Introducere
Este esențial să înțelegeți comportamentul clienților în orice industrie. Mi-am dat seama de acest lucru anul trecut când directorul meu de marketing m-a întrebat – „Puteți să-mi spuneți ce clienți existenți ar trebui să vizăm pentru noul nostru produs?”
Aceasta a fost o curbă de învățare pentru mine. Mi-am dat seama rapid, în calitate de cercetător de date, cât de important este să segmentez clienții, astfel încât organizația mea să poată adapta și construi strategii țintite. Acesta este locul în care conceptul de grupare a venit la îndemână!
Problemele precum segmentarea clienților sunt adesea înșelător de complicate, deoarece nu lucrăm cu nicio variabilă țintă în minte. Suntem oficial pe tărâmul învățării nesupravegheate, unde trebuie să ne dăm seama de tipare și structuri fără a avea în minte un rezultat stabilit. Este atât provocator, cât și palpitant ca cercetător de date.
Acum, există câteva moduri diferite de a efectua gruparea (după cum veți vedea mai jos). În acest articol vă voi prezenta un astfel de tip – clusterizarea ierarhică.
Vom învăța ce este clusterizarea ierarhică, avantajul său față de ceilalți algoritmi de clusterizare, diferitele tipuri de clusterizare ierarhică și pașii pentru a o realiza. În final, vom prelua un set de date de segmentare a clienților și apoi vom implementa clusterizarea ierarhică în Python. Iubesc această tehnică și sunt sigur că și voi veți face la fel după acest articol!
Nota: După cum am menționat, există mai multe moduri de a efectua clusterizarea. Vă încurajez să consultați ghidul nostru minunat despre diferitele tipuri de clustering:
- An Introduction to Clustering and different methods of clustering
Pentru a afla mai multe despre clustering și alți algoritmi de învățare automată (atât supravegheați cât și nesupravegheați) consultați următorul program cuprinzător-
- Certified AI & ML Blackbelt+ Program
Tabelă de materii
- Învățare supervizată vs. învățare nesupervizată
- De ce Clusterizare ierarhică?
- Ce este Clusterizarea ierarhică?
- Tipuri de ierarhizare ierarhică
- Agglomerative Hierarchical Clustering
- Divisive Hierarchical Clustering
- Etapele de realizare a ierarhizării ierarhice
- Cum se alege numărul de clustere în ierarhizare ierarhică?
- Soluționarea unei probleme de segmentare a clienților angro folosind ierarhizarea ierarhică
Învățare supravegheată vs. învățare nesupravegheată
Este important să înțelegem diferența dintre învățarea supravegheată și nesupravegheatăînvățarea nesupravegheată înainte de a ne scufunda în ierarhizarea ierarhică. Permiteți-mi să explic această diferență folosind un exemplu simplu.
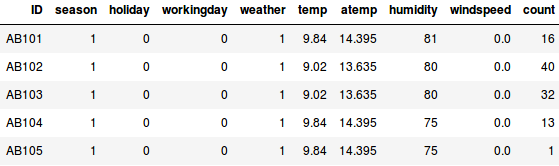
Să presupunem că vrem să estimăm numărul de biciclete care vor fi închiriate într-un oraș în fiecare zi:
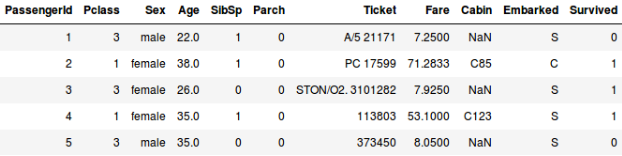
Sau, să spunem că vrem să prezicem dacă o persoană de la bordul Titanicului a supraviețuit sau nu:
Avem un obiectiv fix de atins în ambele exemple:
- În primul exemplu, trebuie să prezicem numărul de biciclete pe baza unor caracteristici precum anotimpul, vacanța, ziua de lucru, vremea, temperatura etc.
- În al doilea exemplu, trebuie să prezicem dacă un pasager a supraviețuit sau nu. În variabila „Survived”, 0 reprezintă faptul că persoana nu a supraviețuit, iar 1 înseamnă că persoana a scăpat cu viață. Variabilele independente includ aici Pclass, Sexul, Vârsta, Tariful, etc.
Atunci, atunci când ni se dă o variabilă țintă (număr și Supraviețuire în cele două cazuri de mai sus) pe care trebuie să o prezicem pe baza unui set dat de predictori sau variabile independente (sezon, vacanță, Sex, Vârstă, etc.), astfel de probleme se numesc probleme de învățare supravegheată.
Să ne uităm la figura de mai jos pentru a înțelege acest lucru din punct de vedere vizual:
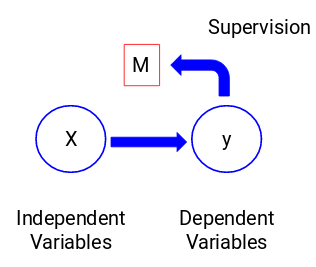
Aici, y este variabila noastră dependentă sau țintă, iar X reprezintă variabilele independente. Variabila țintă este dependentă de X și, prin urmare, se mai numește și variabilă dependentă. Ne antrenăm modelul folosind variabilele independente în supravegherea variabilei țintă și de aici și denumirea de învățare supravegheată.
Obiectivul nostru, atunci când antrenăm modelul, este de a genera o funcție care corelează variabilele independente cu ținta dorită. Odată ce modelul este antrenat, putem trece noi seturi de observații, iar modelul va prezice ținta pentru acestea. Aceasta este, pe scurt, învățarea supravegheată.
Ar putea exista situații în care nu avem nicio variabilă țintă de prezis. Astfel de probleme, fără nicio variabilă țintă explicită, sunt cunoscute ca probleme de învățare nesupravegheată. În aceste probleme avem doar variabilele independente și nicio variabilă țintă/dependentă.

În aceste cazuri încercăm să împărțim toate datele într-un set de grupuri. Aceste grupuri sunt cunoscute sub numele de clustere, iar procesul de realizare a acestor clustere este cunoscut sub numele de clusterizare.
Această tehnică este în general utilizată pentru gruparea unei populații în diferite grupe. Câteva exemple comune includ segmentarea clienților, gruparea documentelor similare împreună, recomandarea de melodii sau filme similare etc.
Există mult mai multe aplicații ale învățării nesupravegheate. Dacă întâlniți vreo aplicație interesantă, nu ezitați să o împărtășiți în secțiunea de comentarii de mai jos!
Acum, există diverși algoritmi care ne ajută să facem aceste clustere. Cei mai frecvent utilizați algoritmi de clustering sunt K-means și Hierarchical clustering.
De ce Hierarchical Clustering?
Ar trebui să știm mai întâi cum funcționează K-means înainte de a ne scufunda în clusteringul ierarhic. Credeți-mă, acest lucru va face conceptul de clusterizare ierarhică cu atât mai ușor.
Iată o scurtă prezentare generală a modului în care funcționează K-means:
- Decideți numărul de clustere (k)
- Selectați k puncte aleatoare din date ca centroizi
- Asemnați toate punctele la cel mai apropiat centroid al clusterelor
- Calculează centroidul clusterelor nou formate
- Repetă pașii 3 și 4
Este un proces iterativ. Acesta va continua să funcționeze până când centroizii clusterelor nou formate nu se schimbă sau până când se atinge numărul maxim de iterații.
Dar există anumite provocări cu K-means. Întotdeauna încearcă să formeze clustere de aceeași dimensiune. De asemenea, trebuie să decidem numărul de clustere la începutul algoritmului. În mod ideal, nu am ști câte clustere ar trebui să avem, la începutul algoritmului și, prin urmare, este o provocare cu K-means.
Aceasta este o lacună pe care clusterizarea ierarhică o acoperă cu aplomb. El înlătură problema de a trebui să definească în prealabil numărul de clustere. Sună ca un vis! Așadar, haideți să vedem ce este gruparea ierarhică și cum se îmbunătățește față de K-means.
Ce este gruparea ierarhică?
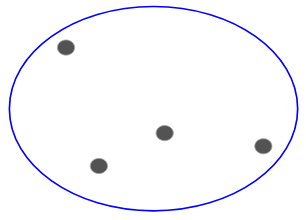
Să presupunem că avem punctele de mai jos și dorim să le grupăm în grupuri:

Potem să atribuim fiecare dintre aceste puncte unui cluster separat:

Acum, pe baza similitudinii acestor clustere, putem combina cele mai asemănătoare clustere împreună și să repetăm acest proces până când rămâne doar un singur cluster:
În esență, construim o ierarhie de clustere. Acesta este motivul pentru care acest algoritm se numește clusterizare ierarhică. Voi discuta cum să decidem numărul de clustere într-o secțiune ulterioară. Deocamdată, să analizăm diferitele tipuri de clusterizare ierarhică.
Tipuri de clusterizare ierarhică
Există în principal două tipuri de clusterizare ierarhică:
- Clusterizare ierarhică aglomerativă
- Clusterizare ierarhică divizivă
Să înțelegem fiecare tip în detaliu.
Agglomerative Hierarchical Clustering
În această tehnică atribuim fiecare punct unui cluster individual. Să presupunem că există 4 puncte de date. Vom atribui fiecare dintre aceste puncte unui cluster și, prin urmare, vom avea 4 clustere la început:
Apoi, la fiecare iterație, fuzionăm cea mai apropiată pereche de clustere și repetăm acest pas până când rămâne un singur cluster:
Fundem (sau adăugăm) clusterele la fiecare pas, nu? Prin urmare, acest tip de grupare este cunoscut și sub numele de grupare ierarhică aditivă.
Grupare ierarhică divizivă
Grupare ierarhică divizivă funcționează în mod opus. În loc să începem cu n clustere (în cazul a n observații), începem cu un singur cluster și atribuim toate punctele acelui cluster.
Atunci, nu contează dacă avem 10 sau 1000 de puncte de date. Toate aceste puncte vor aparține aceluiași cluster la început:
Acum, la fiecare iterație, împărțim cel mai îndepărtat punct din cluster și repetăm acest proces până când fiecare cluster conține doar un singur punct:
Împărțim (sau împărțim) clusterele la fiecare pas, de unde și denumirea de clusterizare ierarhică divizivă.
Clusterizarea aglomerativă este utilizată pe scară largă în industrie și aceasta va fi punctul central al acestui articol. Clusterizarea ierarhică divizivă va fi floare la ureche odată ce ne vom descurca cu tipul aglomerativ.
Etapele de realizare a clusterizării ierarhice
În clusterizarea ierarhică fuzionăm cele mai similare puncte sau clustere în clusterizarea ierarhică – știm acest lucru. Acum întrebarea este – cum decidem care puncte sunt similare și care nu sunt? Este una dintre cele mai importante întrebări în clustering!
Iată o modalitate de a calcula similaritatea – Luați distanța dintre centroidele acestor clustere. Punctele care au cea mai mică distanță sunt denumite puncte similare și le putem unifica. Ne putem referi la acesta și ca la un algoritm bazat pe distanță (din moment ce calculăm distanțele dintre clustere).
În clusterizarea ierarhică, avem un concept numit matrice de proximitate. Aceasta stochează distanțele dintre fiecare punct. Să luăm un exemplu pentru a înțelege această matrice, precum și pașii de realizare a clusterizării ierarhice.
Stabilirea exemplului

Să presupunem că o profesoară dorește să își împartă elevii în grupuri diferite. Ea are notele obținute de fiecare student la o temă și, pe baza acestor note, dorește să îi segmenteze în grupuri. Nu există o țintă fixă aici cu privire la câte grupe să aibă. Deoarece profesorul nu știe ce tip de studenți ar trebui să fie repartizați în ce grupă, aceasta nu poate fi rezolvată ca o problemă de învățare supravegheată. Așadar, vom încerca să aplicăm gruparea ierarhică aici și să segmentăm elevii în diferite grupe.
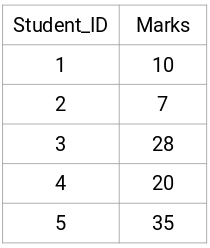
Să luăm un eșantion de 5 elevi:
Crearea unei matrice de proximitate
În primul rând, vom crea o matrice de proximitate care ne va spune distanța dintre fiecare dintre aceste puncte. Deoarece calculăm distanța fiecărui punct față de fiecare dintre celelalte puncte, vom obține o matrice pătrată de forma n X n (unde n este numărul de observații).
Să creăm matricea de proximitate 5 x 5 pentru exemplul nostru:
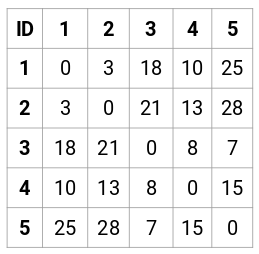
Elementele diagonale ale acestei matrice vor fi întotdeauna 0, deoarece distanța unui punct cu el însuși este întotdeauna 0. Vom folosi formula distanței euclidiene pentru a calcula restul distanțelor. Așadar, să spunem că dorim să calculăm distanța dintre punctul 1 și 2:
√(10-7)^2 = √9 = 3
Similare, putem calcula toate distanțele și umple matricea de proximitate.
Etapele de realizare a grupării ierarhice
Etapa 1: În primul rând, atribuim toate punctele unui cluster individual:
![]()
Culoarea diferită reprezintă aici clustere diferite. Puteți vedea că avem 5 clustere diferite pentru cele 5 puncte din datele noastre.
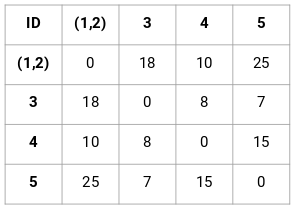
Pasul 2: În continuare, ne vom uita la cea mai mică distanță din matricea de proximitate și vom uni punctele cu cea mai mică distanță. Apoi actualizăm matricea de proximitate:
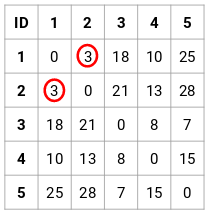
Aici, cea mai mică distanță este 3 și, prin urmare, vom fuziona punctele 1 și 2:
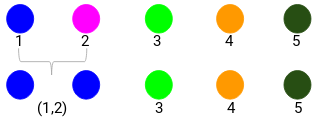
Să ne uităm la clusterele actualizate și să actualizăm în consecință matricea de proximitate:
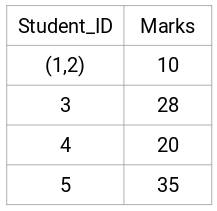
Aici, am luat maximul celor două mărci (7, 10) pentru a înlocui mărcile pentru acest cluster. În loc de maxim, putem lua, de asemenea, valoarea minimă sau valorile medii. Acum, vom calcula din nou matricea de proximitate pentru aceste clustere:
Pasul 3: Vom repeta pasul 2 până când va rămâne doar un singur cluster.
Acum, ne vom uita mai întâi la distanța minimă din matricea de proximitate și apoi vom fuziona cea mai apropiată pereche de clustere. Vom obține clusterele fuzionate după cum se arată mai jos, după repetarea acestor pași:
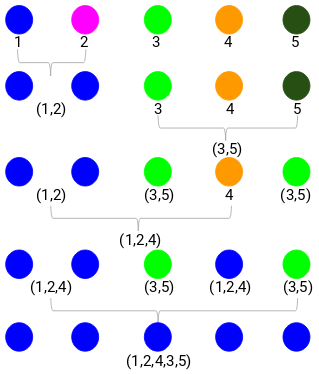
Am început cu 5 clustere și în final avem un singur cluster. Acesta este modul în care funcționează clusterizarea ierarhică aglomerativă. Dar întrebarea arzătoare rămâne în continuare – cum decidem numărul de clustere? Să înțelegem acest lucru în secțiunea următoare.
Cum ar trebui să alegem numărul de clustere în clusterizarea ierarhică?
Pregătiți să răspundem în sfârșit la această întrebare care ne dă târcoale de când am început să învățăm? Pentru a obține numărul de clustere pentru clusterizarea ierarhică, ne folosim de un concept minunat numit Dendrogramă.
O dendrogramă este o diagramă arborescentă care înregistrează secvențele de fuziuni sau diviziuni.
Să ne întoarcem la exemplul nostru profesor-elev. De fiecare dată când fuzionăm două clustere, o dendrogramă va înregistra distanța dintre aceste clustere și o va reprezenta sub formă de grafic. Să vedem cum arată o dendrogramă:
Avem eșantioanele din setul de date pe axa x și distanța pe axa y. Ori de câte ori două clustere sunt fuzionate, le vom uni în această dendrogramă, iar înălțimea unirii va fi distanța dintre aceste puncte. Să construim dendrograma pentru exemplul nostru:
Luați-vă un moment pentru a procesa imaginea de mai sus. Am început prin fuzionarea eșantioanelor 1 și 2, iar distanța dintre aceste două eșantioane a fost 3 (consultați prima matrice de proximitate din secțiunea anterioară). Să reprezentăm acest lucru în dendrogramă:
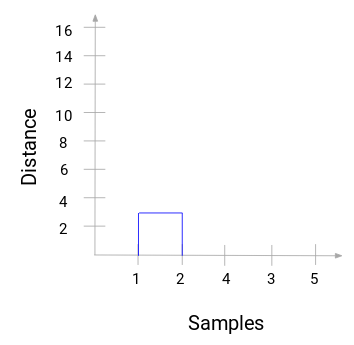
Aici, putem vedea că am fuzionat eșantionul 1 și 2. Linia verticală reprezintă distanța dintre aceste eșantioane. În mod similar, reprezentăm toate etapele în care am fuzionat clusterele și, în final, obținem o dendrogramă ca aceasta:
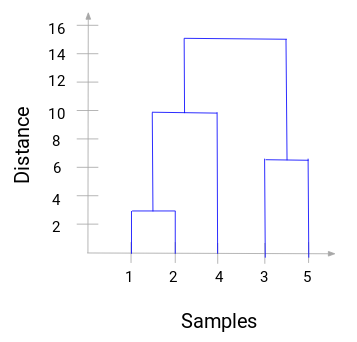
Potem vizualiza clar etapele grupării ierarhice. Cu cât este mai mare distanța dintre liniile verticale din dendrogramă, cu atât este mai mare distanța dintre aceste clustere.
Acum, putem seta o distanță de prag și trasa o linie orizontală (În general, încercăm să setăm pragul în așa fel încât să taie cea mai înaltă linie verticală). Să stabilim acest prag la 12 și să trasăm o linie orizontală:
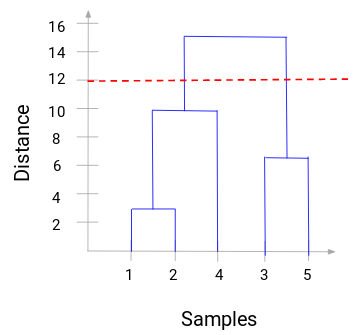
Numărul de clustere va fi numărul de linii verticale care sunt intersectate de linia trasată cu ajutorul pragului. În exemplul de mai sus, din moment ce linia roșie intersectează 2 linii verticale, vom avea 2 clustere. Un cluster va avea un eșantion (1,2,4), iar celălalt va avea un eșantion (3,5). Destul de simplu, nu-i așa?
Acesta este modul în care putem decide numărul de clustere folosind o dendrogramă în Hierarchical Clustering. În secțiunea următoare, vom implementa clusterizarea ierarhică, ceea ce vă va ajuta să înțelegeți toate conceptele pe care le-am învățat în acest articol.
Soluționarea problemei de segmentare a clienților angro folosind Hierarchical Clustering
Este timpul să ne murdărim mâinile în Python!
Vom lucra la o problemă de segmentare a clienților angro. Puteți descărca setul de date folosind acest link. Datele sunt găzduite pe depozitul UCI Machine Learning. Scopul acestei probleme este de a segmenta clienții unui distribuitor angro în funcție de cheltuielile lor anuale pentru diverse categorii de produse, cum ar fi laptele, alimentele, regiunea etc.
Să explorăm mai întâi datele și apoi să aplicăm Hierarchical Clustering pentru a segmenta clienții.
Primul lucru pe care îl vom face este să importăm bibliotecile necesare:
Încărcați datele și priviți primele rânduri:
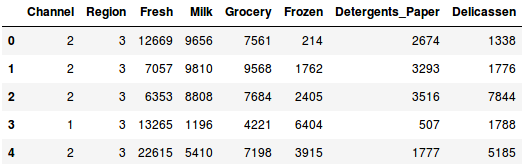
Există mai multe categorii de produse – Fresh, Milk, Grocery, etc. Valorile reprezintă numărul de unități achiziționate de fiecare client pentru fiecare produs. Scopul nostru este de a realiza clustere din aceste date care să poată segmenta clienții similari împreună. Vom folosi, bineînțeles, Clusterizarea ierarhică pentru această problemă.
Dar înainte de a aplica Clusterizarea ierarhică, trebuie să normalizăm datele astfel încât scara fiecărei variabile să fie aceeași. De ce este important acest lucru? Ei bine, dacă scara variabilelor nu este aceeași, modelul ar putea fi distorsionat către variabilele cu o magnitudine mai mare, cum ar fi Fresh sau Milk (consultați tabelul de mai sus).
Așa că, mai întâi să normalizăm datele și să aducem toate variabilele la aceeași scară:
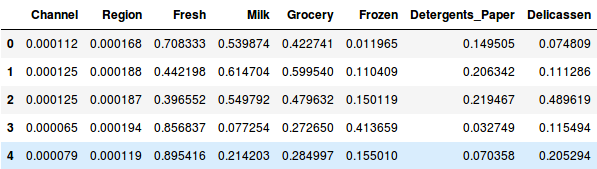
Aici, putem vedea că scara tuturor variabilelor este aproape similară. Acum, suntem gata să începem. Să desenăm mai întâi dendrograma pentru a ne ajuta să decidem numărul de clustere pentru această problemă particulară:
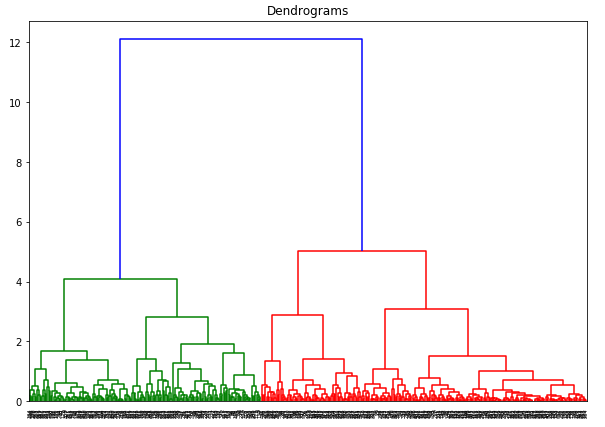
Axa x conține eșantioanele, iar axa y reprezintă distanța dintre aceste eșantioane. Linia verticală cu distanța maximă este linia albastră și, prin urmare, putem decide un prag de 6 și să tăiem dendrograma:
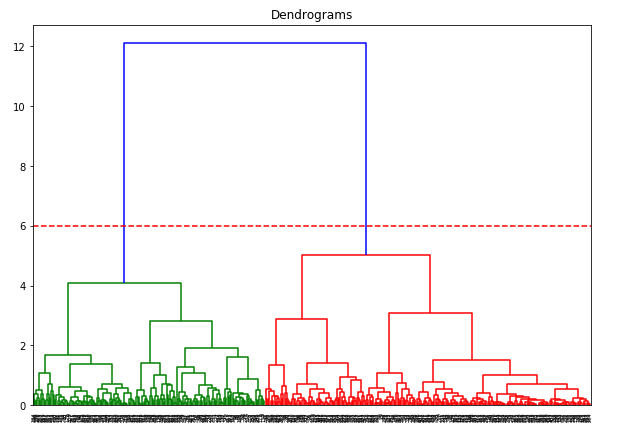
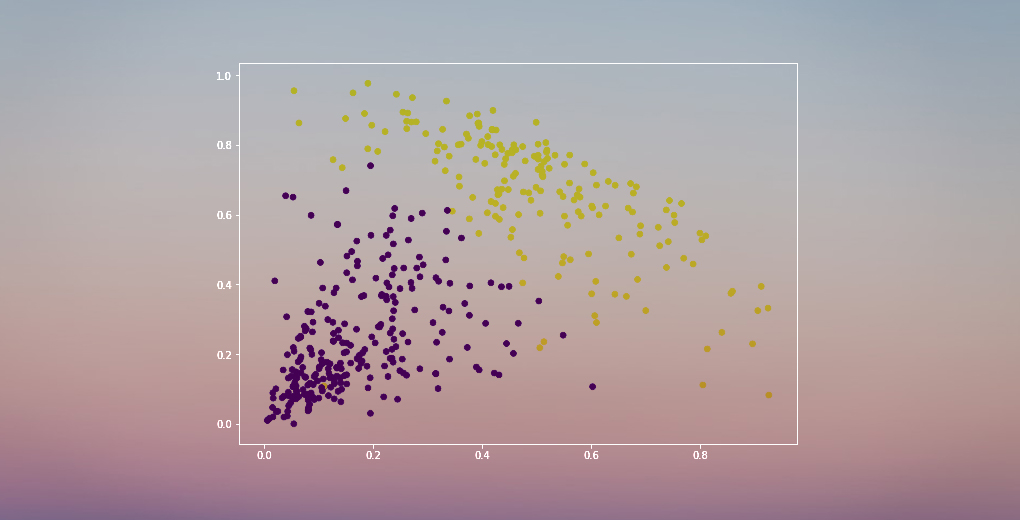
Avem două clustere, deoarece această linie taie dendrograma în două puncte. Să aplicăm acum gruparea ierarhică pentru 2 clustere:
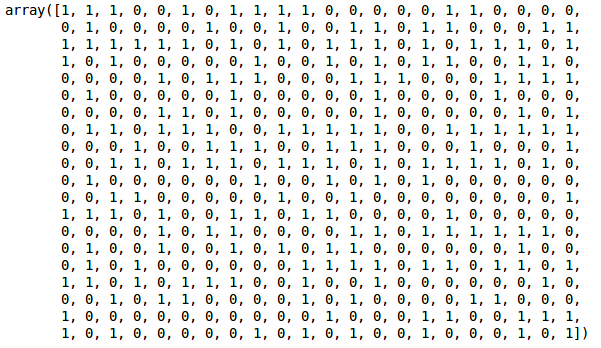
Potem vedea valorile de 0 și 1 în ieșire deoarece am definit 2 clustere. 0 reprezintă punctele care aparțin primului cluster, iar 1 reprezintă punctele din al doilea cluster. Să vizualizăm acum cele două clustere:
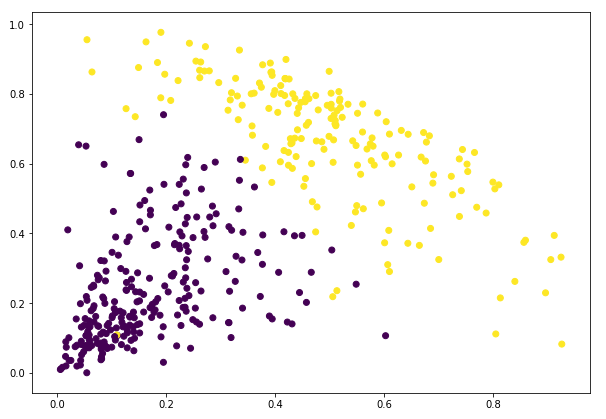
Frumos! Putem vizualiza clar cei doi clustere aici. Acesta este modul în care putem implementa gruparea ierarhică în Python.
Note de final
Gruparea ierarhică este o modalitate foarte utilă de segmentare a observațiilor. Avantajul de a nu trebui să predefini numărul de clustere îi conferă un avantaj destul de mare față de k-Means.
Dacă sunteți încă relativ nou în domeniul științei datelor, vă recomand cu căldură să urmați cursul Applied Machine Learning. Este unul dintre cele mai cuprinzătoare cursuri de învățare automată de la un capăt la altul pe care îl veți găsi oriunde. Clusterizarea ierarhică este doar unul dintre diversele subiecte pe care le abordăm în cadrul cursului.
.