Quantrium Guides
.

Tesseract este un motor de recunoaștere optică a caracterelor care poate fi folosit pe diferite sisteme de operare. Este un software liber, lansat sub licența Apache. Inițial, Tesseract a fost dezvoltat de Hewlett-Packard ca software proprietar în anii 1980, ulterior, a fost lansat ca software open source în 2005. Apoi, din 2006, dezvoltarea sa a fost sponsorizată de Google. În acest ghid, vă voi prezenta pașii pe care i-am urmat pentru a instala Tesseract pe mașina mea cu Windows 10. De asemenea, vă voi arăta cum puteți utiliza tesseract din linia de comandă după ce l-ați instalat cu succes.
Pentru a instala Tesseract 4 pe sistemul nostru Windows, accesați următorul link:
Descărcați fișierul executabil pentru Windows făcând clic pe hyperlinkul intitulat tesseract-ocr-w64-setup-v4.1.0.20190314.exe. Va apărea o notificare care vă va cere să salvați un fișier exe intitulat „Tesseract-ocr-w64-setup-v4.1.0.20190314.exe”. Salvați acest fișier .exe oriunde aveți suficient spațiu de stocare.
Deschideți acest fișier .exe. Dacă fereastra vă întreabă „Do you want to allow this software to make changes to your system”, faceți clic pe yes. Veți fi condus la secțiunea de instalare.
Apăsați următorul, faceți clic pe Sunt de acord cu termenii și condițiile și după ce selectați pentru cine și pentru cine doriți să instalați Tesseract (oricine folosește acest calculator/doar pentru mine. Puteți selecta oricare dintre ele), faceți clic pe următorul.
Blocați căsuțele care spun „ScrollView”, „Training Tools”, „Shortcuts creation” și, important, „Language data”. Acestea ar trebui să fie bifate în mod implicit, dar bifați-le doar în cazul în care nu au fost bifate în sistemul dumneavoastră.
Acum, dacă doriți să faceți predicții în limbi străine, cum ar fi japoneza, chineza, kurda sau limbi indiene, cum ar fi hindi, tamil, bengali etc., bifați și „Additional script data” și „Additional language data”. Dacă doriți să faceți predicții doar pentru limba engleză, nu trebuie să bifați această opțiune.
Click pe Next (Următorul). Selectați directorul în care doriți să instalați Tesseract. În mod implicit, pentru mine apare C:\Program Files\Tesseract-OCR și acolo l-am instalat. Îl puteți instala după alegerea dvs. Dar țineți cont de calea în care ați instalat Tesseract pe calculatorul dumneavoastră. Acest lucru este important.
Acum puteți selecta folderul din meniul de start în care doriți să creați comanda rapidă a programelor. Eu am creat-o într-un dosar numit „Tesseract-OCR”. Dacă o doriți într-un dosar nou, trebuie doar să introduceți numele dosarului în spațiul gol de sub textul „Select the Start Menu folder in which you would like ….” (Selectați dosarul din meniul Start în care doriți ….).
De asemenea, puteți bifa căsuța „Do not create shortcuts” (Nu creați scurtături) din stânga jos dacă nu doriți să creați nicio scurtătură. După ce ați terminat de selectat opțiunea preferată, faceți clic pe install. Ar trebui să dureze câteva minute pentru ca instalarea să aibă loc.
După ce instalarea s-a terminat, mergeți în directorul în care ați instalat Tesseract. Dorim să folosim Tesseract din linia de comandă Windows și, pentru a face acest lucru, trebuie să adăugăm Tesseract la calea noastră în variabila de mediu a sistemului.
Pentru a face acest lucru, faceți clic pe butonul de start pe Windows și căutați „variabila de mediu”. Veți vedea un rezultat numit „Edit the system environment variables”. Faceți clic pe acesta. După ce faceți clic pe acesta, ar trebui să vă aflați în secțiunea „Advanced” (Avansat) din „System properties” (Proprietăți de sistem), iar în dreapta jos ar trebui să fie vizibil un buton numit „Environment Variables ….” (Variabile de mediu). Faceți clic pe acel buton.
Acum, veți vedea aici două tabele. Unul numit User variables for <username>. Aici, <username> este o variabilă care reprezintă numele de utilizator care utilizează PC-ul în prezent. Celălalt tabel numit „Variabile de sistem”. În tabelul „System variables” (Variabile de sistem) faceți clic pe variabila numită „Path” (Calea de acces) și apoi faceți clic pe acest buton numit „Edit” (Editare) chiar deasupra butonului „OK”, așa cum se arată mai jos în captura de ecran de mai jos.
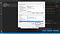
După ce ați terminat cu acest lucru, veți vedea o pagină numită „Edit environment variable”. Aici, în dreapta sus, veți vedea un buton numit „New” (Nou). Faceți clic pe acel buton „New”. Veți obține un spațiu gol în care puteți adăuga un text. Aici, adăugați numele directorului în care sunt stocate toate fișierele Tesseract-OCR.
După ce ați tastat numele directorului, apăsați „Enter” și verificați dacă numele directorului dvs. a fost adăugat la „Edit environment variable table”. După ce a fost, faceți clic pe „OK”. Faceți din nou clic pe OK în pagina „Environment Variables” (Variabile de mediu). Faceți din nou clic pe „OK” în pagina „System Properties” (Proprietăți de sistem). Trebuie să fi ieșit acum din toate opțiunile de configurare.
Deschideți promptul de comandă și tastați tesseract --version în promptul de comandă și apăsați Enter. Veți vedea ceva de genul acesta:
Dacă vedeți vreo eroare de genul tesseract command not found, cel mai probabil ați făcut o greșeală în timp ce ați urmat acest ghid. Întoarceți-vă și vedeți unde ați greșit și încercați să o remediați. Alternativ, puteți repeta din nou întregul proces.
Frumos! Acum aveți Tesseract instalat pe mașina dumneavoastră. Puteți începe să vă jucați cu el și să îl explorați mai departe.
Cum să utilizați Tesseract 4 folosind linia de comandă pe o mașină Windows
În primul rând, asigurați-vă că aveți un document scris de mână sau un document dactilografiat sub forma unei imagini. Să spunem că aveți o fotografie sub formă de png numită handwritten_photo_1 pe Desktop și doriți să testați Tesseract cu ea. Deschideți promptul de comandă. Veți începe în acest director:
C:\Users\username>
unde username este numele dvs. de utilizator pe acel sistem. Trebuie să intru în directorul desktop. Așa că folosesc următoarea comandă:
C:\Users\username> cd Desktop
Acum mă aflu în directorul Desktop, unde se află imaginea mea. Puteți vedea ce prezice Tesseract textul din document folosind următoarea comandă:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseract va afișa direct textul în linia de comandă propriu-zisă. Parametrul -l este utilizat pentru a specifica limba. Aici am specificat-o ca fiind în limba engleză, ceea ce oricum este cazul în mod implicit, astfel încât utilizarea -l eng a fost redundantă în acest caz. Dacă doriți să utilizați o altă limbă pentru OCR, consultați acest link de aici, care conține toate fișierele .traineddata, care specifică limba:
Să spunem că aveți un document text scris în hindi. Apoi, mergeți la acest link de mai sus, faceți clic pe fișierul intitulat hin.traineddata și descărcați-l. După ce l-ați descărcat, trebuie să vă mutați în folderul „tessdata”, care se va afla în interiorul directorului în care ați instalat inițial tesseract. După ce ați făcut acest lucru, puteți efectua OCR-ul documentelor hindi folosind următoarea comandă:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
În loc să afișați rezultatul OCR-ului pe linia de comandă propriu-zisă, să spunem că doriți ca rezultatul OCR-ului să fie stocat într-un fișier text. În acest caz, puteți introduce în schimb următoarea comandă:
tesseract handwritten_photo_1.png output.txt
Textul din handwritten_photo_1.png va fi stocat într-un fișier text numit output.txt care va fi localizat în directorul de lucru actual, care în cazul meu a fost Desktop.
Tesseract poate lua, de asemenea, un fișier text ca intrare, în care textul trebuie să conțină toate căile absolute ale imaginilor pe care doriți să le procesați.
Acest lucru este deosebit de util atunci când, să spunem că aveți două imagini scrise de mână în limba engleză numite handwritten_photo_1.png și handwritten_photo_2.png în directorul C:\Program Files. Acum, în actualul dvs. director de lucru, aveți un fișier text numit input.txt al cărui conținut este:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
În prima și, respectiv, a doua linie.
Acum, dacă doriți să stocați conținutul acestor două fotografii scrise de mână într-un fișier text, puteți face doar următoarele:
tesseract input.txt output.txt -l eng
output.txt va avea conținutul OCR al ambelor handwritten_photo_1.png și handwritten_photo_2.png, în această ordine. Aici, trebuie să rețineți că input.txt se afla în directorul de lucru curent. Puteți utiliza tesseract pe un fișier text care nu se află nici în directorul de lucru actual, incluzând locația directorului, ca aici:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt va fi din nou localizat în directorul de lucru actual. Puteți face acest lucru și pentru mai mult de două fotografii. Rețineți că predicția pentru o nouă fotografie în fișierul output.txt va fi precedată de un simbol ca:
Atunci, în acest caz, Viral Calic este predicția pentru prima imagine, CY am the king of the world predicția pentru a doua imagine, Com and Serr predicția pentru a treia imagine și așa mai departe. Puteți verifica rezultatul pentru toate imaginile de intrare și puteți verifica acuratețea predicțiilor.
Așa este! Felicitări, acum sunteți pregătit și gata să utilizați Tesseract pe sistemul dumneavoastră Windows 10.
.