- 03/19/2020
- 4 minutos para leer
-
-
 d
d -
 D
D -
 a
a -
 v
v -
 d
d -
+6
-
El patrón Bulkhead es un tipo de diseño de aplicaciones tolerante a fallos. En una arquitectura bulkhead, los elementos de una aplicación se aíslan en conjuntos de manera que si uno falla, los demás seguirán funcionando. Recibe su nombre de las particiones seccionadas (mamparos) del casco de un barco. Si el casco de un barco se ve comprometido, sólo la sección dañada se llena de agua, lo que evita que el barco se hunda.
Contexto y problema
Una aplicación basada en la nube puede incluir múltiples servicios, y cada servicio tiene uno o más consumidores. Una carga excesiva o un fallo en un servicio afectará a todos los consumidores del servicio.
Además, un consumidor puede enviar peticiones a múltiples servicios simultáneamente, utilizando recursos para cada petición. Cuando el consumidor envía una solicitud a un servicio que está mal configurado o que no responde, los recursos utilizados por la solicitud del cliente pueden no ser liberados de manera oportuna. Como las peticiones al servicio continúan, esos recursos pueden agotarse. Por ejemplo, el pool de conexiones del cliente puede agotarse. En ese momento, las peticiones del consumidor a otros servicios se ven afectadas. Finalmente, el consumidor ya no puede enviar solicitudes a otros servicios, no sólo al servicio original que no responde.
El mismo problema de agotamiento de recursos afecta a los servicios con múltiples consumidores. Un gran número de peticiones originadas por un cliente puede agotar los recursos disponibles en el servicio. Otros consumidores ya no pueden consumir el servicio, provocando un efecto de fallo en cascada.
Solución
Participar las instancias del servicio en diferentes grupos, en función de la carga de consumidores y los requisitos de disponibilidad. Este diseño ayuda a aislar los fallos y permite mantener la funcionalidad del servicio para algunos consumidores, incluso durante un fallo.
Un consumidor también puede particionar los recursos, para asegurar que los recursos utilizados para llamar a un servicio no afectan a los recursos utilizados para llamar a otro servicio. Por ejemplo, a un consumidor que llama a múltiples servicios se le puede asignar un pool de conexiones para cada servicio. Si un servicio comienza a fallar, sólo afecta al pool de conexiones asignado para ese servicio, permitiendo al consumidor continuar utilizando los otros servicios.
Los beneficios de este patrón incluyen:
- Aísla a los consumidores y servicios de los fallos en cascada. Un problema que afecta a un consumidor o servicio puede ser aislado dentro de su propio mamparo, evitando que toda la solución falle.
- Permite preservar alguna funcionalidad en caso de fallo del servicio. Otros servicios y características de la aplicación seguirán funcionando.
- Le permite desplegar servicios que ofrecen una calidad de servicio diferente para las aplicaciones consumidoras. Un pool de consumidores de alta prioridad puede configurarse para utilizar servicios de alta prioridad.
El siguiente diagrama muestra mamparas estructuradas en torno a pools de conexión que llaman a servicios individuales. Si el Servicio A falla o causa algún otro problema, el pool de conexiones está aislado, por lo que sólo se ven afectadas las cargas de trabajo que utilizan el pool de hilos asignado al Servicio A. Las cargas de trabajo que utilizan el Servicio B y C no se ven afectadas y pueden continuar trabajando sin interrupción.
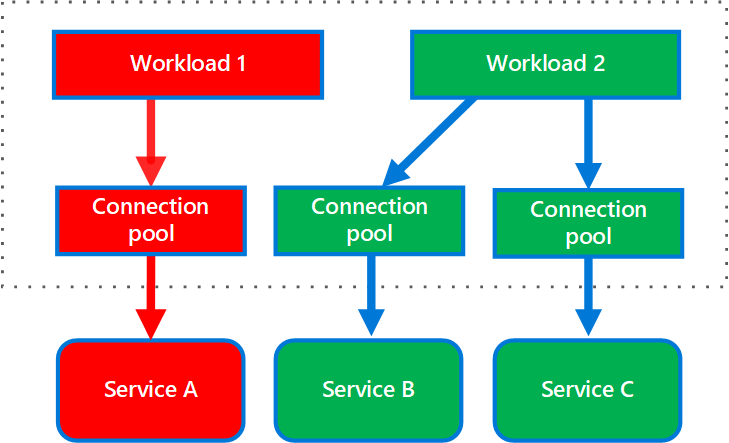
El siguiente diagrama muestra múltiples clientes llamando a un único servicio. Cada cliente tiene asignada una instancia de servicio distinta. El cliente 1 ha hecho demasiadas peticiones y ha saturado su instancia. Como cada instancia de servicio está aislada de las demás, los otros clientes pueden seguir haciendo llamadas.
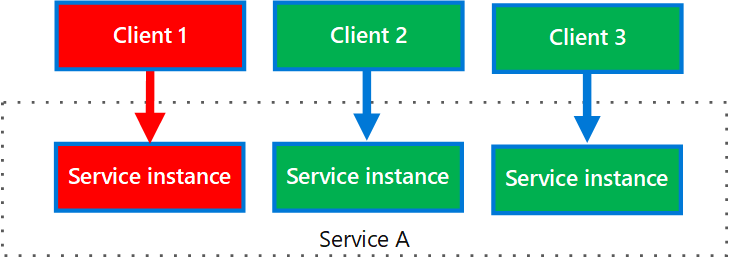
Cuestiones y consideraciones
- Defina las particiones en torno a los requisitos empresariales y técnicos de la aplicación.
- Cuando se dividan servicios o consumidores en mamparos, considere el nivel de aislamiento que ofrece la tecnología, así como la sobrecarga en términos de coste, rendimiento y capacidad de gestión.
- Considere la posibilidad de combinar mamparos con patrones de reintento, disyuntor y estrangulamiento para proporcionar una gestión de fallos más sofisticada.
- Cuando se dividan consumidores en mamparos, considere el uso de procesos, grupos de hilos y semáforos. Proyectos como resilience4j y Polly ofrecen un marco de trabajo para la creación de mamparas de consumidores.
- Cuando se dividan los servicios en mamparas, considere la posibilidad de desplegarlos en máquinas virtuales, contenedores o procesos separados. Los contenedores ofrecen un buen equilibrio de aislamiento de recursos con una sobrecarga bastante baja.
- Los servicios que se comunican utilizando mensajes asíncronos pueden aislarse a través de diferentes conjuntos de colas. Cada cola puede tener un conjunto dedicado de instancias que procesan los mensajes en la cola, o un único grupo de instancias que utilizan un algoritmo para poner en cola y despachar el procesamiento.
- Determine el nivel de granularidad para las colas. Por ejemplo, si desea distribuir a los inquilinos entre las particiones, podría colocar a cada inquilino en una partición separada, o poner a varios inquilinos en una sola partición.
- Supervise el rendimiento de cada partición y el SLA.
Cuándo utilizar este patrón
Utilizar este patrón para:
- Aislar los recursos utilizados para consumir un conjunto de servicios de backend, especialmente si la aplicación puede proporcionar algún nivel de funcionalidad incluso cuando uno de los servicios no está respondiendo.
- Aislar los consumidores críticos de los consumidores estándar.
- Proteger la aplicación de fallos en cascada.
Este patrón puede no ser adecuado cuando:
- Un uso menos eficiente de los recursos puede no ser aceptable en el proyecto.
- La complejidad añadida no es necesaria
Ejemplo
El siguiente archivo de configuración de Kubernetes crea un contenedor aislado para ejecutar un único servicio, con sus propios recursos y límites de CPU y memoria.