Introducción
Es crucial entender el comportamiento de los clientes en cualquier industria. Me di cuenta de esto el año pasado cuando mi jefe de marketing me preguntó – «¿Puedes decirme a qué clientes existentes deberíamos dirigirnos para nuestro nuevo producto?»
Eso fue toda una curva de aprendizaje para mí. Rápidamente me di cuenta, como científico de datos, de lo importante que es segmentar a los clientes para que mi organización pueda adaptar y crear estrategias específicas. Aquí es donde el concepto de clustering es muy útil.
Los problemas como la segmentación de clientes son a menudo engañosos porque no estamos trabajando con ninguna variable objetivo en mente. Estamos oficialmente en el terreno del aprendizaje no supervisado, en el que tenemos que descubrir patrones y estructuras sin un resultado fijo en mente. Es desafiante y emocionante como científico de datos.
Ahora, hay algunas maneras diferentes de realizar la agrupación (como verás a continuación). En este artículo le presentaré uno de estos tipos: el clustering jerárquico.
Aprenderemos qué es el clustering jerárquico, su ventaja sobre los otros algoritmos de clustering, los diferentes tipos de clustering jerárquico y los pasos para realizarlo. Finalmente tomaremos un conjunto de datos de segmentación de clientes y luego implementaremos el clustering jerárquico en Python. Me encanta esta técnica y estoy seguro de que tú también lo harás después de este artículo.
Nota: Como he mencionado, hay múltiples formas de realizar clustering. Te animo a que consultes nuestra impresionante guía sobre los diferentes tipos de clustering:
- Introducción al clustering y diferentes métodos de clustering
Para aprender más sobre clustering y otros algoritmos de aprendizaje automático (tanto supervisados como no supervisados) consulta el siguiente programa completo-.
- Programa certificado de IA & ML Blackbelt+
Tabla de contenidos
- Aprendizaje supervisado vs no supervisado
- ¿Por qué clustering jerárquico?
- ¿Qué es la agrupación jerárquica?
- Tipos de Clustering Jerárquico
- Clustering Jerárquico Aglomerado
- Clustering Jerárquico Divisivo
- Pasos para realizar Clustering Jerárquico
- ¿Cómo elegir el número de clusters en Clustering Jerárquico?
- Resolución de un Problema de Segmentación de Clientes Mayoristas utilizando Clustering Jerárquico
Aprendizaje Supervisado vs No Supervisado
Es importante entender la diferencia entre el aprendizaje supervisado y no supervisado-unsupervisado antes de sumergirnos en el clustering jerárquico. Permítanme explicar esta diferencia utilizando un ejemplo sencillo.
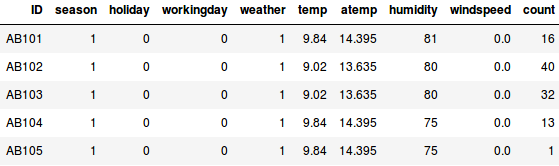
Supongamos que queremos estimar el recuento de bicicletas que se alquilarán en una ciudad cada día:
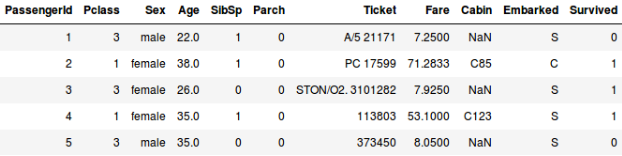
O bien, digamos que queremos predecir si una persona a bordo del Titanic sobrevivió o no:
Tenemos un objetivo fijo que alcanzar en estos dos ejemplos:
- En el primer ejemplo, tenemos que predecir el recuento de bicicletas en función de características como la estación del año, las vacaciones, la jornada laboral, el tiempo, la temperatura, etc.
- En el segundo ejemplo estamos prediciendo si un pasajero sobrevivió o no. En la variable ‘Sobrevivido’, 0 representa que la persona no sobrevivió y 1 significa que la persona salió viva. Las variables independientes aquí incluyen Pclass, Sexo, Edad, Tarifa, etc.
Así que, cuando se nos da una variable objetivo (recuento y Supervivencia en los dos casos anteriores) que tenemos que predecir basándonos en un conjunto dado de predictores o variables independientes (temporada, vacaciones, Sexo, Edad, etc.), estos problemas se denominan problemas de aprendizaje supervisado.
Veamos la siguiente figura para entenderlo visualmente:
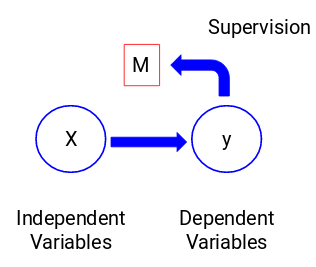
Aquí, y es nuestra variable dependiente o objetivo, y X representa las variables independientes. La variable objetivo depende de X y, por lo tanto, también se llama variable dependiente. Entrenamos nuestro modelo utilizando las variables independientes en la supervisión de la variable objetivo y de ahí el nombre de aprendizaje supervisado.
Nuestro objetivo, al entrenar el modelo, es generar una función que mapee las variables independientes con el objetivo deseado. Una vez entrenado el modelo, podemos pasar nuevos conjuntos de observaciones y el modelo predecirá el objetivo para ellos. Esto, en pocas palabras, es el aprendizaje supervisado.
Puede haber situaciones en las que no tengamos ninguna variable objetivo que predecir. Estos problemas, sin ninguna variable objetivo explícita, se conocen como problemas de aprendizaje no supervisado. En estos problemas sólo tenemos las variables independientes y ninguna variable objetivo/dependiente.

En estos casos tratamos de dividir todos los datos en un conjunto de grupos. Estos grupos se conocen como clusters y el proceso de hacer estos clusters se conoce como clustering.
Esta técnica se utiliza generalmente para agrupar una población en diferentes grupos. Algunos ejemplos comunes incluyen la segmentación de clientes, la agrupación de documentos similares, la recomendación de canciones o películas similares, etc.
Hay MUCHAS más aplicaciones del aprendizaje no supervisado. Si te encuentras con alguna aplicación interesante, no dudes en compartirla en la sección de comentarios más abajo.
Ahora, hay varios algoritmos que nos ayudan a hacer estos clusters. Los algoritmos de clustering más utilizados son K-means y clustering jerárquico.
¿Por qué clustering jerárquico?
Deberíamos saber primero cómo funciona K-means antes de sumergirnos en el clustering jerárquico. Créame, hará que el concepto de clustering jerárquico sea mucho más fácil.
Aquí hay un breve resumen de cómo funciona K-means:
- Decidir el número de clusters (k)
- Seleccionar k puntos aleatorios de los datos como centroides
- Asignar todos los puntos al centroide del cluster más cercano
- Calcular el centroide de los clusters recién formados
- Repetir los pasos 3 y 4
Es un proceso iterativo. Seguirá funcionando hasta que los centroides de los clusters recién formados no cambien o se alcance el número máximo de iteraciones.
Pero hay ciertos retos con K-means. Siempre trata de hacer clusters del mismo tamaño. Además, tenemos que decidir el número de clusters al principio del algoritmo. Idealmente, no sabríamos cuántos clusters deberíamos tener, al principio del algoritmo y por lo tanto es un reto con K-means.
Esta es una brecha clustering jerárquico puentes con aplomo. Quita el problema de tener que predefinir el número de clusters. ¡Suena como un sueño! Así pues, veamos qué es el clustering jerárquico y cómo mejora a K-means.
¿Qué es el clustering jerárquico?
Digamos que tenemos los siguientes puntos y queremos agruparlos:

Podemos asignar cada uno de estos puntos a un cluster distinto:

Ahora, basándonos en la similitud de estos clusters, podemos combinar los clusters más parecidos entre sí y repetir este proceso hasta que sólo quede un único cluster:
Esencialmente estamos construyendo una jerarquía de clusters. Por eso este algoritmo se llama clustering jerárquico. Discutiré cómo decidir el número de clusters en una sección posterior. Por ahora, veamos los diferentes tipos de clustering jerárquico.
Tipos de clustering jerárquico
Hay principalmente dos tipos de clustering jerárquico:
- Clustering jerárquico aglomerativo
- Clustering jerárquico divisivo
Entendamos cada tipo en detalle.
Clasificación jerárquica aglomerativa
En esta técnica asignamos cada punto a un cluster individual. Supongamos que hay 4 puntos de datos. Asignaremos cada uno de estos puntos a un clúster y, por tanto, tendremos 4 clústeres al principio:
Después, en cada iteración, fusionamos el par de clústeres más cercano y repetimos este paso hasta que sólo quede un único clúster:
Estamos fusionando (o añadiendo) los clústeres en cada paso, ¿verdad? Por lo tanto, este tipo de clustering también se conoce como clustering jerárquico aditivo.
Clustering jerárquico divisivo
El clustering jerárquico divisivo funciona de forma opuesta. En lugar de empezar con n clústeres (en caso de n observaciones), empezamos con un único clúster y asignamos todos los puntos a ese clúster.
Así, no importa si tenemos 10 o 1000 puntos de datos. Todos estos puntos pertenecerán al mismo clúster al principio:
Ahora, en cada iteración, dividimos el punto más lejano del clúster y repetimos este proceso hasta que cada clúster sólo contenga un único punto:
Estamos dividiendo (o dividiendo) los clústeres en cada paso, de ahí el nombre de clustering jerárquico divisivo.
El clustering aglomerativo es ampliamente utilizado en la industria y ese será el enfoque en este artículo. El clustering jerárquico divisivo será pan comido una vez que hayamos dominado el tipo aglomerativo.
Pasos para realizar el Clustering Jerárquico
Fusionamos los puntos o clusters más similares en el clustering jerárquico – lo sabemos. Ahora la pregunta es – ¿cómo decidimos qué puntos son similares y cuáles no? Es una de las preguntas más importantes en el clustering!
Aquí hay una forma de calcular la similitud – Tome la distancia entre los centroides de estos clusters. Los puntos que tienen la menor distancia se denominan puntos similares y podemos fusionarlos. Podemos referirnos a esto como un algoritmo basado en la distancia también (ya que estamos calculando las distancias entre los clusters).
En el clustering jerárquico, tenemos un concepto llamado matriz de proximidad. Esta almacena las distancias entre cada punto. Tomemos un ejemplo para entender esta matriz así como los pasos para realizar el clustering jerárquico.
Configuración del ejemplo

Supongamos que una profesora quiere dividir a sus alumnos en diferentes grupos. Tiene las notas obtenidas por cada alumno en una tarea y en base a ellas quiere segmentarlos en grupos. En este caso no hay un objetivo fijo sobre el número de grupos que debe tener. Dado que la profesora no sabe qué tipo de estudiantes deben ser asignados a cada grupo, no se puede resolver como un problema de aprendizaje supervisado. Por lo tanto, trataremos de aplicar el clustering jerárquico aquí y segmentar a los estudiantes en diferentes grupos.
Tomemos una muestra de 5 estudiantes:
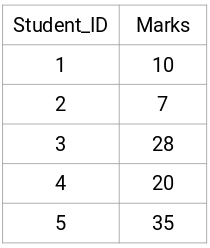
Creando una matriz de proximidad
Primero, crearemos una matriz de proximidad que nos dirá la distancia entre cada uno de estos puntos. Como estamos calculando la distancia de cada punto a cada uno de los otros puntos, obtendremos una matriz cuadrada de forma n X n (donde n es el número de observaciones).
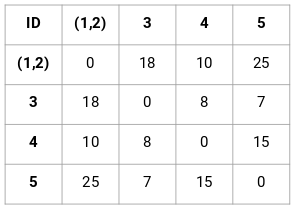
Hagamos la matriz de proximidad de 5 x 5 para nuestro ejemplo:
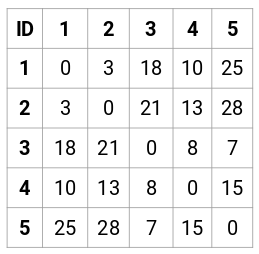
Los elementos diagonales de esta matriz serán siempre 0 ya que la distancia de un punto consigo mismo es siempre 0. Para calcular el resto de las distancias utilizaremos la fórmula de la distancia euclidiana. Así, digamos que queremos calcular la distancia entre el punto 1 y el 2:
√(10-7)^2 = √9 = 3
De forma similar, podemos calcular todas las distancias y rellenar la matriz de proximidad.
Pasos para realizar el Clustering Jerárquico
Paso 1: Primero, asignamos todos los puntos a un cluster individual:
![]()
Los diferentes colores aquí representan diferentes clusters. Puedes ver que tenemos 5 clusters diferentes para los 5 puntos de nuestros datos.
Paso 2: A continuación, miraremos la distancia más pequeña en la matriz de proximidad y fusionaremos los puntos con la distancia más pequeña. A continuación, actualizamos la matriz de proximidad:
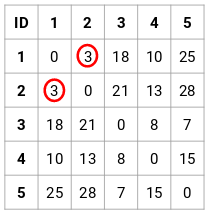
Aquí, la distancia más pequeña es 3 y, por tanto, fusionaremos los puntos 1 y 2:
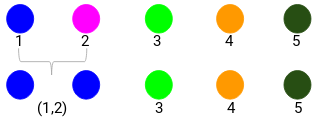
Miremos los clusters actualizados y, en consecuencia, actualicemos la matriz de proximidad:
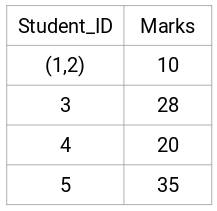
Aquí, hemos tomado el máximo de las dos marcas (7, 10) para sustituir las marcas de este cluster. En lugar del máximo, también podemos tomar el valor mínimo o los valores medios. Ahora, calcularemos de nuevo la matriz de proximidad para estos clusters:
Paso 3: Repetiremos el paso 2 hasta que sólo quede un único cluster.
Así, primero miraremos la distancia mínima en la matriz de proximidad y luego fusionaremos el par de clusters más cercano. Obtendremos los clusters fusionados como se muestra a continuación después de repetir estos pasos:
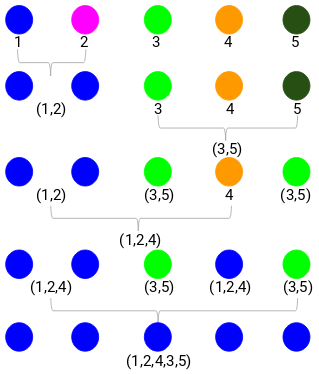
Empezamos con 5 clusters y finalmente tenemos un único cluster. Así es como funciona la agrupación jerárquica aglomerativa. Pero la pregunta candente sigue siendo: ¿cómo decidimos el número de clusters? Vamos a entenderlo en la siguiente sección.
¿Cómo debemos elegir el número de clusters en el clustering jerárquico?
¿Preparados para responder por fin a esta pregunta que lleva rondando desde que empezamos a aprender? Para obtener el número de conglomerados para el clustering jerárquico, hacemos uso de un concepto impresionante llamado Dendrograma.
Un dendrograma es un diagrama en forma de árbol que registra las secuencias de fusiones o divisiones.
Volvamos a nuestro ejemplo de profesor-alumno. Siempre que fusionemos dos clusters, un dendrograma registrará la distancia entre estos clusters y la representará en forma de gráfico. Veamos cómo es un dendrograma:
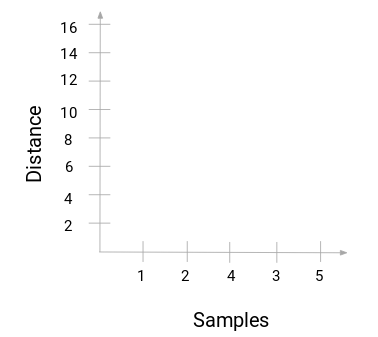
Tenemos las muestras del conjunto de datos en el eje x y la distancia en el eje y. Siempre que se fusionen dos clusters, los uniremos en este dendrograma y la altura de la unión será la distancia entre estos puntos. Construyamos el dendrograma para nuestro ejemplo:
Tome un momento para procesar la imagen anterior. Comenzamos fusionando las muestras 1 y 2 y la distancia entre estas dos muestras fue de 3 (consulte la primera matriz de proximidad en la sección anterior). Vamos a representar esto en el dendrograma:
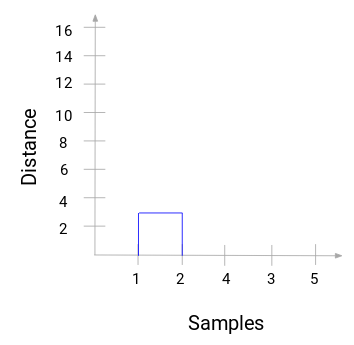
Aquí, podemos ver que hemos fusionado la muestra 1 y 2. La línea vertical representa la distancia entre estas muestras. Del mismo modo, trazamos todos los pasos en los que hemos fusionado los clusters y, finalmente, obtenemos un dendrograma como este:
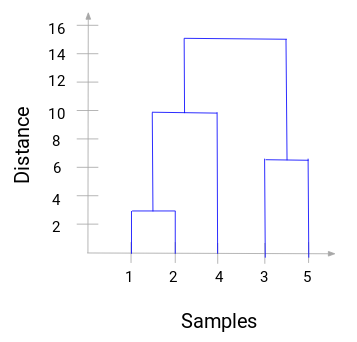
Podemos visualizar claramente los pasos de la agrupación jerárquica. Cuanto mayor sea la distancia de las líneas verticales en el dendrograma, mayor será la distancia entre esos clusters.
Ahora, podemos establecer una distancia de umbral y dibujar una línea horizontal (Generalmente, tratamos de establecer el umbral de tal manera que corte la línea vertical más alta). Establezcamos este umbral como 12 y dibujemos una línea horizontal:
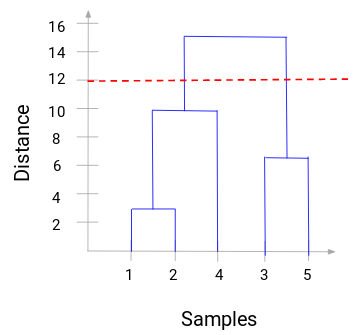
El número de clusters será el número de líneas verticales que están siendo intersecadas por la línea dibujada usando el umbral. En el ejemplo anterior, como la línea roja interseca 2 líneas verticales, tendremos 2 clusters. Un cluster tendrá una muestra (1,2,4) y el otro tendrá una muestra (3,5). Bastante sencillo, ¿verdad?
Así es como podemos decidir el número de clusters utilizando un dendrograma en Clustering Jerárquico. En la siguiente sección, implementaremos el clustering jerárquico que te ayudará a entender todos los conceptos que hemos aprendido en este artículo.
Resolución del problema de Segmentación de Clientes Mayoristas usando Clustering Jerárquico
¡Es hora de ensuciarnos las manos en Python!
Trabajaremos en un problema de segmentación de clientes mayoristas. Puedes descargar el conjunto de datos usando este enlace. Los datos están alojados en el repositorio de Machine Learning de la UCI. El objetivo de este problema es segmentar los clientes de un distribuidor mayorista en base a su gasto anual en diversas categorías de productos, como leche, comestibles, región, etc.
Exploremos primero los datos y luego apliquemos Clustering Jerárquico para segmentar los clientes.
Primero importaremos las librerías necesarias:
Carguemos los datos y observemos las primeras filas:
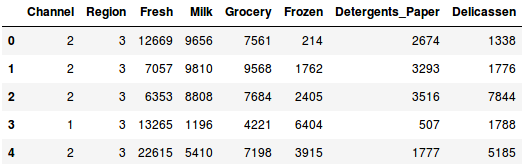
Hay múltiples categorías de productos – Frescos, Leche, Comestibles, etc. Los valores representan el número de unidades compradas por cada cliente para cada producto. Nuestro objetivo es hacer clusters a partir de estos datos que puedan segmentar juntos a clientes similares. Por supuesto, utilizaremos el Clustering Jerárquico para este problema.
Pero antes de aplicar el Clustering Jerárquico, tenemos que normalizar los datos para que la escala de cada variable sea la misma. ¿Por qué es esto importante? Bueno, si la escala de las variables no es la misma, el modelo podría estar sesgado hacia las variables con una magnitud más alta como Fresco o Leche (refiérase a la tabla anterior).
Entonces, primero normalicemos los datos y pongamos todas las variables a la misma escala:
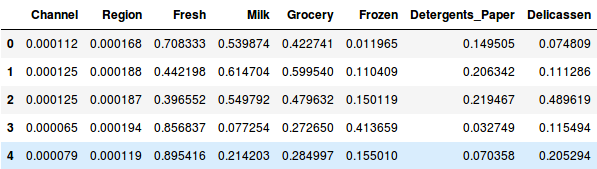
Aquí, podemos ver que la escala de todas las variables es casi similar. Ahora, ya estamos listos para empezar. Dibujemos primero el dendrograma para ayudarnos a decidir el número de clusters para este problema en particular:
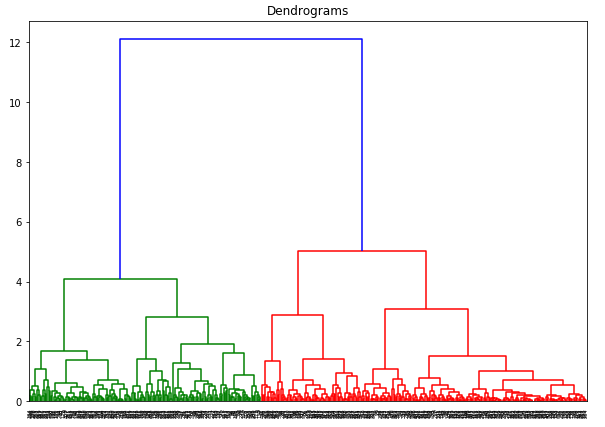
El eje x contiene las muestras y el eje y representa la distancia entre estas muestras. La línea vertical con la máxima distancia es la línea azul y, por tanto, podemos decidir un umbral de 6 y cortar el dendrograma:
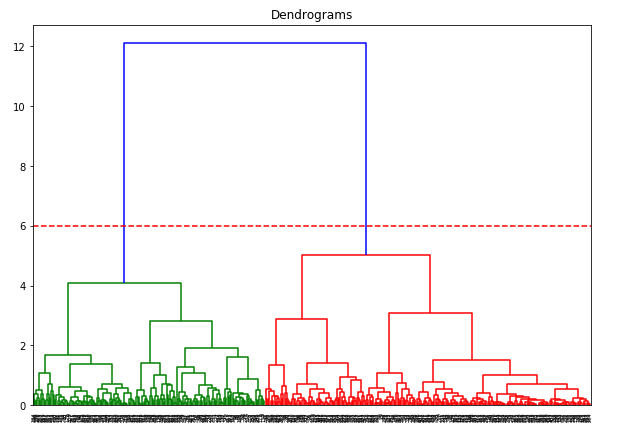
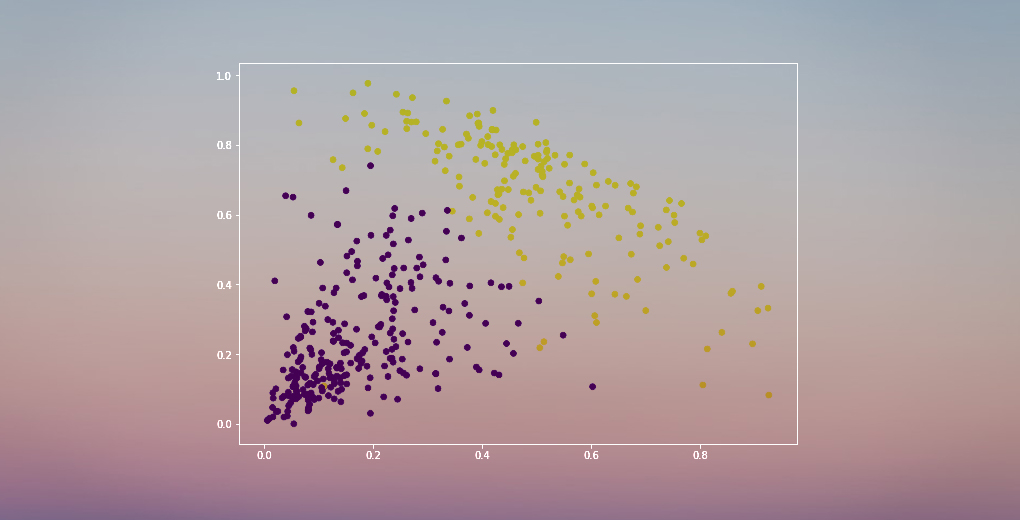
Tenemos dos clusters ya que esta línea corta el dendrograma en dos puntos. Apliquemos ahora el clustering jerárquico para 2 clusters:
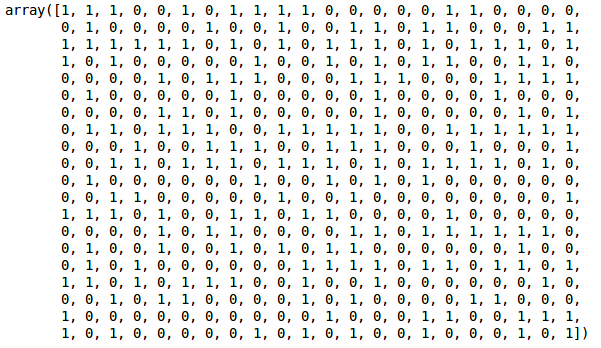
Podemos ver los valores de 0s y 1s en la salida ya que definimos 2 clusters. El 0 representa los puntos que pertenecen al primer cluster y el 1 representa los puntos del segundo cluster. Visualicemos ahora los dos clusters:
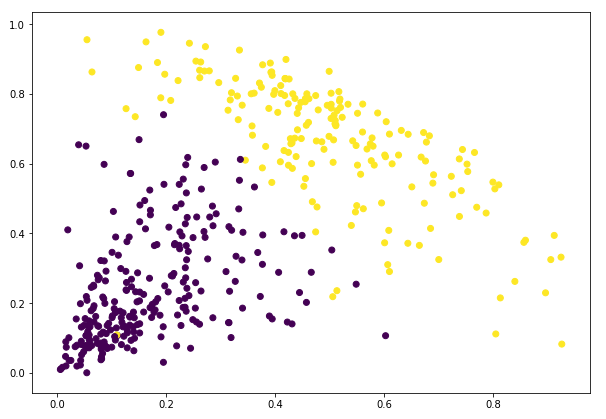
¡Impresionante! Aquí podemos visualizar claramente los dos clusters. Así es como podemos implementar el clustering jerárquico en Python.
Notas finales
El clustering jerárquico es una forma súper útil de segmentar las observaciones. La ventaja de no tener que predefinir el número de clusters le da bastante ventaja sobre k-Means.
Si todavía eres relativamente nuevo en la ciencia de los datos, te recomiendo encarecidamente que tomes el curso Applied Machine Learning. Es uno de los cursos de aprendizaje automático más completos que encontrará en cualquier lugar. El clustering jerárquico es sólo uno de los diversos temas que cubrimos en el curso.