Guías de Quantrium

Tesseract es un motor de reconocimiento óptico de caracteres que puede utilizarse en varios sistemas operativos. Es un software libre, publicado bajo la licencia Apache. Originalmente, Tesseract fue desarrollado por Hewlett-Packard como software propietario en la década de 1980, más tarde, fue liberado como un software de código abierto en 2005. A partir de 2006, su desarrollo fue patrocinado por Google. En esta guía, te llevaré a través de los pasos que he seguido con el fin de instalar Tesseract en mi máquina de Windows 10. También os mostraré cómo podéis utilizar tesseract fuera de la línea de comandos una vez que lo hayáis instalado con éxito.
Para instalar Tesseract 4 en nuestro sistema Windows, id al siguiente enlace:
Descargar el archivo ejecutable de Windows haciendo clic en el hipervínculo titulado tesseract-ocr-w64-setup-v4.1.0.20190314.exe. Aparecerá una notificación pidiéndole que guarde un archivo exe llamado «Tesseract-ocr-w64-setup-v4.1.0.20190314.exe». Guarde este archivo .exe donde tenga suficiente espacio de almacenamiento.
Abra este archivo exe. Si la ventana le pregunta «¿Desea permitir que este software realice cambios en su sistema?», haga clic en sí. Se le llevará a la sección de instalación.
Haga clic en siguiente, haga clic en Estoy de acuerdo con los términos y condiciones y después de seleccionar para quién y todo lo que desea instalar Tesseract (cualquier persona que utilice este ordenador/sólo para mí. Puede seleccionar cualquiera de las dos opciones), haga clic en siguiente.
Marque las casillas que dicen «ScrollView», «Herramientas de formación», «Creación de accesos directos» y, lo que es más importante, «Datos de idioma». Estas casillas deberían estar marcadas por defecto, pero hazlo en caso de que no estén marcadas en tu sistema.
Ahora, si quieres hacer predicciones en lenguas extranjeras como el japonés, el chino, el kurdo o lenguas indias como el hindi, el tamil, el bengalí, etc., marca también los «datos de escritura adicionales» y los «datos de lengua adicionales». Si quiere hacer predicciones sólo para el idioma inglés, no tiene que marcar esta opción.
Haga clic en Siguiente. Seleccione el directorio donde quiere instalar Tesseract. Por defecto a mí me aparece C:\Program Files\Tesseract-OCR y ahí es donde lo instalé. Puedes instalarlo según tu elección. Pero toma nota de la ruta donde instalaste Tesseract en tu máquina. Esto es importante.
Ahora puedes seleccionar la carpeta del menú de inicio en la que te gustaría crear el acceso directo del programa. Yo lo he creado en una carpeta llamada «Tesseract-OCR». Si lo quieres en una nueva carpeta, simplemente escribe el nombre de la carpeta en el espacio en blanco justo debajo del texto «Selecciona la carpeta del menú de inicio en la que quieres ….».
También puedes marcar la casilla «No crear accesos directos» en la parte inferior izquierda si no quieres crear ningún acceso directo. Una vez que haya seleccionado su opción preferida, haga clic en instalar. La instalación debería tardar unos minutos.
Una vez terminada la instalación, dirígete al directorio donde has instalado tu Tesseract. Queremos utilizar Tesseract desde nuestra línea de comandos de windows y para ello, tenemos que añadir Tesseract a nuestra ruta en la variable de entorno del sistema.
Para ello, haz clic en tu botón de inicio en windows y busca «variable de entorno». Verás un resultado llamado «Editar las variables de entorno del sistema». Haga clic en eso. Después de hacer clic en esto, usted debe estar en la sección «Avanzado» de «Propiedades del sistema» y un botón llamado «Variables de entorno ….» debe ser visible en la parte inferior derecha. Haga clic en ese botón.
Ahora, verá dos tablas aquí. Una llamada User variables for <username>. Aquí, el <username> es una variable que representa el nombre de usuario que utiliza el PC actualmente. La otra tabla llamada «Variables del sistema». En la tabla «Variables del sistema» haga clic en la variable llamada «Ruta» y luego haga clic en este botón llamado «Editar» justo encima del botón «Aceptar» como se muestra abajo en la captura de pantalla siguiente.
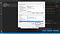
Una vez que haya terminado con esto, verá una página llamada «Editar variable de entorno». Aquí, en la parte superior derecha, verás un botón llamado «Nuevo». Haz clic en ese botón «Nuevo». Obtendrás un espacio en blanco donde puedes añadir algo de texto. Aquí, añade el nombre de tu directorio donde se almacenan todos tus archivos Tesseract-OCR.
Una vez que hayas introducido el nombre del directorio, pulsa «Enter» y comprueba si tu nombre de directorio se ha añadido a la «Tabla de variables de entorno». Una vez que lo haya hecho, haga clic en «Aceptar». Vuelve a hacer clic en «Aceptar» en la página «Variables de entorno». Vuelva a hacer clic en «Aceptar» en la página «Propiedades del sistema». Ahora debe haber salido de todas las opciones de configuración.
Abra el símbolo del sistema y escriba tesseract --version en el símbolo del sistema y pulse intro. Verá algo como esto:
Si ve algún error como tesseract command not found, lo más probable es que haya cometido algún error al seguir esta guía. Vuelve a ver en qué te has equivocado y trata de solucionarlo. Alternativamente, puede repetir todo el proceso de nuevo.
¡Genial! Ahora tienes Tesseract instalado en tu máquina. Usted puede comenzar a jugar con él y explorar más lejos.
Cómo utilizar Tesseract 4 utilizando la línea de comandos en una máquina de Windows
Primero, asegúrese de que tiene algún documento escrito a mano o algún documento mecanografiado en forma de una imagen. Digamos que tienes alguna foto en forma de png llamada handwritten_photo_1 en tu Escritorio y quieres probar Tesseract con ella. Abra su símbolo del sistema. Comenzará en este directorio:
C:\Users\username>
donde username es su nombre de usuario en ese sistema. Necesito ir al directorio del escritorio. Así que uso el siguiente comando:
C:\Users\username> cd Desktop
Ahora estoy en el directorio Desktop, donde se encuentra mi imagen. Usted puede ver lo que Tesseract predice el texto en el documento utilizando el siguiente comando:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseract emitirá directamente el texto en la propia línea de comandos. El parámetro -l se utiliza para especificar el idioma. Aquí lo hemos especificado como inglés, que es el caso por defecto de todos modos, por lo que usar -l eng era redundante en este caso. Si quieres usar algún otro idioma para el OCR, consulta este enlace que tiene todos los archivos .traineddata, que especifican el idioma:
Supongamos que tienes un documento de texto escrito en hindi. Entonces, vaya a este enlace, haga clic en el archivo titulado hin.traineddata y descárguelo. Una vez que lo hayas descargado, tienes que moverlo a la carpeta «tessdata», que estará dentro de tu directorio donde habías instalado originalmente tesseract. Una vez hecho esto, puede realizar el OCR de documentos hindúes utilizando el siguiente comando:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
En lugar de mostrar la salida del OCR en la propia línea de comandos, digamos que quiere que su salida del OCR se almacene en un archivo de texto. En ese caso, puede introducir el siguiente comando:
tesseract handwritten_photo_1.png output.txt
El texto de handwritten_photo_1.png se almacenará en un archivo de texto llamado output.txt que se ubicará en su directorio de trabajo actual, que en mi caso era Desktop.
Tesseract también puede tomar un archivo de texto como entrada, donde el texto necesita contener toda la ruta absoluta de las imágenes que desea procesar.
Esto es especialmente útil cuando, digamos que tiene dos imágenes escritas a mano en inglés llamadas handwritten_photo_1.png y handwritten_photo_2.png en el directorio C:\Program Files. Ahora, en su directorio de trabajo actual, tiene un archivo de texto llamado input.txt cuyo contenido es:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
En la primera y segunda línea respectivamente.
Ahora bien, si quiere almacenar el contenido de las dos fotos escritas a mano en un archivo de texto, sólo tiene que hacer lo siguiente:
tesseract input.txt output.txt -l eng
output.txttendrá el contenido OCR de ambas handwritten_photo_1.png y handwritten_photo_2.png, en ese orden. Aquí, usted debe notar que input.txt estaba en el directorio de trabajo actual. Puede utilizar tesseract en un archivo de texto que no esté en su directorio de trabajo actual incluyendo la ubicación del directorio como aquí:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt se encontrará de nuevo en el directorio de trabajo actual. También puede hacer esto para más de dos fotos. Tenga en cuenta que la predicción de una nueva foto en el archivo output.txt irá precedida de algún símbolo como:
Así que en este caso, Viral Calic es la predicción para la primera imagen, CY am the king of the world la predicción para la segunda imagen, Com and Serr la predicción para la tercera imagen y así sucesivamente. Puede comprobar la salida para todas sus imágenes de entrada y comprobar la precisión de las predicciones.
¡Eso es todo! Enhorabuena, ya está todo listo para utilizar Tesseract en su sistema Windows 10.