Introduction
É crucial compreender o comportamento do cliente em qualquer indústria. Percebi isso no ano passado quando meu diretor de marketing me perguntou – “Você pode me dizer quais clientes existentes devemos visar para o nosso novo produto?”
Isso foi uma curva de aprendizado e tanto para mim. Percebi rapidamente como cientista de dados o quanto é importante segmentar os clientes para que minha organização possa adaptar e construir estratégias direcionadas. Foi aqui que o conceito de clustering se tornou tão útil!
Problemas como segmentar clientes são muitas vezes enganosamente complicados porque não estamos trabalhando com nenhuma variável alvo em mente. Estamos oficialmente na terra da aprendizagem não supervisionada, onde precisamos de descobrir padrões e estruturas sem um resultado definido em mente. É tanto desafiador quanto emocionante como um cientista de dados.
Agora, existem algumas maneiras diferentes de realizar o agrupamento (como você verá abaixo). Vou apresentar um desses tipos neste artigo – o clustering hierárquico.
Aprenderemos o que é o clustering hierárquico, sua vantagem sobre os outros algoritmos de clustering, os diferentes tipos de clustering hierárquico e os passos para realizá-lo. Finalmente vamos pegar um conjunto de dados de segmentação de clientes e depois implementar o clustering hierárquico em Python. Eu adoro esta técnica e tenho certeza que você também vai adorar depois deste artigo!
Note: Como mencionado, existem várias maneiras de realizar o clustering. Eu os encorajo a checar nosso incrível guia para os diferentes tipos de clustering:
- Uma Introdução ao Clustering e diferentes métodos de clustering
Para saber mais sobre clustering e outros algoritmos de aprendizagem de máquinas (tanto supervisionados como não supervisionados) veja o seguinte programa abrangente…
>
- >
- AI certificado & ML Blackbelt+Programa
>
>
Tabela de conteúdos
- >
- Aprendizagem supervisionada vs. não supervisionada
- Porquê o agrupamento hierárquico?
- O que é o Agrupamento Hierárquico?
- Tipos de Agrupamento Hierárquico
- Aglomeração Hierárquica Aglomerativa
- Aglomeração Hierárquica Divisiva
- Passos para realizar Agrupamento Hierárquico
- Como Escolher o Número de Agrupamentos no Agrupamento Hierárquico?
- Solucionar um problema de segmentação de clientes por atacado usando o agrupamento hierárquico
>
Aprendizagem supervisionada vs. não supervisionada
É importante entender a diferença entre aprendizagem supervisionada e não supervisionada, antes de mergulharmos no agrupamento hierárquico. Deixe-me explicar esta diferença usando um exemplo simples.
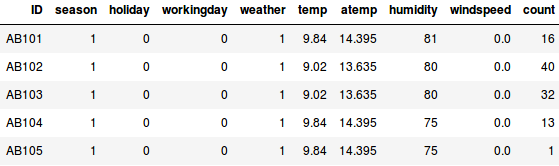
Se quisermos estimar a contagem de bicicletas que serão alugadas numa cidade todos os dias:
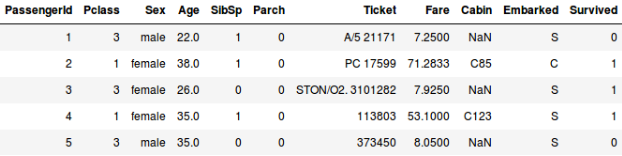
Or, digamos que queremos prever se uma pessoa a bordo do Titanic sobreviveu ou não:
Temos um objectivo fixo a atingir em ambos os exemplos:
- No primeiro exemplo, temos de prever a contagem de bicicletas com base em características como a estação do ano, feriados, dias de trabalho, tempo, temperatura, etc.
- No segundo exemplo, estamos a prever se um passageiro sobreviveu ou não. Na variável ‘Sobrevivido’, 0 representa que a pessoa não sobreviveu e 1 significa que a pessoa sobreviveu. As variáveis independentes aqui incluem a classe P, sexo, idade, tarifa, etc.
Então, quando nos é dada uma variável alvo (contagem e sobrevivência nos dois casos acima) que temos de prever com base num dado conjunto de preditores ou variáveis independentes (estação do ano, férias, sexo, idade, etc.)), tais problemas são chamados problemas de aprendizagem supervisionada.
Vejamos a figura abaixo para entender isso visualmente:
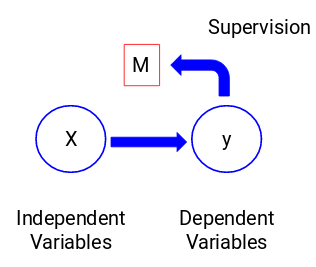
Aqui, y é nossa variável dependente ou alvo, e X representa as variáveis independentes. A variável alvo é dependente de X e por isso também é chamada de variável dependente. Treinamos o nosso modelo utilizando as variáveis independentes na supervisão da variável alvo e daí o nome de aprendizagem supervisionada.
O nosso objectivo, ao treinar o modelo, é gerar uma função que mapeia as variáveis independentes para o alvo desejado. Uma vez que o modelo é treinado, podemos passar novos conjuntos de observações e o modelo irá prever o alvo para elas. Isto, em resumo, é uma aprendizagem supervisionada.
Pode haver situações em que não temos nenhuma variável alvo a prever. Tais problemas, sem nenhuma variável alvo explícita, são conhecidos como problemas de aprendizagem não supervisionada. Temos apenas as variáveis independentes e nenhuma variável alvo/dependente nestes problemas.

Tentamos dividir os dados inteiros em um conjunto de grupos nestes casos. Estes grupos são conhecidos como clusters e o processo de fazer estes clusters é conhecido como clustering.
Esta técnica é geralmente usada para agrupar uma população em diferentes grupos. Alguns exemplos comuns incluem segmentar clientes, agrupar documentos semelhantes juntos, recomendar músicas ou filmes semelhantes, etc.
Há MUITO mais aplicações de aprendizagem não supervisionada. Se você encontrar alguma aplicação interessante, sinta-se livre para compartilhá-las na seção de comentários abaixo!
Agora, há vários algoritmos que nos ajudam a fazer esses clusters. Os algoritmos de clustering mais utilizados são K-means e Clustering Hierárquico.
Porquê Clustering Hierárquico?
Primeiro devemos saber como K-means funciona antes de mergulharmos no clustering hierárquico. Confie em mim, isso vai tornar o conceito de clustering hierárquico ainda mais fácil.
Aqui está uma breve visão geral de como K significaans funciona:
- Decidir o número de clusters (k)
- Selecionar k pontos aleatórios dos dados como centroides
- Atribuir todos os pontos ao cluster centroid mais próximo
- Calcular o centróide dos clusters recém-formados
- Repetição dos passos 3 e 4
É um processo iterativo. Ele continuará funcionando até que os centróides dos clusters recém-formados não mudem ou o número máximo de iterações seja alcançado.
Mas há certos desafios com K-sentidos. Ele sempre tenta fazer clusters do mesmo tamanho. Também temos que decidir o número de clusters no início do algoritmo. Idealmente, não saberíamos quantos clusters devemos ter, no início do algoritmo e por isso é um desafio com K-means.
Esta é uma lacuna hierárquica de pontes de clustering com aplomb. Ele tira o problema de ter que pré-definir o número de clusters. Soa como um sonho! Então, vamos ver o que é clustering hierárquico e como ele melhora em K-means.
O que é Clustering Hierárquico?
Vamos dizer que temos os pontos abaixo e queremos agrupá-los em grupos:

Podemos atribuir cada um destes pontos a um agrupamento separado:

Agora, com base na semelhança destes clusters, podemos combinar os clusters mais semelhantes e repetir este processo até restar apenas um único cluster:
Estamos essencialmente a construir uma hierarquia de clusters. É por isso que este algoritmo é chamado de clustering hierárquico. Irei discutir como decidir o número de clusters numa secção posterior. Por enquanto, vamos olhar para os diferentes tipos de agrupamento hierárquico.
Tipos de agrupamento hierárquico
Existem principalmente dois tipos de agrupamento hierárquico:
- Aglomeração hierárquica agregada
- Aglomeração hierárquica diversificada
Vamos compreender cada tipo em detalhe.
Aglomeração Hierárquica Aglomerada
Atribuímos cada ponto a um agrupamento individual nesta técnica. Suponha que existem 4 pontos de dados. Atribuiremos cada um desses pontos a um cluster e, portanto, teremos 4 clusters no início:
Então, a cada iteração, fundimos o par de clusters mais próximo e repetimos esta etapa até restar apenas um único cluster:
Estamos fundindo (ou adicionando) os clusters em cada etapa, certo? Portanto, este tipo de clustering também é conhecido como clustering hierárquico aditivo.
Clustering Hierárquico Divisivo
O clustering hierárquico divisivo funciona de forma oposta. Em vez de começar com n clusters (no caso de n observações), começamos com um único cluster e atribuímos todos os pontos a esse cluster.
Então, não importa se temos 10 ou 1000 pontos de dados. Todos esses pontos pertencerão ao mesmo cluster no início:
Agora, a cada iteração, dividimos o ponto mais distante no cluster e repetimos esse processo até que cada cluster contenha apenas um ponto:
Dividimos (ou dividimos) os clusters em cada etapa, daí o nome divisão hierárquica de clusters.
Agglomerado Aglomerado é amplamente utilizado na indústria e esse será o foco deste artigo. O agrupamento hierárquico divisivo será canja uma vez que tivermos um cabo do tipo aglomerativo.
Passos para Realizar o Agrupamento Hierárquico
Fundimos os pontos ou agrupamentos mais semelhantes no agrupamento hierárquico – sabemos disso. Agora a questão é – como decidimos que pontos são semelhantes e quais não são? É uma das questões mais importantes no agrupamento!
Aqui está uma maneira de calcular a similaridade – Tomemos a distância entre os centróides destes agrupamentos. Os pontos com a menor distância são referidos como pontos semelhantes e podemos fundi-los. Podemos nos referir a isto também como um algoritmo baseado na distância (já que estamos calculando as distâncias entre os clusters).
Em clustering hierárquico, temos um conceito chamado matriz de proximidade. Esta armazena as distâncias entre cada ponto. Vamos dar um exemplo para entender esta matriz, bem como os passos para realizar o agrupamento hierárquico.
Configurando o Exemplo

Suponha que um professor queira dividir seus alunos em diferentes grupos. Ela tem as notas obtidas por cada aluno em uma tarefa e com base nessas notas, ela quer segmentar os alunos em grupos. Não há um alvo fixo aqui quanto ao número de grupos a ter. Como o professor não sabe que tipo de alunos devem ser designados a que grupo, não pode ser resolvido como um problema de aprendizagem supervisionada. Assim, vamos tentar aplicar o agrupamento hierárquico aqui e segmentar os alunos em diferentes grupos.
Vamos tirar uma amostra de 5 alunos:
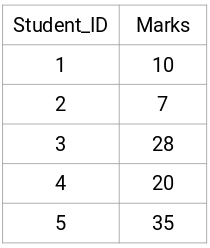
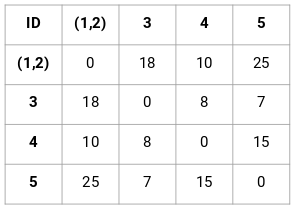
Criar uma Matriz de Proximidade
Primeiro, vamos criar uma matriz de proximidade que nos dirá a distância entre cada um destes pontos. Como estamos calculando a distância de cada ponto de cada um dos outros pontos, vamos obter uma matriz quadrada de forma n X n (onde n é o número de observações).
Vamos fazer a matriz de proximidade 5 x 5 para o nosso exemplo:
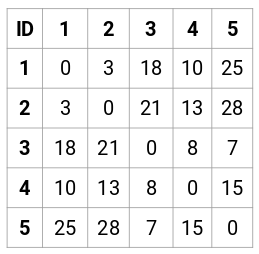
Os elementos diagonais desta matriz serão sempre 0 pois a distância de um ponto consigo mesmo é sempre 0. Vamos usar a fórmula de distância Euclidiana para calcular o resto das distâncias. Então, digamos que queremos calcular a distância entre o ponto 1 e 2:
√(10-7)^2 = √9 = 3
Simplesmente, podemos calcular todas as distâncias e preencher a matriz de proximidade.
Passos para Realizar Agrupamento Hierárquico
Passo 1: Primeiro, atribuímos todos os pontos a um agrupamento individual:
![]()
Diferentes cores aqui representam diferentes agrupamentos. Você pode ver que temos 5 clusters diferentes para os 5 pontos em nossos dados.
Passo 2: Em seguida, vamos olhar para a menor distância na matriz de proximidade e fundir os pontos com a menor distância. Atualizamos então a matriz de proximidade:
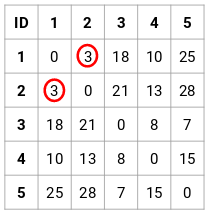
Aqui, a menor distância é 3 e assim fundiremos os pontos 1 e 2:
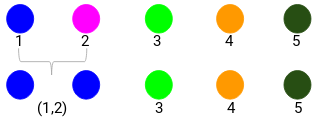
Vejamos os clusters atualizados e assim atualizemos a matriz de proximidade:
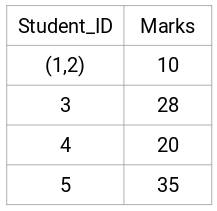
Aqui, tomamos o máximo das duas marcas (7, 10) para substituir as marcas para este cluster. Ao invés do máximo, também podemos tomar o valor mínimo ou os valores médios. Agora, vamos novamente calcular a matriz de proximidade para estes clusters:
Passo 3: Vamos repetir o passo 2 até restar apenas um único cluster.
Então, vamos primeiro olhar para a distância mínima na matriz de proximidade e depois fundir o par de clusters mais próximo. Vamos obter os clusters fundidos como mostrado abaixo após repetir estes passos:
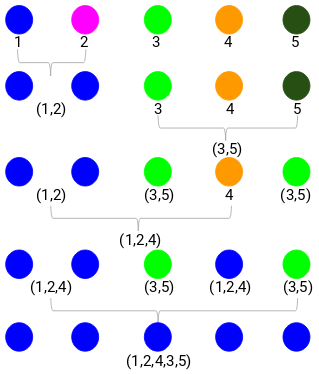
Começamos com 5 clusters e finalmente temos um único cluster. É assim que funciona o agrupamento hierárquico de aglomerados. Mas a questão candente ainda permanece – como decidimos o número de aglomerados? Vamos entender que na próxima seção.
Como devemos escolher o número de clusters no agrupamento hierárquico?
Pronto para finalmente responder a esta pergunta que tem andado por aí desde que começamos a aprender? Para obter o número de clusters para clustering hierárquico, fazemos uso de um conceito fantástico chamado Dendrogram.
Um dendrogram é um diagrama em forma de árvore que registra as seqüências de merges ou splits.
Vamos voltar ao nosso exemplo de professor-aluno. Sempre que fundimos dois clusters, um dendrogram irá registrar a distância entre esses clusters e representá-lo em forma de gráfico. Vamos ver como um dendrograma se parece:
Temos as amostras do conjunto de dados no eixo x e a distância no eixo y. Sempre que dois clusters forem fundidos, vamos juntá-los neste dendrograma e a altura da junção será a distância entre estes pontos. Vamos construir o dendrograma para o nosso exemplo:
Tire um momento para processar a imagem acima. Começamos fundindo as amostras 1 e 2 e a distância entre estas duas amostras foi de 3 (consulte a primeira matriz de proximidade na seção anterior). Vamos plotar isto no dendrogram:
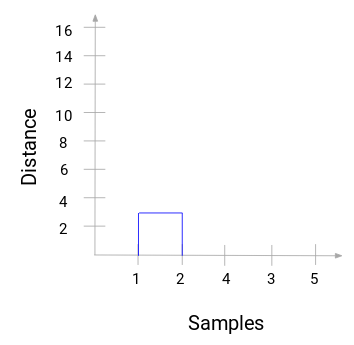
Aqui, podemos ver que fundimos as amostras 1 e 2. A linha vertical representa a distância entre estas amostras. Da mesma forma, plotamos todos os passos onde fundimos os clusters e, finalmente, obtemos um dendrograma como este:
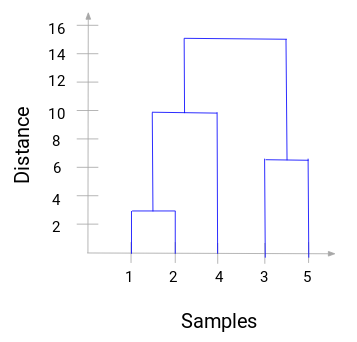
Podemos visualizar claramente os passos de clustering hierárquico. Mais a distância das linhas verticais no dendrograma, mais a distância entre esses aglomerados.
Agora, podemos definir uma distância de limiar e traçar uma linha horizontal (Geralmente, tentamos definir o limiar de tal forma que ele corta a linha vertical mais alta). Vamos definir este limiar como 12 e traçar uma linha horizontal:
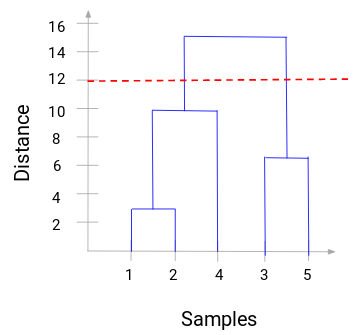
O número de clusters será o número de linhas verticais que estão sendo intersectadas pela linha desenhada usando o limiar. No exemplo acima, como a linha vermelha intersecta 2 linhas verticais, teremos 2 clusters. Um aglomerado terá uma amostra (1,2,4) e o outro terá uma amostra (3,5). Bastante simples, certo?
É assim que podemos decidir o número de clusters usando um dendrograma em Clusterização Hierárquica. Na próxima seção, vamos implementar o clustering hierárquico que irá ajudá-lo a entender todos os conceitos que aprendemos neste artigo.
Solucionar o problema de segmentação de clientes atacadistas usando o Clustering Hierárquico
Tempo para sujar as mãos em Python!
Estaremos trabalhando em um problema de segmentação de clientes atacadistas. Você pode baixar o conjunto de dados usando este link. Os dados estão hospedados no repositório UCI Machine Learning. O objetivo deste problema é segmentar os clientes de um distribuidor atacadista com base em seus gastos anuais em diversas categorias de produtos, como leite, mercearia, região, etc.
Vamos explorar os dados primeiro e depois aplicar o Clustering Hierárquico para segmentar os clientes.
Primeiro importamos as bibliotecas necessárias:
Carregar os dados e olhar para as primeiras linhas:
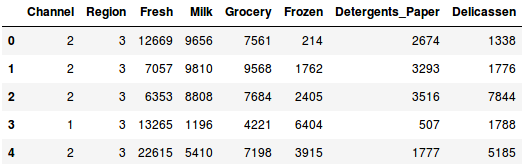
Existem múltiplas categorias de produtos – Frescos, Leite, Mercearia, etc. Os valores representam o número de unidades adquiridas por cada cliente para cada produto. O nosso objectivo é fazer clusters a partir destes dados que possam segmentar clientes semelhantes em conjunto. Claro que utilizaremos o Clustering Hierárquico para este problema.
Mas antes de aplicar o Clustering Hierárquico, temos que normalizar os dados para que a escala de cada variável seja a mesma. Porque é que isto é importante? Bem, se a escala das variáveis não for a mesma, o modelo pode ficar enviesado para as variáveis de maior magnitude como Fresco ou Leite (consulte a tabela acima).
Então, vamos primeiro normalizar os dados e trazer todas as variáveis para a mesma escala:
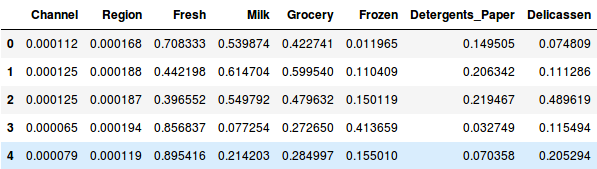
Aqui, podemos ver que a escala de todas as variáveis é quase similar. Agora, estamos prontos para ir. Vamos primeiro desenhar o dendrograma para nos ajudar a decidir o número de clusters para este problema particular:
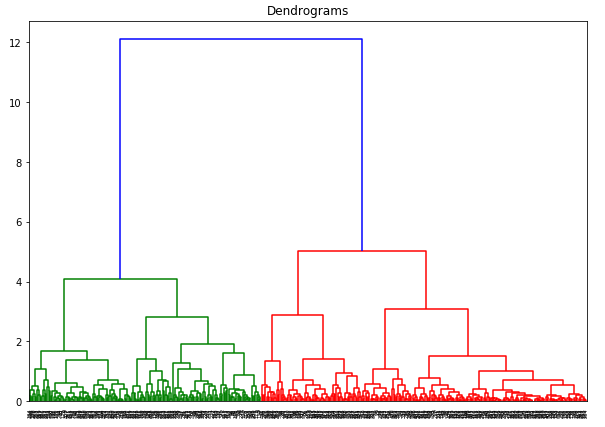
O eixo x contém as amostras e o eixo y representa a distância entre estas amostras. A linha vertical com distância máxima é a linha azul e por isso podemos decidir um limite de 6 e cortar o dendrograma:
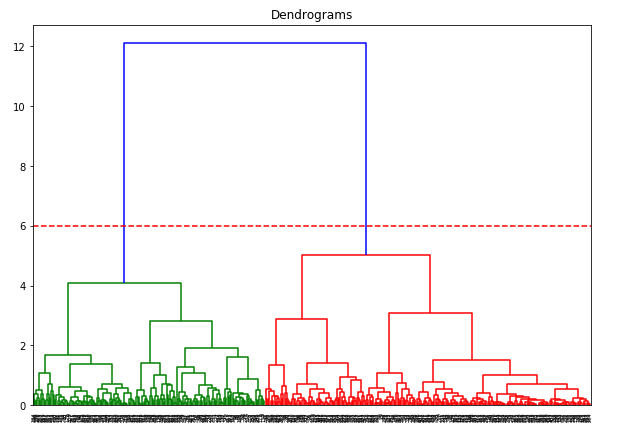
Temos dois clusters já que esta linha corta o dendrograma em dois pontos. Vamos agora aplicar o agrupamento hierárquico para 2 clusters:
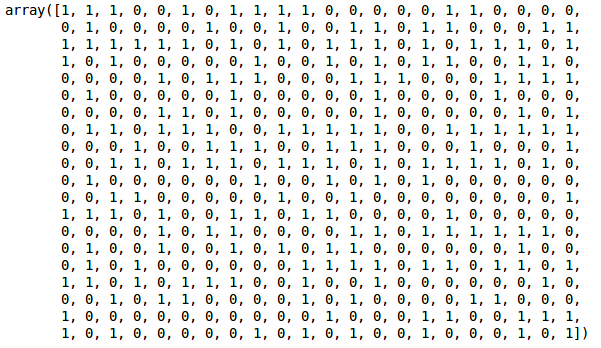
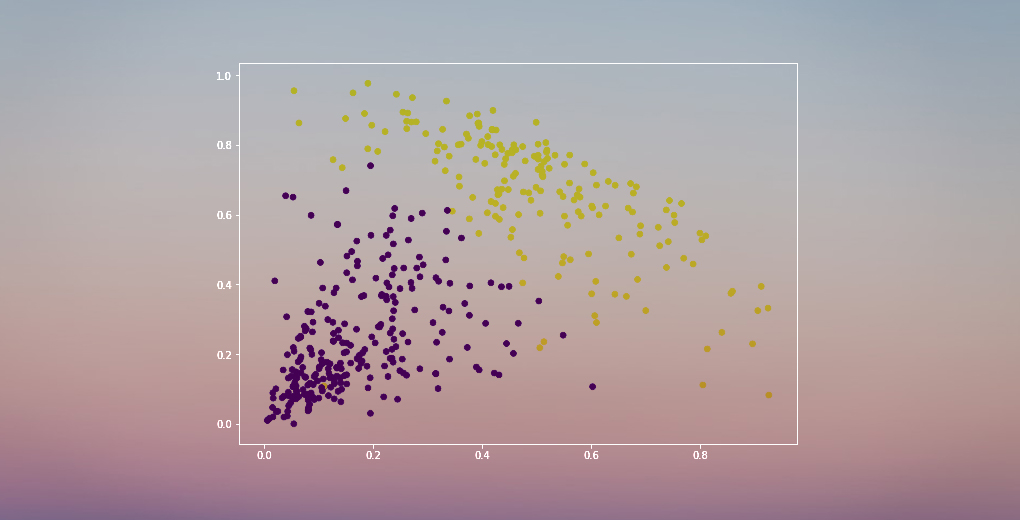
Podemos ver os valores de 0s e 1s na saída, uma vez que definimos 2 clusters. 0 representa os pontos que pertencem ao primeiro cluster e 1 representa os pontos do segundo cluster. Vamos agora visualizar os dois clusters:
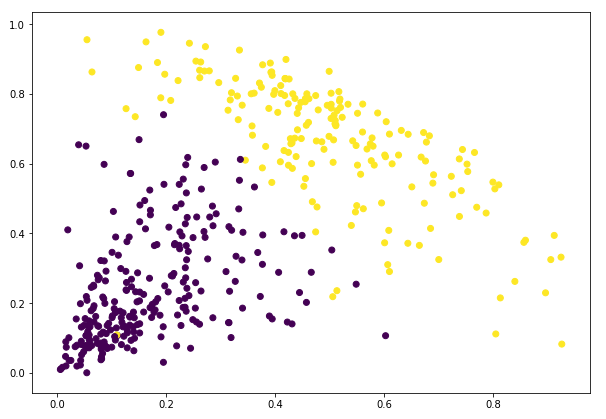
Awesome! Podemos visualizar claramente os dois aglomerados aqui. É assim que podemos implementar o agrupamento hierárquico em Python.
End Notes
Austering hierárquico é uma forma super útil de segmentar observações. A vantagem de não ter que pré-definir o número de clusters dá-lhe uma vantagem sobre k-Means.
Se você ainda é relativamente novo na ciência dos dados, eu recomendo altamente fazer o curso Applied Machine Learning. É um dos cursos de aprendizagem de máquinas mais abrangentes de ponta a ponta que você encontrará em qualquer lugar. O clustering hierárquico é apenas um dos diversos tópicos que abordamos no curso.