Introducere
Arborele de decizie este un tip de algoritm de învățare supravegheată care poate fi utilizat atât în probleme de regresie, cât și de clasificare. Funcționează atât pentru variabilele de intrare și de ieșire categorice, cât și pentru cele continue.
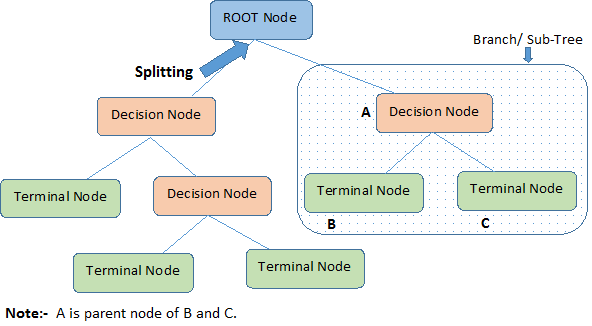
Să identificăm terminologiile importante privind Decision Tree, analizând imaginea de mai sus:
-
Nodul rădăcină reprezintă întreaga populație sau eșantion. Acesta se împarte ulterior în două sau mai multe seturi omogene.
-
Splitting este un proces de divizare a unui nod în două sau mai multe subnoduri.
-
Când un subnod se împarte în alte subnoduri, acesta se numește nod de decizie.
-
Nodurile care nu se divizează se numesc nod terminal sau frunză.
-
Când se elimină subnodurile unui nod de decizie, acest proces se numește Pruning. Opusul tăierii este divizarea.
-
O sub-secțiune a unui întreg arbore se numește ramură.
-
Un nod care este împărțit în subnoduri se numește nod părinte al subnodurilor; în timp ce subnodurile se numesc copii ai nodului părinte.
Tipuri de arbori de decizie
Arbori de regresie
Să aruncăm o privire la imaginea de mai jos, care ajută la vizualizarea naturii partiționării efectuate de un arbore de regresie. Aceasta prezintă un arbore nepodobit și un arbore de regresie ajustat la un set de date aleatorii. Ambele vizualizări arată o serie de reguli de divizare, pornind de la vârful arborelui. Observați că fiecare divizare a domeniului este aliniată cu una dintre axele caracteristicilor. Conceptul de divizare paralelă cu axele se generalizează în mod direct la dimensiuni mai mari de două. Pentru un spațiu al caracteristicilor de dimensiune $p$, un subansamblu al lui $\mathbb{R}^p$, spațiul este împărțit în $M$ regiuni, $R_{m}$, fiecare dintre acestea fiind un „hiperbloc” cu dimensiunea $p$.
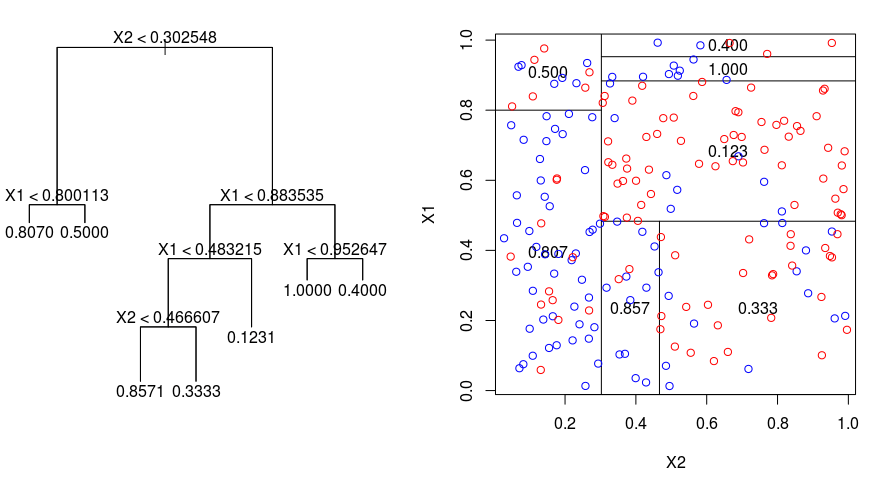
Pentru a construi un arbore de regresie, mai întâi se utilizează splitarea binară recursivă pentru a crește un arbore mare pe datele de instruire, oprindu-se doar atunci când fiecare nod terminal are mai puțin decât un anumit număr minim de observații. Divizarea binară recursivă este un algoritm lacom și descendent utilizat pentru a minimiza suma pătratelor reziduale (RSS), o măsură de eroare utilizată și în setările de regresie liniară. RSS, în cazul unui spațiu caracteristic partiționat cu M partiții, este dat de:
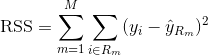
Începând din vârful arborelui, îl împărțiți în 2 ramuri, creând o partiție de 2 spații. Apoi, efectuați de mai multe ori această diviziune particulară în vârful arborelui și alegeți diviziunea trăsăturilor care minimizează RSS (curent).
În continuare, aplicați tăierea complexității costurilor la arborele mare pentru a obține o secvență a celor mai bune subarborete, în funcție de $\alpha$. Ideea de bază aici este de a introduce un parametru de reglare suplimentar, notat cu $\alpha$, care echilibrează adâncimea arborelui și buna potrivire a acestuia cu datele de instruire.
Puteți utiliza validarea încrucișată K-fold pentru a alege $\alpha$. Această tehnică presupune pur și simplu împărțirea observațiilor de instruire în K pliuri pentru a estima rata de eroare de testare a subarborelor. Scopul dvs. este de a-l selecta pe cel care conduce la cea mai mică rată de eroare.
Arbori de clasificare
Un arbore de clasificare este foarte asemănător cu un arbore de regresie, cu excepția faptului că este utilizat pentru a prezice un răspuns calitativ mai degrabă decât unul cantitativ.
Reamintim că pentru un arbore de regresie, răspunsul prezis pentru o observație este dat de răspunsul mediu al observațiilor de instruire care aparțin aceluiași nod terminal. În schimb, pentru un arbore de clasificare, preziceți că fiecare observație aparține clasei celei mai frecvente de observații de instruire din regiunea căreia îi aparține.
În interpretarea rezultatelor unui arbore de clasificare, deseori sunteți interesat nu numai de prezicerea clasei corespunzătoare unei anumite regiuni a nodului terminal, ci și de proporțiile clasei în rândul observațiilor de instruire care se încadrează în acea regiune.
Sarcina de a dezvolta un arbore de clasificare este destul de asemănătoare cu sarcina de a dezvolta un arbore de regresie. La fel ca în cadrul regresiei, utilizați divizarea binară recursivă pentru a dezvolta un arbore de clasificare. Cu toate acestea, în cadrul clasificării, suma reziduală a pătratelor nu poate fi utilizată ca un criteriu pentru realizarea diviziunilor binare. În schimb, puteți utiliza oricare dintre aceste 3 metode de mai jos:
- Classification Error Rate: Mai degrabă decât să vedeți cât de departe este un răspuns numeric de valoarea medie, ca în cazul setării de regresie, puteți defini în schimb „rata de succes” ca fiind fracțiunea de observații de instruire dintr-o anumită regiune care nu aparțin clasei cu cea mai mare frecvență. Eroarea este dată de această ecuație:
E = 1 – argmaxc($\hat{\pi}_{mc}$)
în care $\hat{\pi}_{mc}$ reprezintă fracțiunea de date de instruire din regiunea Rm care aparțin clasei c.
- Indicele Gini: Indicele Gini este o măsură alternativă de eroare care este concepută pentru a arăta cât de „pură” este o regiune. „Puritate”, în acest caz, înseamnă cât de mult din datele de instruire dintr-o anumită regiune aparțin unei singure clase. Dacă o regiune Rm conține date care aparțin în cea mai mare parte unei singure clase c, atunci valoarea indicelui Gini va fi mică:
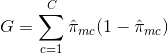
- Entropie încrucișată: O a treia alternativă, care este similară indicelui Gini, este cunoscută sub numele de entropie încrucișată sau devianță:
Entropia încrucișată va lua o valoare apropiată de zero dacă valorile $\hat{\pi}_{mc}$ sunt toate apropiate de 0 sau de 1. Prin urmare, la fel ca indicele Gini, entropia încrucișată va avea o valoare mică dacă al m-lea nod este pur. De fapt, se pare că indicele Gini și entropia încrucișată sunt destul de asemănătoare din punct de vedere numeric.
Când se construiește un arbore de clasificare, fie indicele Gini, fie entropia încrucișată sunt utilizate de obicei pentru a evalua calitatea unei anumite diviziuni, deoarece acestea sunt mai sensibile la puritatea nodurilor decât rata de eroare de clasificare. Oricare dintre aceste 3 abordări ar putea fi utilizate la tăierea arborelui, dar rata de eroare de clasificare este preferabilă dacă scopul este precizia predicției arborelui final tăiat.
Vantaje și dezavantaje ale arborilor de decizie
Avantajul major al utilizării arborilor de decizie este că aceștia sunt intuitiv foarte ușor de explicat. Ei oglindesc îndeaproape procesul decizional uman în comparație cu alte abordări de regresie și clasificare. Ei pot fi afișați grafic și pot gestiona cu ușurință predictorii calitativi fără a fi nevoie să creeze variabile fictive.
Cu toate acestea, arborii de decizie nu au, în general, același nivel de acuratețe predictivă ca și alte abordări, deoarece nu sunt destul de rezistenți. O mică schimbare în date poate provoca o schimbare mare în arborele final estimat.
Prin agregarea mai multor arbori de decizie, folosind metode precum bagging, păduri aleatoare și boosting, performanța predictivă a arborilor de decizie poate fi îmbunătățită substanțial.
Metode bazate pe arbori de decizie
Bagging
Arborii de decizie discutați mai sus suferă de o varianță mare, ceea ce înseamnă că dacă împărțiți datele de instruire în 2 părți la întâmplare și potriviți un arbore de decizie la ambele jumătăți, rezultatele pe care le obțineți ar putea fi foarte diferite. În schimb, o procedură cu o varianță scăzută va produce rezultate similare dacă este aplicată în mod repetat la seturi de date distincte.
Bagging, sau agregarea bootstrap, este o tehnică utilizată pentru a reduce varianța predicțiilor dvs. prin combinarea rezultatului mai multor clasificatoare modelate pe diferite subeșantioane din același set de date. Iată ecuația pentru bagging:
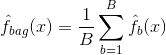
în care se generează $B$ seturi de date de instruire bootstrap diferite. Apoi vă antrenați metoda pe al $b-lea$ set de instruire bootstrap pentru a obține $\hat{f}_{b}(x)$ și, în final, faceți media predicțiilor.
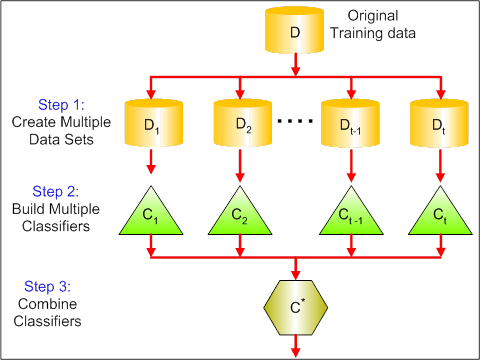
Vizualul de mai jos arată cei 3 pași diferiți în bagging:
-
Pasul 1: Aici înlocuiți datele originale cu date noi. Noile date au, de obicei, o fracțiune din coloanele și rândurile datelor originale, care pot fi apoi folosite ca hiper-parametri în modelul de bagging.
-
Etapa 2: Se construiesc clasificatori pe fiecare set de date. În general, puteți utiliza același clasificator pentru realizarea modelelor și predicțiilor.
-
Etapa 3: În cele din urmă, utilizați o valoare medie pentru a combina predicțiile tuturor clasificatorilor, în funcție de problemă. În general, aceste valori combinate sunt mai robuste decât un singur model.
În timp ce bagging-ul poate îmbunătăți predicțiile pentru multe metode de regresie și clasificare, acesta este deosebit de util pentru arborii de decizie. Pentru a aplica bagging la arborii de regresie/clasificare, pur și simplu construiți $B$ arbori de regresie/clasificare folosind $B$ seturi de instruire bootstrapate și faceți o medie a predicțiilor rezultate. Acești arbori sunt dezvoltați în profunzime și nu sunt tăiați. Prin urmare, fiecare arbore individual are o varianță ridicată, dar o prejudecată redusă. Calcularea mediei acestor $B$ arbori reduce varianța.
În general, s-a demonstrat că bagging-ul oferă îmbunătățiri impresionante ale acurateței prin combinarea a sute sau chiar mii de arbori într-o singură procedură.
Random Forests
Random Forests este o metodă versatilă de învățare automată capabilă să realizeze atât sarcini de regresie, cât și de clasificare. De asemenea, întreprinde metode de reducere dimensională, tratează valorile lipsă, valorile aberante și alți pași esențiali de explorare a datelor și face o treabă destul de bună.
Random Forests oferă o îmbunătățire față de arborii în saci printr-o mică modificare care decorelă arborii. Ca și în bagging, construiți un număr de arbori de decizie pe eșantioane de instruire bootstrapate. Dar atunci când se construiesc acești arbori de decizie, de fiecare dată când se ia în considerare o divizare într-un arbore, se alege un eșantion aleatoriu de m predictori ca și candidați de divizare din întregul set de $p$ predictori. Se permite ca divizarea să utilizeze doar unul dintre cei $m$ predictori. Aceasta este principala diferență dintre pădurile aleatoare și bagging; deoarece, ca și în bagging, alegerea predictorului $m = p$.
Pentru a dezvolta o pădure aleatoare, trebuie să:
-
În primul rând, să presupunem că numărul de cazuri din setul de instruire este K. Apoi, luați un eșantion aleatoriu din aceste K cazuri, iar apoi utilizați acest eșantion ca set de instruire pentru creșterea arborelui.
-
Dacă există $p$ variabile de intrare, specificați un număr $m < p$ astfel încât la fiecare nod să puteți selecta $m$ variabile aleatoare din cele $p$. Cea mai bună divizare a acestor $m$ este utilizată pentru a diviza nodul.
-
Care arbore este ulterior crescut în cea mai mare măsură posibilă și nu este necesară nicio tăiere.
-
În cele din urmă, se agregă predicțiile arborilor țintă pentru a prezice noi date.
Random Forests este foarte eficient la estimarea datelor lipsă și la menținerea acurateței atunci când o proporție mare de date este lipsă. De asemenea, poate echilibra erorile în seturile de date în care clasele sunt dezechilibrate. Cel mai important, poate gestiona seturi de date masive cu dimensionalitate mare. Cu toate acestea, un dezavantaj al utilizării Random Forests este acela că s-ar putea supraadapta cu ușurință seturile de date zgomotoase, în special în cazul în care se face regresie.
Boosting
Boosting este o altă abordare pentru a îmbunătăți predicțiile rezultate dintr-un arbore de decizie. Ca și bagging-ul și pădurile aleatoare, este o abordare generală care poate fi aplicată la multe metode de învățare statistică pentru regresie sau clasificare. Reamintim că bagging-ul implică crearea mai multor copii ale setului original de date de instruire folosind bootstrap, adaptarea unui arbore de decizie separat la fiecare copie și apoi combinarea tuturor arborilor pentru a crea un singur model predictiv. În mod notabil, fiecare arbore este construit pe un set de date bootstrap, independent de ceilalți arbori.
Boosting funcționează într-un mod similar, cu excepția faptului că arborii sunt dezvoltați secvențial: fiecare arbore este dezvoltat folosind informații de la arborii dezvoltați anterior. Boosting nu implică eșantionarea bootstrap; în schimb, fiecare arbore este ajustat pe o versiune modificată a setului de date original.
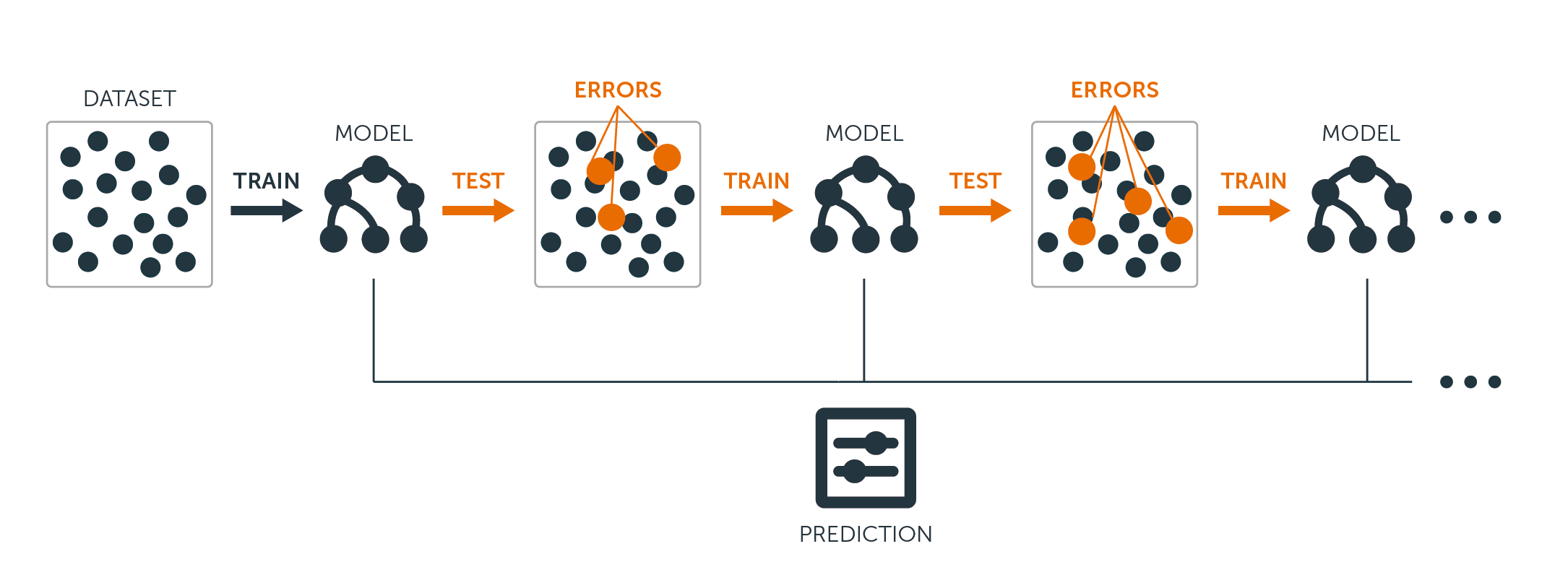
Atât pentru arbori de regresie, cât și pentru arbori de clasificare, stimularea funcționează astfel:
-
În loc să se adapteze un singur arbore de decizie mare la date, ceea ce echivalează cu o adaptare dură a datelor și cu o potențială supraadaptare, abordarea de stimulare în schimb învață lent.
-
După modelul curent, se adaptează un arbore de decizie la reziduurile modelului. Adică, se potrivește un arbore folosind reziduurile curente, mai degrabă decât rezultatul $Y$, ca răspuns.
-
Se adaugă apoi acest nou arbore de decizie în funcția ajustată pentru a actualiza reziduurile. Fiecare dintre acești arbori poate fi destul de mic, cu doar câteva noduri terminale, determinate de parametrul $d$ din algoritm. Prin adaptarea unor arbori mici la reziduuri, îmbunătățiți încet $\hat{f}$ în zonele în care nu se comportă bine.
-
Parametrul de micșorare $\nu$ încetinește și mai mult procesul, permițând unor arbori mai mulți și cu forme diferite să atace reziduurile.
Boosting-ul este foarte util atunci când aveți multe date și vă așteptați ca arborii de decizie să fie foarte complecși. Boosting-ul a fost folosit pentru a rezolva multe probleme dificile de clasificare și regresie, inclusiv analiza de risc, analiza sentimentelor, publicitatea predictivă, modelarea prețurilor, estimarea vânzărilor și diagnosticarea pacienților, printre altele.
Arbori de decizie în R
Arbori de clasificare
Pentru această parte, lucrați cu setul de date Carseats folosind pachetul tree din R. Rețineți că trebuie să instalați mai întâi pachetele ISLR și tree în mediul R Studio. Să încărcăm mai întâi dataframe-ul Carseats din pachetul ISLR.
library(ISLR)data(package="ISLR")carseats<-CarseatsSă încărcăm și pachetul tree.
require(tree)Setul de date Carseats este un dataframe cu 400 de observații pe următoarele 11 variabile:
-
Sales: vânzări unitare în mii de unități
-
CompPrice: prețul practicat de concurent în fiecare locație
-
Rezultat: nivelul de venit al comunității în mii de dolari
-
Publicitate: bugetul publicitar local la fiecare locație în mii de dolari
-
Populație: populația regională în mii de locuitori
-
Preț: prețul pentru scaunele auto la fiecare locație
-
ShelveLoc: Bad, Good sau Medium indică calitatea locației de rafturi
-
Age: nivelul de vârstă al populației
-
Educație: nivelul de educație la locație
-
Urban: nivelul de educație la locație
-
Urban: Da/Nu
-
SUA: Da/Nu
names(carseats)Să ne uităm la histograma vânzărilor de mașini:
hist(carseats$Sales)Observați că Sales este o variabilă cantitativă. Vreți să o demonstrați folosind arbori cu un răspuns binar. Pentru a face acest lucru, transformați Sales într-o variabilă binară, care se va numi High. Dacă vânzările sunt mai mici de 8, nu va fi mare. În caz contrar, va fi mare. Apoi puteți pune acea nouă variabilă High înapoi în dataframe.
High = ifelse(carseats$Sales<=8, "No", "Yes")carseats = data.frame(carseats, High)Acum să completăm un model folosind arbori de decizie. Desigur, nu puteți avea variabila Sales aici, deoarece variabila dvs. de răspuns High a fost creată din Sales. Astfel, să o excludem și să potrivim arborele.
tree.carseats = tree(High~.-Sales, data=carseats)Să vedem rezumatul arborelui dvs. de clasificare:
summary(tree.carseats)Puteți vedea variabilele implicate, numărul de noduri terminale, deviația medie reziduală, precum și rata de eroare de clasificare greșită. Pentru a o face mai vizuală, haideți să trasăm și arborele, apoi să îl adnotam folosind funcția la îndemână text:
plot(tree.carseats)text(tree.carseats, pretty = 0)Există atât de multe variabile, ceea ce face foarte complicat să privim arborele. Cel puțin, puteți vedea că la fiecare dintre nodurile terminale, acestea sunt etichetate Yes sau No. La fiecare nod de divizare, sunt afișate variabilele și valoarea alegerii de divizare (de exemplu, Price < 92.5 sau Advertising < 13.5).
Pentru un rezumat detaliat al arborelui, pur și simplu îl imprimați. Va fi la îndemână dacă doriți să extrageți detalii din arbore în alte scopuri:
tree.carseatsEste timpul să tăiați arborele. Să creăm un set de instruire și unul de testare prin împărțirea cadrului de date carseats în 250 de probe de instruire și 150 de probe de testare. În primul rând, se stabilește o sămânță pentru ca rezultatele să fie reproductibile. Apoi, luați un eșantion aleatoriu din numerele de identificare (index) ale eșantioanelor. În mod specific aici, eșantionați din setul de la 1 la n numărul de rânduri de rânduri de scaune de mașină, care este 400. Doriți un eșantion de dimensiune 250 (în mod implicit, eșantionul folosește fără înlocuire).
set.seed(101)train=sample(1:nrow(carseats), 250) Deci acum obțineți acest indice train, care indexează 250 din cele 400 de observații. Puteți reface modelul cu tree, folosind aceeași formulă, cu excepția faptului că îi spuneți arborelui să utilizeze un subset egal cu train. Apoi, haideți să facem un grafic:
tree.carseats = tree(High~.-Sales, carseats, subset=train)plot(tree.carseats)text(tree.carseats, pretty=0)Graficul arată un pic diferit din cauza setului de date ușor diferit. Cu toate acestea, complexitatea arborelui arată aproximativ la fel.
Acum veți lua acest arbore și îl veți prezice pe setul de testare, folosind metoda predict pentru arbori. Aici veți dori să preziceți efectiv etichetele class.
tree.pred = predict(tree.carseats, carseats, type="class")Apoi puteți evalua eroarea folosind un tabel de clasificare greșită.
with(carseats, table(tree.pred, High))Pe diagonale se află clasificările corecte, în timp ce în afara diagonalelor se află cele incorecte. Vreți să le recorectați doar pe cele corecte. Pentru a face acest lucru, puteți lua suma celor 2 diagonale împărțită la total (150 de observații de test).
(72 + 43) / 150Ok, obțineți o eroare de 0,76 cu acest arbore.
Când creșteți un arbore mare și stufos, acesta ar putea avea o varianță prea mare. Astfel, să folosim validarea încrucișată pentru a tăia arborele în mod optim. Folosind cv.tree, veți folosi eroarea de clasificare greșită ca bază pentru a face tăierea.
cv.carseats = cv.tree(tree.carseats, FUN = prune.misclass)cv.carseatsImprimarea rezultatelor arată detaliile traseului validării încrucișate. Puteți vedea dimensiunile arborilor pe măsură ce au fost tăiați înapoi, abaterile pe măsură ce s-a procedat la tăiere, precum și parametrul de complexitate a costurilor utilizat în proces.
Să reprezentăm grafic acest lucru:
plot(cv.carseats)Urmărind graficul, vedeți o parte în spirală descendentă din cauza erorii de clasificare greșită pe 250 de puncte validate încrucișat. Deci, haideți să alegem o valoare în trepte descendente (12). Apoi, haideți să prunem arborele la o dimensiune de 12 pentru a identifica acel arbore. În cele din urmă, haideți să reprezentăm grafic și să adnotam acel arbore pentru a vedea rezultatul.
prune.carseats = prune.misclass(tree.carseats, best = 12)plot(prune.carseats)text(prune.carseats, pretty=0)Este puțin mai puțin adânc decât arborii anteriori și, de fapt, puteți citi etichetele. Să-l evaluăm din nou pe setul de date de test.
tree.pred = predict(prune.carseats, carseats, type="class")with(carseats, table(tree.pred, High))(74 + 39) / 150Se pare că clasificările corecte au scăzut puțin. S-a descurcat cam la fel ca arborele dvs. original, deci tăierea nu a afectat prea mult în ceea ce privește erorile de clasificare greșită și a dat un arbore mai simplu.
De multe ori, arborii nu dau erori de predicție foarte bune, așa că haideți să aruncăm o privire la pădurile aleatoare și la boosting, care tind să depășească arborii în ceea ce privește predicția și clasificarea greșită.
Păduri aleatoare
Pentru această parte, veți folosi Boston housing data pentru a explora pădurile aleatoare și boosting. Setul de date se află în pachetul MASS. Acesta oferă valorile locuințelor și alte statistici în fiecare dintre cele 506 suburbii din Boston, pe baza unui recensământ din 1970.
library(MASS)data(package="MASS")boston<-Bostondim(boston)names(boston)Să încărcăm, de asemenea, pachetul randomForest.
require(randomForest)Pentru a pregăti datele pentru pădurea aleatorie, să setăm sămânța și să creăm un set de antrenament de probă de 300 de observații.
set.seed(101)train = sample(1:nrow(boston), 300)În acest set de date, există 506 suburbii din Boston. Pentru fiecare suburbie, aveți variabile precum criminalitatea pe cap de locuitor, tipurile de industrie, numărul mediu de camere pe locuință, proporția medie de vârstă a caselor etc. Să folosim medv – valoarea mediană a locuințelor ocupate de proprietari pentru fiecare dintre aceste suburbii, ca variabilă de răspuns.
Să potrivim o pădure aleatorie și să vedem cât de bine se comportă. Așa cum am spus, se utilizează răspunsul medv, valoarea mediană a locuințelor (în dolari de 1.000 de dolari) și setul de probe de antrenament.
rf.boston = randomForest(medv~., data = boston, subset = train)rf.bostonImprimarea pădurii aleatoare oferă un rezumat al acesteia: numărul de arbori (au fost crescuți 500), reziduurile medii pătratice (MSR) și procentul de varianță explicată. MSR și procentul de varianță explicată se bazează pe estimările out-of-bag, un dispozitiv foarte inteligent în pădurile aleatoare pentru a obține estimări oneste ale erorilor.
Unicul parametru de reglare într-o Random Forests este argumentul numit mtry, care este numărul de variabile care sunt selectate la fiecare divizare a fiecărui arbore atunci când faceți o divizare. După cum se vede aici, mtry reprezintă 4 din cele 13 variabile exploratorii (cu excepția medv) din datele privind locuințele din Boston – ceea ce înseamnă că, de fiecare dată când arborele vine să divizeze un nod, 4 variabile vor fi selectate aleatoriu, apoi divizarea se va limita la 1 din aceste 4 variabile. Acesta este modul în care randomForests decorelează arborii.
Va trebui să ajustați o serie de păduri aleatoare. Există 13 variabile, deci să avem mtry intervalul mtry de la 1 la 13:
-
Pentru a înregistra erorile, configurați 2 variabile
oob.errșitest.err. -
Într-o buclă de
mtryde la 1 la 13, mai întâi potrivițirandomForestcu acea valoare a luimtrype setul de datetrain, restrângând numărul de arbori să fie 350. -
Apoi se extrage eroarea pătratică medie pe obiect (eroarea din afara sacului).
-
Apoi se face predicția pe setul de date de test (
boston) folosindfit(ajustarea luirandomForest). -
În cele din urmă, calculați eroarea de test: eroarea medie pătratică, care este egală cu
mean( (medv - pred) ^ 2 ).
oob.err = double(13)test.err = double(13)for(mtry in 1:13){ fit = randomForest(medv~., data = boston, subset=train, mtry=mtry, ntree = 350) oob.err = fit$mse pred = predict(fit, boston) test.err = with(boston, mean( (medv-pred)^2 ))}În principiu, tocmai ați crescut 4550 de arbori (de 13 ori 350). Acum haideți să facem un grafic folosind comanda matplot. Eroarea de test și eroarea din afara sacului sunt legate împreună pentru a face o matrice cu 2 coloane. Există alte câteva argumente în matrice, inclusiv valorile caracterelor de trasare (pch = 23 înseamnă diamant umplut), culorile (roșu și albastru), tipul este egal cu ambele (trasează ambele puncte și le conectează cu liniile) și numele axei y (Eroare medie pătratică). De asemenea, puteți pune o legendă în colțul din dreapta sus al graficului.
matplot(1:mtry, cbind(test.err, oob.err), pch = 23, col = c("red", "blue"), type = "b", ylab="Mean Squared Error")legend("topright", legend = c("OOB", "Test"), pch = 23, col = c("red", "blue"))În mod normal, aceste 2 curbe ar trebui să se alinieze, dar se pare că eroarea de test este puțin mai mică. Cu toate acestea, există o mare variabilitate în aceste estimări ale erorii de testare. Deoarece estimarea erorii din afara sacului a fost calculată pe un set de date, iar estimarea erorii de testare a fost calculată pe un alt set de date, aceste diferențe se încadrează destul de bine în limitele erorilor standard.
Observați că curba roșie este ușor deasupra curbei albastre? Aceste estimări de eroare sunt foarte corelate, deoarece randomForest cu mtry = 4 este foarte asemănătoare cu cea cu mtry = 5. Acesta este motivul pentru care fiecare dintre curbe este destul de netedă. Ceea ce vedeți este că mtry în jurul valorii de 4 pare a fi cea mai optimă alegere, cel puțin pentru eroarea de testare. Această valoare a lui mtry pentru eroarea de ieșire din sac este egală cu 9.
Deci, cu foarte puține niveluri, ați ajustat un model de predicție foarte puternic folosind păduri aleatoare. Cum așa? Partea din stânga arată performanța unui singur arbore. Eroarea pătratică medie pe out-of-bag este de 26, iar dvs. ați coborât la aproximativ 15 (puțin peste jumătate). Acest lucru înseamnă că ați redus eroarea la jumătate. La fel și pentru eroarea de test, ați redus eroarea de la 20 la 12.
Boosting
În comparație cu pădurile aleatoare, boosting-ul crește arbori mai mici și mai stufoși și merge la bias. Veți folosi pachetul GBM (Gradient Boosted Modeling), în R.
require(gbm)GBM cere distribuția, care este Gaussiană, pentru că veți face pierderi de eroare pătratică. Veți cere GBM pentru 10.000 de arbori, ceea ce pare mult, dar aceștia vor fi arbori superficiali. Adâncimea interacțiunii este numărul de diviziuni, deci doriți 4 diviziuni în fiecare arbore. Shrinkage este 0,01, care este cât de mult veți micșora pasul înapoi al arborelui.
boost.boston = gbm(medv~., data = boston, distribution = "gaussian", n.trees = 10000, shrinkage = 0.01, interaction.depth = 4)summary(boost.boston)Funcția summary oferă un grafic de importanță variabilă. Se pare că există 2 variabile care au o importanță relativă mare: rm (numărul de camere) și lstat (procentul de persoane cu statut economic inferior din comunitate). Să reprezentăm grafic aceste 2 variabile:
plot(boost.boston,i="lstat")plot(boost.boston,i="rm")Primul grafic arată că, cu cât este mai mare proporția de persoane cu statut economic inferior din suburbie, cu atât este mai mică valoarea prețurilor locuințelor. Al 2-lea grafic arată relația inversă cu numărul de camere: numărul mediu de camere din casă crește pe măsură ce crește prețul.
Este timpul să prezicem un model boosted pe setul de date de test. Să ne uităm la performanța testului în funcție de numărul de arbori:
-
În primul rând, faceți o grilă de număr de arbori în pași de 100 de la 100 la 10.000.
-
Apoi, rulați funcția
predictpe modelul boosted. Aceasta ian.treesca argument și produce o matrice de predicții pe datele de test. -
Dimensiunile matricei sunt 206 observații de test și 100 de vectori de predicție diferiți la cele 100 de valori diferite ale arborelui.
n.trees = seq(from = 100, to = 10000, by = 100)predmat = predict(boost.boston, newdata = boston, n.trees = n.trees)dim(predmat)
Este timpul să calculăm eroarea de test pentru fiecare dintre vectorii de predicție:
-
predmateste o matrice,medveste un vector, deci (predmat–medv) este o matrice de diferențe. Puteți utiliza funcțiaapplypentru coloanele acestor diferențe pătrate (media). Aceasta ar calcula eroarea pătratică medie pe coloane pentru vectorii de predicție. -
Apoi faceți un grafic folosind parametri similari cu cel folosit pentru Random Forest. Acesta ar arăta un grafic al erorii de amplificare.
boost.err = with(boston, apply( (predmat - medv)^2, 2, mean) )plot(n.trees, boost.err, pch = 23, ylab = "Mean Squared Error", xlab = "# Trees", main = "Boosting Test Error")abline(h = min(test.err), col = "red")
Eroarea de amplificare scade destul de mult pe măsură ce crește numărul de arbori. Aceasta este o dovadă care arată că boosting-ul este reticent la supraadaptare. Să includem, de asemenea, cea mai bună eroare de testare din RandomForest în grafic. Boosting-ul obține de fapt o cantitate rezonabilă sub eroarea de testare pentru randomForest.
Concluzie
Așa că acesta este sfârșitul acestui tutorial R privind construirea modelelor de arbori de decizie: arbori de clasificare, păduri aleatoare și arbori boostați. Ultimele 2 sunt metode puternice pe care le puteți folosi oricând, la nevoie. Din experiența mea, boosting depășește, de obicei, RandomForest, dar RandomForest este mai ușor de implementat. În RandomForest, singurul parametru de reglare este numărul de arbori; în timp ce în boosting, sunt necesari mai mulți parametri de reglare în afară de numărul de arbori, inclusiv micșorarea și adâncimea de interacțiune.
Dacă doriți să aflați mai multe, nu uitați să aruncați o privire la cursul nostru Machine Learning Toolbox pentru R.
.