Introduction
Il est crucial de comprendre le comportement des clients dans n’importe quelle industrie. Je m’en suis rendu compte l’année dernière lorsque mon directeur du marketing m’a demandé – » Pouvez-vous me dire quels clients existants nous devrions cibler pour notre nouveau produit ? «
Cela a été une sacrée courbe d’apprentissage pour moi. J’ai rapidement réalisé, en tant que scientifique des données, combien il est important de segmenter les clients afin que mon organisation puisse adapter et construire des stratégies ciblées. C’est là que le concept de clustering s’est avéré très utile !
Des problèmes comme la segmentation des clients sont souvent trompeusement délicats parce que nous ne travaillons pas avec une variable cible à l’esprit. Nous sommes officiellement dans la terre de l’apprentissage non supervisé où nous devons comprendre les modèles et les structures sans un résultat déterminé à l’esprit. C’est à la fois un défi et une expérience passionnante pour un scientifique des données.
Maintenant, il y a quelques façons différentes d’effectuer un clustering (comme vous le verrez ci-dessous). Je vais vous présenter l’un de ces types dans cet article – le clustering hiérarchique.
Nous allons apprendre ce qu’est le clustering hiérarchique, son avantage par rapport aux autres algorithmes de clustering, les différents types de clustering hiérarchique et les étapes pour l’effectuer. Nous allons enfin prendre un jeu de données de segmentation de la clientèle, puis mettre en œuvre le clustering hiérarchique en Python. J’adore cette technique et je suis sûr que vous le ferez aussi après cet article !
Note : Comme mentionné, il existe de multiples façons d’effectuer le clustering. Je vous encourage à consulter notre guide génial sur les différents types de clustering :
- An Introduction to Clustering and different methods of clustering
Pour en savoir plus sur le clustering et les autres algorithmes d’apprentissage automatique (supervisés et non supervisés), consultez le programme complet suivant .
- Programme certifié AI & ML Blackbelt+
Table des matières
- Apprentissage supervisé vs apprentissage non supervisé
- Pourquoi le clustering hiérarchique ?
- Qu’est-ce que le clustering hiérarchique ?
- Types de clustering hiérarchique
- Clustering hiérarchique agglutinant
- Clustering hiérarchique divisé
- Étapes de réalisation du clustering hiérarchique
- Comment choisir le nombre de clusters dans le clustering hiérarchique ?
- Résoudre un problème de segmentation de clients en gros à l’aide du clustering hiérarchique
Apprentissage supervisé vs apprentissage non supervisé
Il est important de comprendre la différence entre l’apprentissage supervisé et non supervisél’apprentissage non supervisé avant de nous plonger dans le clustering hiérarchique. Laissez-moi vous expliquer cette différence à l’aide d’un exemple simple.
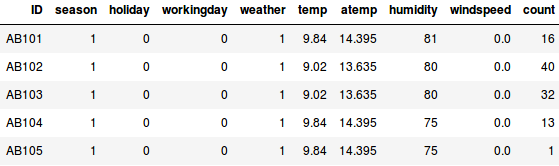
Supposons que nous voulons estimer le nombre de vélos qui seront loués dans une ville chaque jour :
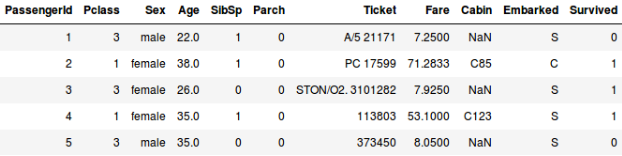
Ou, disons que nous voulons prédire si une personne à bord du Titanic a survécu ou non :
Nous avons un objectif fixe à atteindre dans ces deux exemples :
- Dans le premier exemple, nous devons prédire le nombre de vélos en fonction de caractéristiques comme la saison, les vacances, le jour de travail, le temps, la température, etc.
- Dans le deuxième exemple, nous devons prédire si un passager a survécu ou non. Dans la variable ‘Survived’, 0 représente que la personne n’a pas survécu et 1 signifie que la personne s’en est sortie vivante. Les variables indépendantes comprennent ici la classe P, le sexe, l’âge, le tarif, etc.
Donc, lorsqu’on nous donne une variable cible (le nombre et la survie dans les deux cas ci-dessus) que nous devons prédire en fonction d’un ensemble donné de prédicteurs ou de variables indépendantes (saison, vacances, sexe, âge, etc.), de tels problèmes sont appelés problèmes d’apprentissage supervisé.
Regardons la figure ci-dessous pour comprendre cela visuellement :
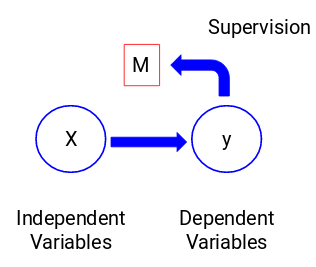
Ici, y est notre variable dépendante ou cible, et X représente les variables indépendantes. La variable cible dépend de X et donc elle est aussi appelée variable dépendante. Nous entraînons notre modèle en utilisant les variables indépendantes dans la supervision de la variable cible, d’où le nom d’apprentissage supervisé.
Notre objectif, lors de l’entraînement du modèle, est de générer une fonction qui met en correspondance les variables indépendantes avec la cible souhaitée. Une fois que le modèle est entraîné, nous pouvons passer de nouveaux ensembles d’observations et le modèle prédit la cible pour eux. Ceci, en un mot, est l’apprentissage supervisé.
Il peut y avoir des situations où nous n’avons pas de variable cible à prédire. De tels problèmes, sans variable cible explicite, sont connus comme des problèmes d’apprentissage non supervisé. Nous avons seulement les variables indépendantes et aucune variable cible/dépendante dans ces problèmes.

Nous essayons de diviser l’ensemble des données en un ensemble de groupes dans ces cas. Ces groupes sont connus sous le nom de clusters et le processus de réalisation de ces clusters est connu sous le nom de clustering.
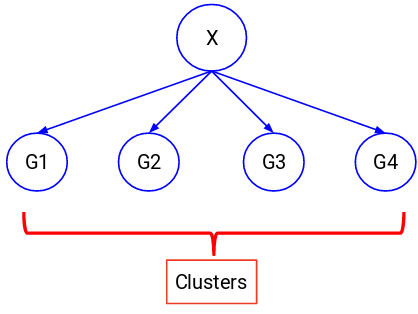
Cette technique est généralement utilisée pour regrouper une population en différents groupes. Quelques exemples courants incluent la segmentation des clients, le regroupement de documents similaires, la recommandation de chansons ou de films similaires, etc.
Il existe BEAUCOUP d’autres applications de l’apprentissage non supervisé. Si vous rencontrez une application intéressante, n’hésitez pas à les partager dans la section des commentaires ci-dessous !
Maintenant, il existe différents algorithmes qui nous aident à faire ces clusters. Les algorithmes de clustering les plus couramment utilisés sont K-means et le clustering hiérarchique.
Pourquoi le clustering hiérarchique ?
Nous devrions d’abord savoir comment fonctionne K-means avant de plonger dans le clustering hiérarchique. Croyez-moi, cela rendra le concept de clustering hiérarchique d’autant plus facile.
Voici un bref aperçu du fonctionnement de K-means :
- Décider du nombre de clusters (k)
- Sélectionner k points aléatoires dans les données comme centroïdes
- Assigner tous les points au centroïde de cluster le plus proche
- Calculer le centroïde des clusters nouvellement formés
- Répéter les étapes 3 et 4
C’est un processus itératif. Il continuera à fonctionner jusqu’à ce que les centroïdes des clusters nouvellement formés ne changent pas ou que le nombre maximum d’itérations soit atteint.
Mais il y a certains défis avec K-means. Il essaie toujours de faire des clusters de la même taille. Aussi, nous devons décider du nombre de clusters au début de l’algorithme. Idéalement, nous ne saurions pas combien de clusters nous devrions avoir, au début de l’algorithme et donc c’est un défi avec K-means.
C’est un écart que le clustering hiérarchique comble avec aplomb. Il supprime le problème de devoir prédéfinir le nombre de clusters. C’est un rêve ! Alors, voyons ce qu’est le clustering hiérarchique et comment il améliore les K-means.
Qu’est-ce que le clustering hiérarchique ?
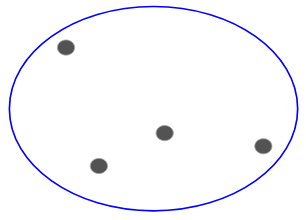
Disons que nous avons les points ci-dessous et que nous voulons les regrouper en groupes :

Nous pouvons affecter chacun de ces points à un cluster distinct :

Maintenant, sur la base de la similarité de ces clusters, nous pouvons combiner les clusters les plus similaires ensemble et répéter ce processus jusqu’à ce qu’il ne reste qu’un seul cluster:
Nous construisons essentiellement une hiérarchie de clusters. C’est pourquoi cet algorithme est appelé clustering hiérarchique. Je discuterai de la façon de décider du nombre de clusters dans une section ultérieure. Pour l’instant, examinons les différents types de clustering hiérarchique.
Types de clustering hiérarchique
Il existe principalement deux types de clustering hiérarchique :
- Clustering hiérarchique agglutinant
- Clustering hiérarchique divisant
Comprenons chaque type en détail.
Clustering hiérarchique agglutinant
Nous assignons chaque point à un cluster individuel dans cette technique. Supposons qu’il y ait 4 points de données. Nous allons affecter chacun de ces points à un cluster et donc avoir 4 clusters au début :
Puis, à chaque itération, nous fusionnons la paire de clusters la plus proche et nous répétons cette étape jusqu’à ce qu’il ne reste qu’un seul cluster :
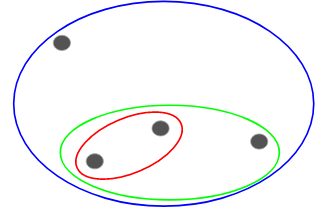
Nous fusionnons (ou ajoutons) les clusters à chaque étape, n’est-ce pas ? Par conséquent, ce type de clustering est également connu sous le nom de clustering hiérarchique additif.
Clustering hiérarchique divisé
Le clustering hiérarchique divisé fonctionne de manière opposée. Au lieu de commencer avec n clusters (dans le cas de n observations), on commence avec un seul cluster et on assigne tous les points à ce cluster.
Donc, peu importe que nous ayons 10 ou 1000 points de données. Tous ces points appartiendront au même cluster au début :
Maintenant, à chaque itération, nous scindons le point le plus éloigné dans le cluster et répétons ce processus jusqu’à ce que chaque cluster ne contienne qu’un seul point :
Nous scindons (ou divisons) les clusters à chaque étape, d’où le nom de clustering hiérarchique diviseur.
Le clustering agglutinant est largement utilisé dans l’industrie et ce sera l’objet de cet article. Le clustering hiérarchique divisé sera un jeu d’enfant une fois que nous aurons maîtrisé le type agglomératif.
Étapes pour effectuer le clustering hiérarchique
Nous fusionnons les points ou les clusters les plus similaires dans le clustering hiérarchique – nous le savons. Maintenant, la question est : comment décider quels points sont similaires et lesquels ne le sont pas ? C’est l’une des questions les plus importantes dans le clustering !
Voici une façon de calculer la similarité – Prenez la distance entre les centroïdes de ces clusters. Les points ayant la plus petite distance sont appelés points similaires et nous pouvons les fusionner. Nous pouvons également nous référer à cela comme un algorithme basé sur la distance (puisque nous calculons les distances entre les clusters).
Dans le clustering hiérarchique, nous avons un concept appelé matrice de proximité. Celle-ci stocke les distances entre chaque point. Prenons un exemple pour comprendre cette matrice ainsi que les étapes pour effectuer le clustering hiérarchique.
Mise en place de l’exemple

Supposons qu’une enseignante veuille diviser ses élèves en différents groupes. Elle dispose des notes obtenues par chaque étudiant dans un devoir et, en fonction de ces notes, elle veut les segmenter en groupes. Il n’y a pas d’objectif fixe quant au nombre de groupes à constituer. Puisque l’enseignant ne sait pas quel type d’étudiants doit être assigné à quel groupe, ce problème ne peut pas être résolu comme un problème d’apprentissage supervisé. Donc, nous allons essayer d’appliquer le clustering hiérarchique ici et de segmenter les étudiants en différents groupes.
Prenons un échantillon de 5 étudiants:
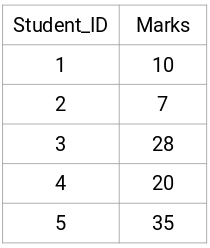
Création d’une matrice de proximité
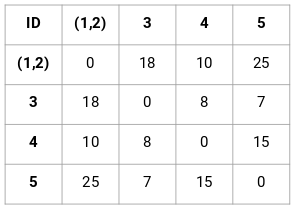
D’abord, nous allons créer une matrice de proximité qui nous indiquera la distance entre chacun de ces points. Puisque nous calculons la distance de chaque point par rapport à chacun des autres points, nous obtiendrons une matrice carrée de forme n X n (où n est le nombre d’observations).
Faisons la matrice de proximité 5 x 5 pour notre exemple :
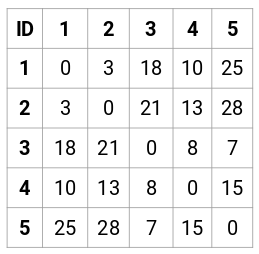
Les éléments diagonaux de cette matrice seront toujours 0 puisque la distance d’un point avec lui-même est toujours 0. Nous utiliserons la formule de la distance euclidienne pour calculer le reste des distances. Ainsi, disons que nous voulons calculer la distance entre le point 1 et 2 :
√(10-7)^2 = √9 = 3
De même, nous pouvons calculer toutes les distances et remplir la matrice de proximité.
Étapes pour effectuer un clustering hiérarchique
Étape 1 : D’abord, nous assignons tous les points à un cluster individuel :
![]()
Les différentes couleurs ici représentent les différents clusters. Vous pouvez voir que nous avons 5 clusters différents pour les 5 points de nos données.
Etape 2 : Ensuite, nous allons regarder la plus petite distance dans la matrice de proximité et fusionner les points avec la plus petite distance. Nous mettons alors à jour la matrice de proximité :
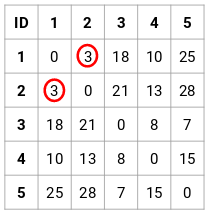
Ici, la plus petite distance est 3 et donc nous fusionnerons le point 1 et 2 :
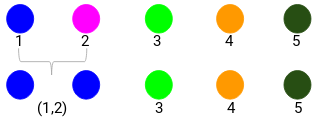
Regardons les clusters mis à jour et mettons en conséquence à jour la matrice de proximité :
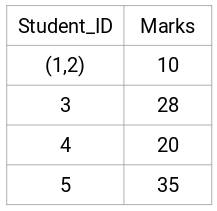
Ici, nous avons pris le maximum des deux marques (7, 10) pour remplacer les marques de ce cluster. Au lieu du maximum, nous pouvons également prendre la valeur minimale ou les valeurs moyennes. Maintenant, nous allons à nouveau calculer la matrice de proximité pour ces clusters :
Etape 3 : Nous allons répéter l’étape 2 jusqu’à ce qu’il ne reste qu’un seul cluster.
Donc, nous allons d’abord regarder la distance minimale dans la matrice de proximité et ensuite fusionner la paire de clusters la plus proche. Nous obtiendrons les clusters fusionnés comme indiqué ci-dessous après avoir répété ces étapes :
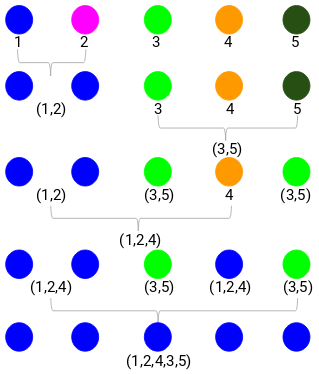
Nous avons commencé avec 5 clusters et nous avons finalement un seul cluster. C’est ainsi que fonctionne le clustering hiérarchique agglomératif. Mais la question brûlante demeure : comment décider du nombre de clusters ? Comprenons cela dans la section suivante.
Comment choisir le nombre de clusters dans le clustering hiérarchique ?
Prêts à répondre enfin à cette question qui traîne depuis le début de notre apprentissage ? Pour obtenir le nombre de clusters pour le clustering hiérarchique, nous faisons appel à un concept génial appelé Dendrogramme.
Un dendrogramme est un diagramme arborescent qui enregistre les séquences de fusions ou de scissions.
Revenons à notre exemple professeur-élève. Chaque fois que nous fusionnons deux clusters, un dendrogramme va enregistrer la distance entre ces clusters et la représenter sous forme de graphique. Voyons à quoi ressemble un dendrogramme :
Nous avons les échantillons du jeu de données sur l’axe des x et la distance sur l’axe des y. Chaque fois que deux clusters sont fusionnés, nous allons les joindre dans ce dendrogramme et la hauteur de la jointure sera la distance entre ces points. Construisons le dendrogramme pour notre exemple :
Prenez un moment pour traiter l’image ci-dessus. Nous avons commencé par fusionner l’échantillon 1 et 2 et la distance entre ces deux échantillons était de 3 (se référer à la première matrice de proximité dans la section précédente). Traçons cela dans le dendrogramme :
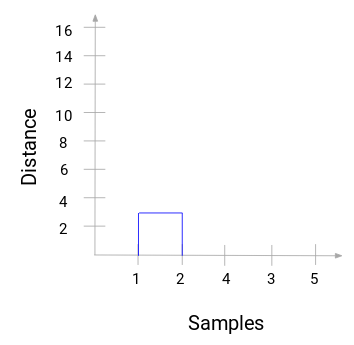
Ici, nous pouvons voir que nous avons fusionné l’échantillon 1 et 2. La ligne verticale représente la distance entre ces échantillons. De même, nous traçons toutes les étapes où nous avons fusionné les clusters et finalement, nous obtenons un dendrogramme comme celui-ci :
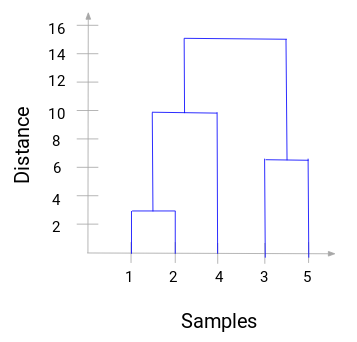
Nous pouvons clairement visualiser les étapes du clustering hiérarchique. Plus la distance des lignes verticales dans le dendrogramme, plus la distance entre ces clusters.
Maintenant, nous pouvons définir une distance seuil et dessiner une ligne horizontale (En général, nous essayons de définir le seuil de telle sorte qu’il coupe la ligne verticale la plus haute). Fixons ce seuil à 12 et dessinons une ligne horizontale:
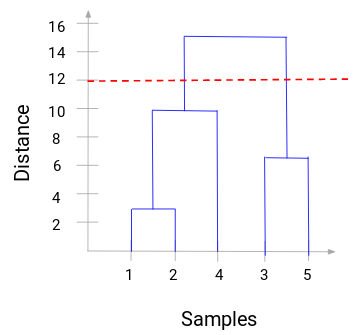
Le nombre de clusters sera le nombre de lignes verticales qui sont coupées par la ligne dessinée en utilisant le seuil. Dans l’exemple ci-dessus, puisque la ligne rouge intersecte 2 lignes verticales, nous aurons 2 clusters. Une grappe aura un échantillon (1,2,4) et l’autre aura un échantillon (3,5). Plutôt simple, non ?
C’est ainsi que nous pouvons décider du nombre de clusters en utilisant un dendrogramme dans le clustering hiérarchique. Dans la section suivante, nous mettrons en œuvre le clustering hiérarchique qui vous aidera à comprendre tous les concepts que nous avons appris dans cet article.
Solving the Wholesale Customer Segmentation problem using Hierarchical Clustering
Il est temps de se salir les mains en Python !
Nous allons travailler sur un problème de segmentation de clients en gros. Vous pouvez télécharger le jeu de données en utilisant ce lien. Les données sont hébergées sur le dépôt d’apprentissage machine de l’UCI. L’objectif de ce problème est de segmenter les clients d’un distributeur en gros en fonction de leurs dépenses annuelles pour diverses catégories de produits, comme le lait, l’épicerie, la région, etc.
Explorons d’abord les données, puis appliquons le clustering hiérarchique pour segmenter les clients.
Nous allons d’abord importer les bibliothèques requises :
Chargeons les données et regardons les premières lignes :
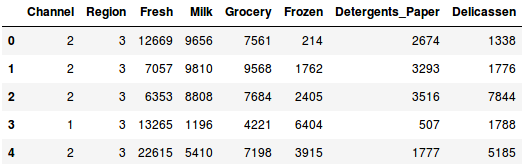
Il y a plusieurs catégories de produits – frais, lait, épicerie, etc. Les valeurs représentent le nombre d’unités achetées par chaque client pour chaque produit. Notre objectif est de faire des clusters à partir de ces données qui peuvent segmenter ensemble les clients similaires. Nous allons, bien sûr, utiliser le clustering hiérarchique pour ce problème.
Mais avant d’appliquer le clustering hiérarchique, nous devons normaliser les données afin que l’échelle de chaque variable soit la même. Pourquoi est-ce important ? Eh bien, si l’échelle des variables n’est pas la même, le modèle pourrait être biaisé vers les variables avec une magnitude plus élevée comme Fresh ou Milk (se référer au tableau ci-dessus).
Donc, normalisons d’abord les données et amenons toutes les variables à la même échelle:
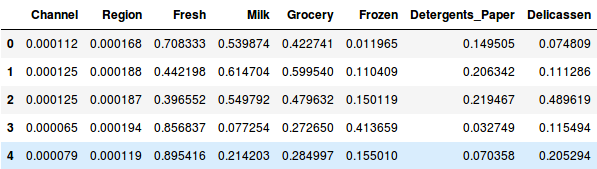
Ici, nous pouvons voir que l’échelle de toutes les variables est presque similaire. Maintenant, nous sommes prêts à partir. Dessinons d’abord le dendrogramme pour nous aider à décider du nombre de clusters pour ce problème particulier :
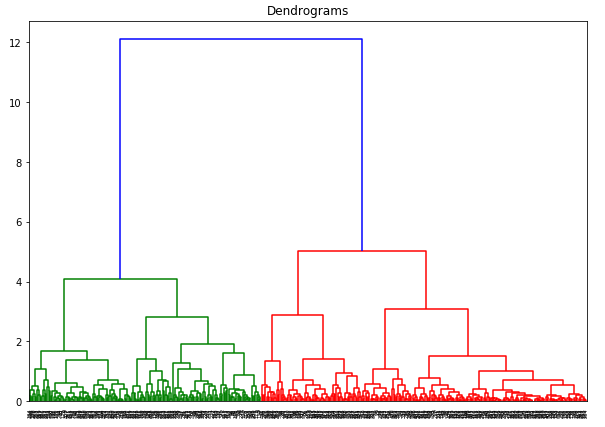
L’axe des x contient les échantillons et l’axe des y représente la distance entre ces échantillons. La ligne verticale avec la distance maximale est la ligne bleue et donc nous pouvons décider un seuil de 6 et couper le dendrogramme:
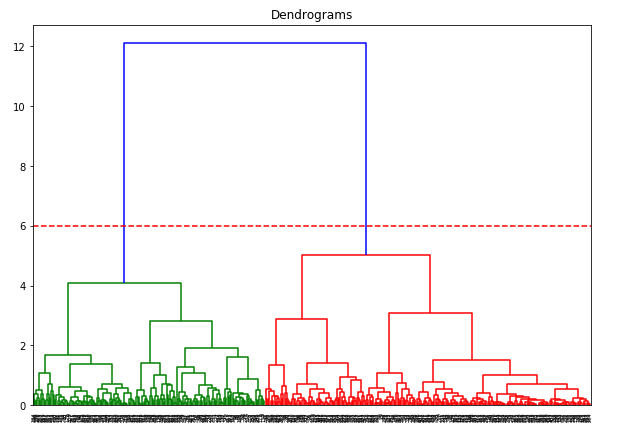
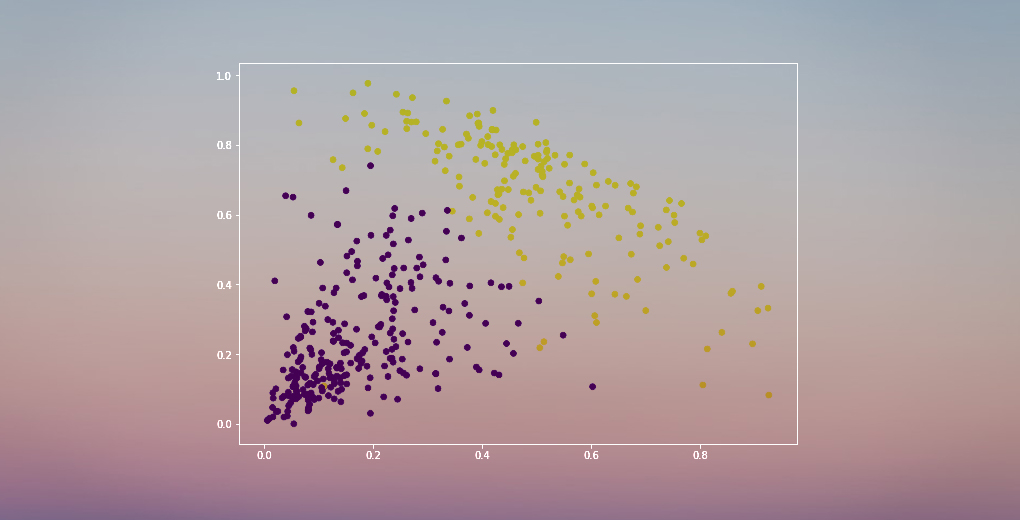
Nous avons deux clusters car cette ligne coupe le dendrogramme en deux points. Appliquons maintenant le clustering hiérarchique pour 2 clusters:
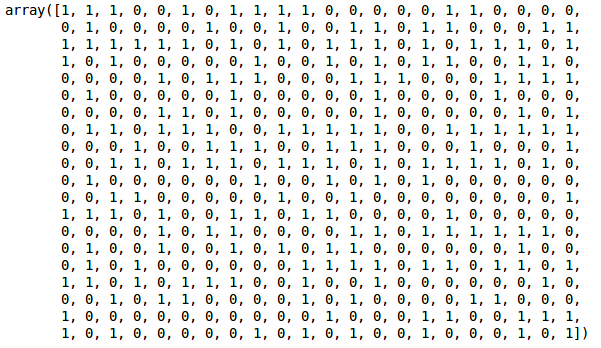
Nous pouvons voir les valeurs de 0s et de 1s dans la sortie puisque nous avons défini 2 clusters. 0 représente les points qui appartiennent au premier cluster et 1 représente les points du deuxième cluster. Visualisons maintenant les deux clusters:
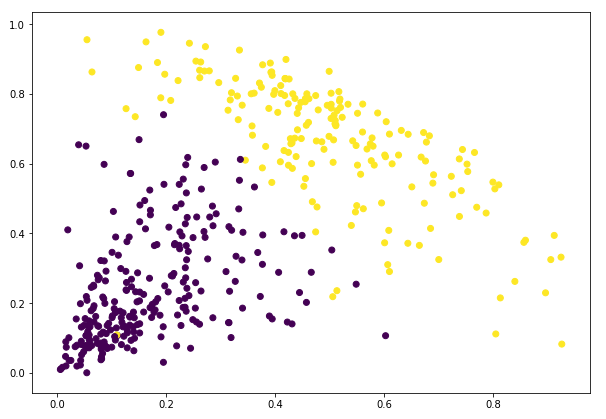
Awesome ! Nous pouvons clairement visualiser les deux clusters ici. Voilà comment nous pouvons mettre en œuvre le clustering hiérarchique en Python.
Notes de fin
Le clustering hiérarchique est un moyen super utile de segmenter les observations. L’avantage de ne pas avoir à prédéfinir le nombre de clusters lui donne tout à fait un avantage sur k-Means.
Si vous êtes encore relativement nouveau dans la science des données, je recommande vivement de suivre le cours Applied Machine Learning. C’est l’un des cours d’apprentissage automatique de bout en bout les plus complets que vous trouverez partout. Le clustering hiérarchique est juste l’un des divers sujets que nous couvrons dans le cours.