Guias Quantrium

Tesseract é um motor de reconhecimento óptico de caracteres que pode ser usado em vários sistemas operacionais. É um software livre, lançado sob a licença Apache. Originalmente, o Tesseract foi desenvolvido pela Hewlett-Packard como software proprietário nos anos 80, mais tarde, foi lançado como um software de código aberto em 2005. Depois, a partir de 2006, o seu desenvolvimento está a ser patrocinado pelo Google. Neste guia, vou levá-lo através dos passos que segui para instalar o Tesseract na minha máquina Windows 10. Também lhe mostrarei como você pode usar o Tesseract fora da linha de comando depois de tê-lo instalado com sucesso.
Para instalar o Tesseract 4 em nosso sistema Windows, vá para o seguinte link:
Download do arquivo executável do Windows clicando no hiperlink intitulado tesseract-ocr-w64-setup-v4.1.0.20190314.exe. Uma notificação pedindo-lhe para guardar um ficheiro exe chamado “Tesseract-ocr-w64-setup-v4.1.0.20190314.exe” irá aparecer. Salve este arquivo .exe onde você tiver espaço de armazenamento suficiente.
Abra este arquivo exe. Se o Windows lhe perguntar “Você quer permitir que este software faça alterações no seu sistema”, clique sim. Você será levado para a seção de instalação.
A seguir, clique I agree to the terms and conditions e depois de selecionar para quem e tudo que você quer instalar o Tesseract (qualquer um que use este computador/apenas para mim. Você pode selecionar qualquer um dos dois), clique em next.
Clique nas caixas que dizem “ScrollView”, “Training Tools”, “Shortcuts creation” e, o que é importante, “Language data”. Estas devem ser marcadas por padrão, mas apenas as faça caso não tenham sido marcadas em seu sistema.
Agora, se você quiser fazer previsões em línguas estrangeiras como japonês, chinês, curdo ou indiano como o hindi, tâmil, bengali etc., marque também os “dados adicionais do script” e “dados adicionais do idioma”. Se quiser fazer previsões apenas para a língua inglesa, não precisa de assinalar esta opção.
Click on Next. Selecione o diretório onde você quer instalar o Tesseract. Por padrão, ele mostra C:\Program Files\Tesseract-OCR para mim e é onde eu o instalei. Você pode instalá-lo conforme a sua escolha. Mas tome nota do caminho onde você instalou o Tesseract na sua máquina. Isto é importante.
Agora você pode selecionar a pasta do menu iniciar na qual você gostaria de criar o atalho do programa. Eu criei-o numa pasta chamada “Tesseract-OCR”. Se você o quiser em uma nova pasta, basta digitar o nome da pasta no espaço em branco logo abaixo do texto “Select the Start Menu folder in which you would like ….”.
Você também pode marcar a caixa “Do not create shortcuts” no canto inferior esquerdo se você não quiser criar nenhum atalho. Uma vez terminada a selecção da sua opção preferida, clique em instalar. Deve levar alguns minutos para que a instalação aconteça.
Após a instalação terminar, vá para o diretório onde você instalou seu Tesseract. Queremos usar o Tesseract a partir da nossa linha de comando do windows e para isso, temos de adicionar o Tesseract ao nosso caminho na variável de ambiente do sistema.
Para isso, clique no botão iniciar no windows e procure “variável de ambiente”. Você verá um resultado chamado “Editar as variáveis de ambiente do sistema”. Clique sobre isso. Depois de clicar nisso, você deve estar na seção “Avançado” de “Propriedades do sistema” e um botão chamado “Variáveis de ambiente ….” deve estar visível no canto inferior direito. Clique nesse botão.
Agora, você verá duas tabelas aqui. Uma chamada User variables for <username>. Aqui, a <username> é uma variável que representa o nome de usuário usando o PC atualmente. A outra tabela chamada “System variables” (Variáveis do sistema). Na tabela “Variáveis do sistema” clique na variável chamada “Path” e depois clique neste botão chamado “Edit” logo acima do botão “OK” como mostrado na imagem abaixo.
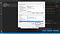
A partir do momento em que você terminar, você verá uma página chamada “Editar variável de ambiente”. Aqui no canto superior direito, você verá um botão chamado “New” (Novo). Clique no botão “Novo”. Você terá um espaço em branco onde você pode adicionar algum texto. Aqui, adicione o nome do seu diretório onde todos os seus arquivos Tesseract-OCR são armazenados.
Após ter digitado o nome do diretório, pressione “Enter” e verifique se o nome do seu diretório foi adicionado à “Edit environment variable table”. Uma vez que tenha sido, clique em “OK”. Clique novamente em OK na página “Variáveis de Ambiente”. Clique novamente em “OK” na página “Propriedades do Sistema”. Você deve ter saído de todas as opções de configuração agora.
Abrir prompt de comando e digite tesseract --version no prompt de comando e pressione enter. Você verá algo como isto:
Se você vir algum erro como tesseract command not found, muito provavelmente você cometeu algum erro ao seguir este guia. Volte atrás e veja onde errou e tente corrigi-lo. Alternativamente, você pode repetir todo o processo novamente.
Great! Agora você tem o Tesseract instalado na sua máquina. Você pode começar a brincar com ele e explorá-lo melhor.
Como usar o Tesseract 4 usando linha de comando em uma máquina Windows
Primeiro, certifique-se de ter algum documento escrito à mão ou algum documento digitado na forma de uma imagem. Digamos que você tenha alguma foto em formato png chamada handwritten_photo_1 em seu Desktop e queira testar o Tesseract com ele. Abra o seu prompt de comando. Você começará neste diretório:
C:\Users\username>
onde username é o seu nome de usuário naquele sistema. Eu preciso de ir para o directório do desktop. Então eu uso o seguinte comando:
C:\Users\username> cd Desktop
Agora eu estou no diretório Desktop, onde minha imagem está localizada. Você pode ver o que o Tesseract prevê o texto no documento usando o seguinte comando:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseract irá emitir diretamente o texto na própria linha de comando. O parâmetro -l é usado para especificar o idioma. Aqui nós o especificamos como inglês, que é o caso por padrão de qualquer forma, então usar -l eng foi redundante neste caso. Se você quiser usar algum outro idioma para OCR, verifique este link aqui que tem todos os arquivos .traineddata, que especificam o idioma:
Dizer que você tem um documento de texto escrito em Hindi. Então, vá para este link acima, clique no arquivo intitulado hin.traineddata e faça o download. Uma vez que você o tenha baixado, você precisa ir para a pasta “tessdata”, que estará dentro do seu diretório onde você tinha instalado originalmente o tesseract. Uma vez feito isso, você pode executar o OCR de documentos Hindi usando o seguinte comando:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
Em vez de exibir a saída de OCR na própria linha de comando, digamos que você queira que sua saída de OCR seja armazenada em um arquivo texto. Nesse caso você pode digitar o seguinte comando:
tesseract handwritten_photo_1.png output.txt
O texto em handwritten_photo_1.png será armazenado em um arquivo de texto chamado output.txt que será localizado no seu diretório de trabalho atual, que era Desktop no meu caso.
Tesseract também pode pegar um arquivo de texto como entrada, onde o texto precisa conter todo o caminho absoluto das imagens que você quer processar.
Isso é especialmente útil quando, digamos que você tenha duas imagens escritas à mão em inglês chamadas handwritten_photo_1.png e handwritten_photo_2.png no diretório C:\Program Files. Agora, no seu directório de trabalho actual, tem um ficheiro de texto chamado input.txt cujo conteúdo é:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
Na primeira e segunda linha respectivamente.
Agora se quiser guardar o conteúdo destas duas fotos manuscritas num ficheiro de texto, pode apenas fazer o seguinte:
tesseract input.txt output.txt -l eng
output.txt terá o conteúdo OCR de ambos handwritten_photo_1.png e handwritten_photo_2.png, nessa ordem. Aqui, você deve observar que input.txt estava no diretório de trabalho atual. Você pode usar o tesseract num ficheiro de texto que não está no seu directório de trabalho actual, incluindo a localização do directório como aqui:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt será novamente localizado no directório de trabalho actual. Você pode fazer isso para mais de duas fotos também. Note que a previsão para uma nova foto no arquivo output.txt será precedida por algum símbolo como:
Então, neste caso, Viral Calic é a previsão para a primeira imagem, CY am the king of the world a previsão para a segunda imagem, Com and Serr a previsão para a terceira imagem e assim por diante. Você pode verificar a saída para todas as suas imagens de entrada e verificar a precisão das previsões.
é isso! Parabéns, agora você está pronto para usar o Tesseract no seu sistema Windows 10.