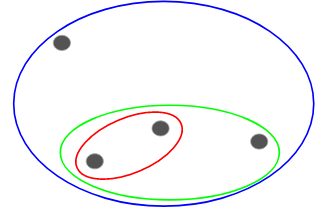
Łączymy (lub dodajemy) klastry na każdym kroku, prawda? Stąd ten typ klastrowania jest również znany jako addytywne klastrowanie hierarchiczne.
Divisive Hierarchical Clustering
Divisive hierarchical clustering działa w odwrotny sposób. Zamiast zaczynać od n klastrów (w przypadku n obserwacji), zaczynamy od jednego klastra i przypisujemy wszystkie punkty do tego klastra.
Nie ma więc znaczenia, czy mamy 10 czy 1000 punktów danych. Wszystkie te punkty będą należeć do tego samego klastra na początku:
Teraz, w każdej iteracji, dzielimy najdalszy punkt w klastrze i powtarzamy ten proces, aż każdy klaster będzie zawierał tylko jeden punkt:
Podzielimy (lub podzielimy) klastry na każdym kroku, stąd nazwa divisive hierarchical clustering.
Klasteryzacja aglomeracyjna jest szeroko stosowana w przemyśle i to na niej skupimy się w tym artykule. Podzielne grupowanie hierarchiczne będzie bułką z masłem, gdy już poznamy typ aglomeracyjny.
Kroki do wykonania grupowania hierarchicznego
Połączymy najbardziej podobne punkty lub klastry w grupowaniu hierarchicznym – wiemy o tym. Teraz pytanie brzmi – jak zdecydować, które punkty są podobne, a które nie? Jest to jedno z najważniejszych pytań w klasteryzacji!
Jest jeden sposób na obliczenie podobieństwa – Weź odległość między centroidami tych klastrów. Punkty mające najmniejszą odległość są określane jako punkty podobne i możemy je połączyć. Możemy odnieść się do tego jako do algorytmu opartego na odległości (ponieważ obliczamy odległości między klastrami).
W klasteryzacji hierarchicznej mamy pojęcie zwane macierzą bliskości. To przechowuje odległości między każdym punktem. Weźmy przykład, aby zrozumieć tę macierz, jak również kroki do wykonania hierarchicznego grupowania.
Ustalanie przykładu

Załóżmy, że nauczyciel chce podzielić swoich uczniów na różne grupy. Ma oceny zdobyte przez każdego ucznia w zadaniu i na podstawie tych ocen chce podzielić ich na grupy. Nie ma ustalonego celu co do ilości grup. Ponieważ nauczyciel nie wie, jaki typ studentów powinien być przydzielony do jakiej grupy, nie można rozwiązać tego problemu jako problemu uczenia się nadzorowanego. Spróbujemy więc zastosować tutaj klastrowanie hierarchiczne i podzielić uczniów na różne grupy.
Pobierzmy próbkę 5 uczniów:
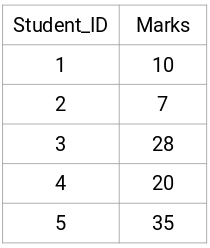
Tworzenie macierzy bliskości
Po pierwsze, utworzymy macierz bliskości, która powie nam, jaka jest odległość między każdym z tych punktów. Ponieważ obliczamy odległość każdego punktu od każdego z pozostałych punktów, otrzymamy macierz kwadratową o kształcie n X n (gdzie n jest liczbą obserwacji).
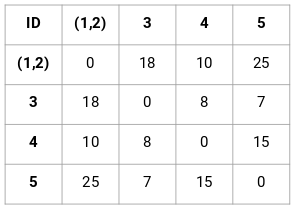
Utwórzmy macierz bliskości 5 x 5 dla naszego przykładu:
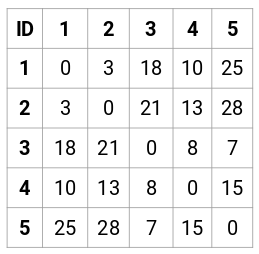
Elementy diagonalne tej macierzy będą zawsze równe 0, ponieważ odległość punktu od samego siebie jest zawsze równa 0. Do obliczenia pozostałych odległości użyjemy wzoru na odległość euklidesową. Załóżmy więc, że chcemy obliczyć odległość między punktem 1 i 2:
√(10-7)^2 = √9 = 3
Podobnie możemy obliczyć wszystkie odległości i wypełnić macierz bliskości.
Kroki do wykonania grupowania hierarchicznego
Krok 1: Po pierwsze, przypisujemy wszystkie punkty do indywidualnego klastra:
![]()
Różne kolory reprezentują tutaj różne klastry. Możesz zobaczyć, że mamy 5 różnych klastrów dla 5 punktów w naszych danych.
Krok 2: Następnie spojrzymy na najmniejszą odległość w macierzy bliskości i połączymy punkty z najmniejszą odległością. Następnie zaktualizujemy macierz bliskości:
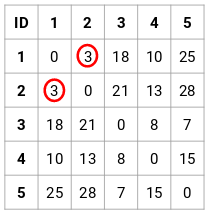
Tutaj najmniejsza odległość wynosi 3, a zatem połączymy punkty 1 i 2:
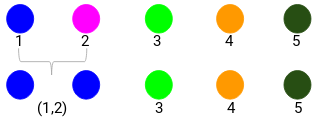
Spójrzmy na zaktualizowane klastry i odpowiednio zaktualizujmy macierz bliskości:
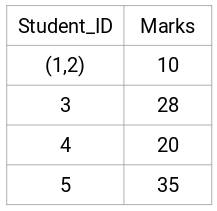
Tutaj wzięliśmy maksimum dwóch znaków (7, 10), aby zastąpić znaki dla tego klastra. Zamiast maksimum, możemy również wziąć wartość minimalną lub średnią. Teraz ponownie obliczymy macierz bliskości dla tych klastrów:
Krok 3: Powtarzamy krok 2, aż pozostanie tylko jeden klaster.
Więc najpierw spojrzymy na minimalną odległość w macierzy bliskości, a następnie połączymy najbliższe pary klastrów. Otrzymamy połączone klastry, jak pokazano poniżej, po powtórzeniu tych kroków:
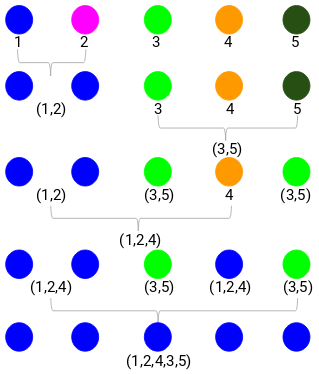
Zaczęliśmy od 5 klastrów i w końcu mamy jeden klaster. Tak właśnie działa aglomeracyjne grupowanie hierarchiczne. Ale wciąż pozostaje palące pytanie – jak zdecydować o liczbie klastrów? Zrozumiemy to w następnej sekcji.
Jak powinniśmy wybrać liczbę klastrów w klasteryzacji hierarchicznej?
Czy jesteś gotowy, aby w końcu odpowiedzieć na to pytanie, które wisi od początku naszej nauki? Aby uzyskać liczbę klastrów w klasteryzacji hierarchicznej, korzystamy z niesamowitej koncepcji zwanej dendrogramem.
Dendrogram jest drzewopodobnym diagramem, który rejestruje sekwencje połączeń lub podziałów.
Powróćmy do naszego przykładu nauczyciel-uczeń. Za każdym razem, gdy połączymy dwa skupiska, dendrogram zarejestruje odległość między tymi skupiskami i przedstawi ją w formie grafu. Zobaczmy jak wygląda dendrogram:
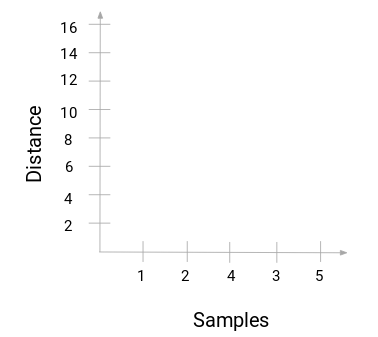
Na osi x mamy próbki zbioru danych, a na osi y odległość. Ilekroć dwa klastry są łączone, dołączymy je do tego dendrogramu, a wysokość połączenia będzie równa odległości między tymi punktami. Zbudujmy dendrogram dla naszego przykładu:
Poświęćmy chwilę na przetworzenie powyższego obrazu. Zaczęliśmy od połączenia próbki 1 i 2, a odległość pomiędzy tymi dwoma próbkami wynosiła 3 (odnieś się do pierwszej macierzy bliskości w poprzedniej sekcji). Wykreślmy to w dendrogramie:
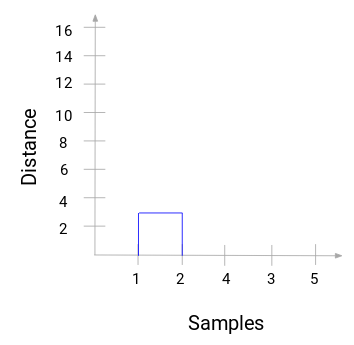
Tutaj widzimy, że połączyliśmy próbkę 1 i 2. Pionowa linia reprezentuje odległość pomiędzy tymi próbkami. Podobnie, wykreślamy wszystkie kroki, w których połączyliśmy klastry i w końcu otrzymujemy dendrogram taki jak ten:
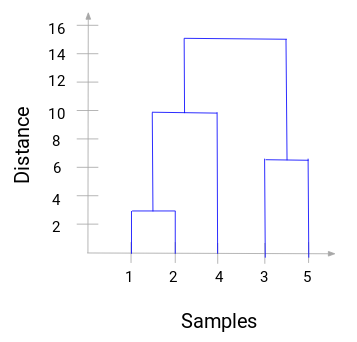
Możemy wyraźnie wizualizować kroki hierarchicznego grupowania. Większa odległość pionowych linii w dendrogramie, to większa odległość między tymi klastrami.
Teraz możemy ustawić odległość progową i narysować linię poziomą (Ogólnie rzecz biorąc, staramy się ustawić próg w taki sposób, aby przeciąć najwyższą linię pionową). Ustawmy ten próg jako 12 i narysujmy linię poziomą:
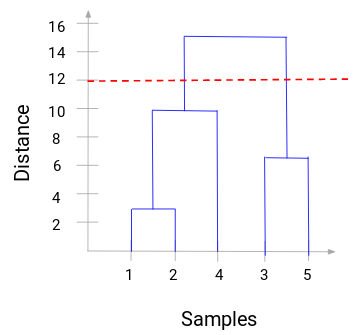
Liczba skupisk będzie liczbą pionowych linii, które są przecinane przez linię narysowaną przy użyciu progu. W powyższym przykładzie, ponieważ czerwona linia przecina 2 linie pionowe, będziemy mieli 2 klastry. Jeden klaster będzie miał próbkę (1,2,4), a drugi będzie miał próbkę (3,5). Całkiem proste, prawda?
W ten sposób możemy zdecydować o liczbie klastrów używając dendrogramu w Hierarchicznym Klasteryzowaniu. W następnej sekcji zaimplementujemy klastrowanie hierarchiczne, które pomoże Ci zrozumieć wszystkie koncepcje, których nauczyliśmy się w tym artykule.
Rozwiązanie problemu segmentacji klientów hurtowych przy użyciu klastrowania hierarchicznego
Czas ubrudzić sobie ręce w Pythonie!
Będziemy pracować nad problemem segmentacji klientów hurtowych. Możesz pobrać zestaw danych używając tego linku. Dane są przechowywane w repozytorium UCI Machine Learning. Celem tego problemu jest segmentacja klientów hurtowni w oparciu o ich roczne wydatki na różne kategorie produktów, takie jak mleko, artykuły spożywcze, region, itp.
Przede wszystkim zbadajmy dane, a następnie zastosujmy klasteryzację hierarchiczną do segmentacji klientów.
Najpierw zaimportujemy wymagane biblioteki:
Wczytaj dane i spójrz na kilka pierwszych wierszy:
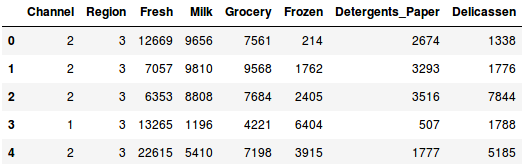
Jest wiele kategorii produktów – świeże, mleko, artykuły spożywcze, itd. Wartości reprezentują liczbę jednostek zakupionych przez każdego klienta dla każdego produktu. Naszym celem jest stworzenie klastrów z tych danych, które mogą segmentować podobnych klientów razem. Będziemy, oczywiście, używać Hierarchical Clustering dla tego problemu.
Ale przed zastosowaniem Hierarchical Clustering, musimy znormalizować dane tak, że skala każdej zmiennej jest taka sama. Dlaczego jest to ważne? Cóż, jeśli skala zmiennych nie jest taka sama, model może stać się stronniczy w kierunku zmiennych o wyższej wielkości, takich jak Świeże lub Mleko (patrz powyższa tabela).
Więc, najpierw znormalizujmy dane i przyprowadźmy wszystkie zmienne do tej samej skali:
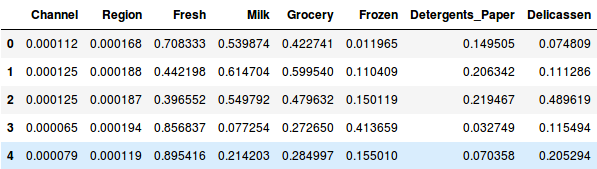
Tutaj widzimy, że skala wszystkich zmiennych jest prawie podobna. Teraz możemy przystąpić do pracy. Narysujmy najpierw dendrogram, który pomoże nam zdecydować o liczbie klastrów dla tego konkretnego problemu:
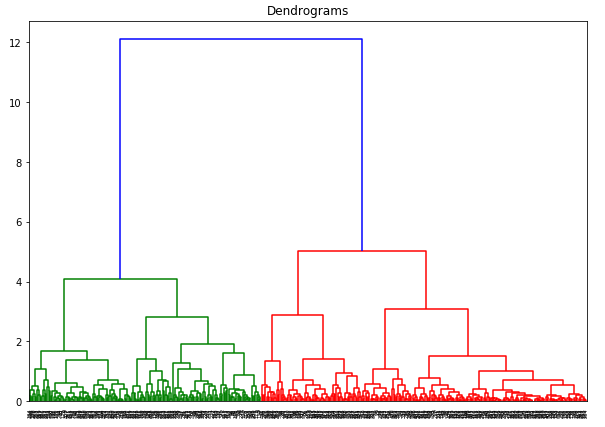
Oś x zawiera próbki, a oś y reprezentuje odległość między tymi próbkami. Pionowa linia z maksymalną odległością jest niebieską linią i dlatego możemy zdecydować się na próg 6 i przeciąć dendrogram:
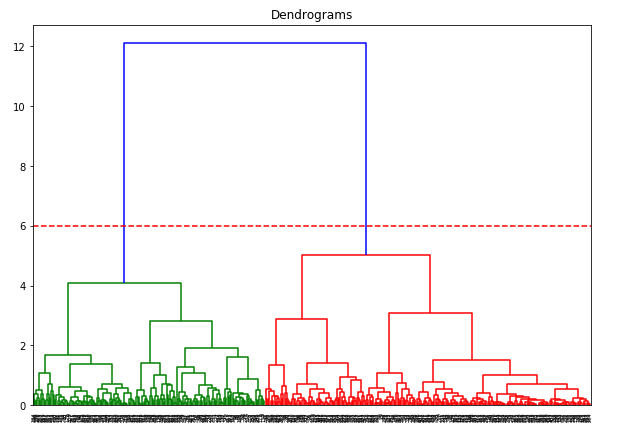
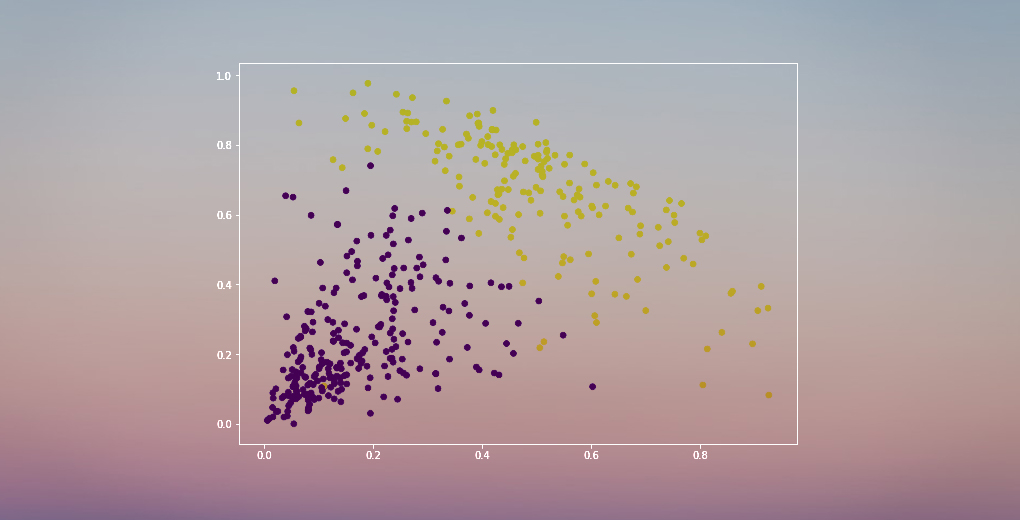
Mamy dwa klastry, ponieważ ta linia przecina dendrogram w dwóch punktach. Zastosujmy teraz grupowanie hierarchiczne dla 2 klastrów:
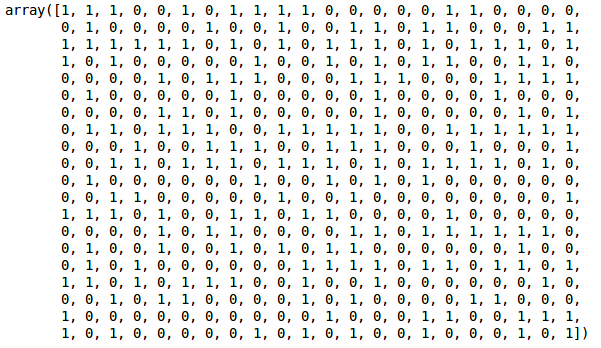
Możemy zobaczyć wartości 0s i 1s na wyjściu, ponieważ zdefiniowaliśmy 2 klastry. 0 reprezentuje punkty, które należą do pierwszego klastra, a 1 reprezentuje punkty w drugim klastrze. Zwizualizujmy teraz te dwa klastry:
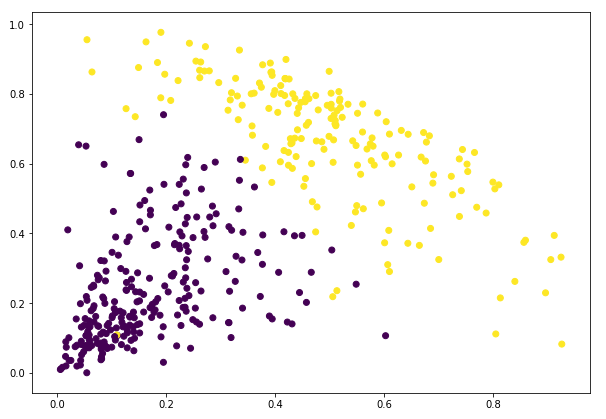
Absolutnie! Możemy tutaj wyraźnie zwizualizować dwa klastry. Oto jak możemy zaimplementować hierarchiczne grupowanie w Pythonie.
Uwagi końcowe
Hierarchiczne grupowanie jest bardzo użytecznym sposobem segmentacji obserwacji. Zaletą jest to, że nie trzeba wstępnie definiować liczby klastrów, co daje jej przewagę nad k-Means.
Jeśli jesteś jeszcze stosunkowo nowy w nauce o danych, gorąco polecam Ci kurs Applied Machine Learning. Jest to jeden z najbardziej kompleksowych, kompleksowych kursów uczenia maszynowego, jakie można znaleźć w dowolnym miejscu. Hierarchiczne grupowanie jest tylko jednym z wielu tematów, które poruszamy na kursie.
.