Introduktion
Det är en typ av övervakad inlärningsalgoritm som kan användas för både regressions- och klassificeringsproblem. Den fungerar för både kategoriska och kontinuerliga in- och utdatavariabler.
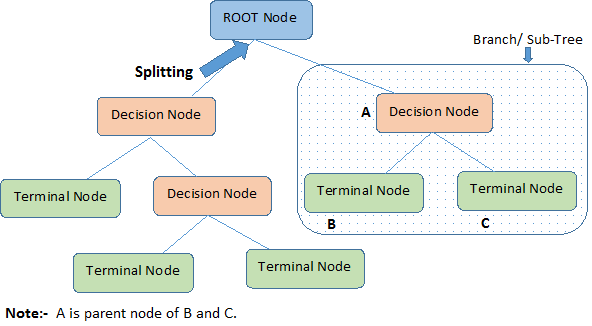
Låt oss identifiera viktiga terminologier om beslutsträd genom att titta på bilden ovan:
-
Root Node representerar hela populationen eller urvalet. Den delas vidare upp i två eller flera homogena uppsättningar.
-
Splitning är en process där en nod delas upp i två eller flera underknutar.
-
När en underknut delas upp i ytterligare underknutar kallas den för en beslutsknut.
-
Noder som inte delas upp kallas terminalnod eller blad.
-
När man tar bort undernoder till en beslutsnod kallas denna process för beskärning. Motsatsen till beskärning är Splitting.
-
En delsträcka av ett helt träd kallas Branch.
-
En nod, som är uppdelad i underknutar, kallas föräldraknut för underknutarna, medan underknutarna kallas för barn till föräldraknuten.
Typer av beslutsträd
Regressionsträd
Vi tar en titt på nedanstående bild som hjälper till att visualisera arten av den partitionering som utförs av ett regressionsträd. Den visar ett obearbetat träd och ett regressionsträd som anpassats till ett slumpmässigt dataset. Båda visualiseringarna visar en serie delningsregler med början i trädets topp. Lägg märke till att varje uppdelning av domänen är i linje med en av funktionsaxlarna. Konceptet med axelparallell uppdelning generaliseras direkt till dimensioner som är större än två. För ett egenskapsområde av storlek $p$, en delmängd av $\mathbb{R}^p$, delas utrymmet in i $M$-regioner, $R_{m}$, som var och en är ett $p$-dimensionellt ”hyperblock”.
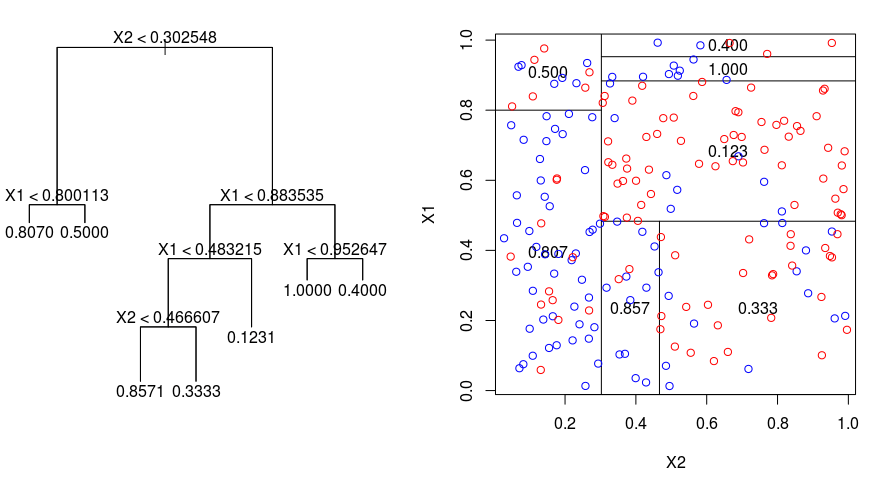
För att bygga upp ett regressionsträd använder man först rekursiv binär splitsning för att odla ett stort träd på träningsdatan, och stannar först när varje terminalknodd har färre än ett visst minsta antal observationer. Recursive Binary Splitting är en greedy- och top-down-algoritm som används för att minimera Residual Sum of Squares (RSS), ett felmått som också används i linjära regressionsinställningar. RSS, i fallet med ett partitionerat egenskapsutrymme med M partitioner, ges av:
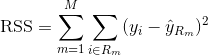
Med början i trädets topp delar man det i två grenar, vilket skapar en partition av två utrymmen. Du utför sedan denna särskilda uppdelning i trädets topp flera gånger och väljer den uppdelning av funktionerna som minimerar den (aktuella) RSS.
Nästan tillämpar du kostnadskomplexitetsbeskärning på det stora trädet för att få fram en sekvens av de bästa delträden, som funktion av $\alpha$. Den grundläggande idén här är att införa en ytterligare inställningsparameter, betecknad med $\alpha$, som balanserar trädets djup och dess passform för träningsdata.
Du kan använda K-fold korsvalidering för att välja $\alpha$. Denna teknik innebär helt enkelt att man delar upp träningsobservationerna i K folds för att uppskatta testfelsfrekvensen för delträden. Ditt mål är att välja det som leder till den lägsta felprocenten.
Klassificeringsträd
Ett klassificeringsträd är mycket likt ett regressionsträd, förutom att det används för att förutsäga ett kvalitativt svar i stället för ett kvantitativt.
Håll dig i minnet att för ett regressionsträd ges det förutsagda svaret för en observation av det genomsnittliga svaret för de träningsobservationer som hör till samma terminalknut. För ett klassificeringsträd förutsäger du däremot att varje observation tillhör den vanligaste förekommande klassen av träningsobservationer i den region som den tillhör.
När du tolkar resultaten av ett klassificeringsträd är du ofta intresserad inte bara av den klassförutsägelse som motsvarar en viss terminalnodregion, utan också av klassproportionerna bland de träningsobservationer som faller in i den regionen.
Uppgiften att odla ett klassificeringsträd liknar ganska mycket uppgiften att odla ett regressionsträd. Precis som i regressionsmiljön använder du rekursiv binär uppdelning för att odla ett klassificeringsträd. I klassificeringsinställningen kan dock inte residual Sum of Squares användas som ett kriterium för att göra de binära uppdelningarna. Istället kan du använda någon av dessa tre metoder nedan:
- Klassificeringsfelprocent: I stället för att se hur långt ett numeriskt svar är från medelvärdet, som i regressionsinställningen, kan du istället definiera ”träfffrekvensen” som den andel av träningsobservationerna i ett visst område som inte tillhör den mest förekommande klassen. Felet ges av denna ekvation:
E = 1 – argmaxc($\hat{\pi}_{mc}$)
där $\hat{\pi}_{mc}$ representerar fraktionen av träningsdata i region Rm som tillhör klass c.
- Gini-index: Gini-indexet är ett alternativt felmått som är utformat för att visa hur ”ren” en region är. Med ”renhet” menas i det här fallet hur mycket av träningsdata i en viss region som tillhör en enda klass. Om en region Rm innehåller data som mestadels tillhör en enda klass c kommer Gini-indexvärdet att vara litet:
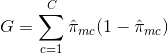
- Cross-Entropy: Ett tredje alternativ, som liknar Gini-indexet, kallas korsentropi eller avvikelse:
Korsentropin kommer att anta ett värde nära noll om $\hat{\pi}_{mc}$ är alla nära 0 eller nära 1. Liksom Gini-indexet kommer därför den korsvisa entropin att anta ett litet värde om den m:e noden är renodlad. Det visar sig faktiskt att Gini-indexet och korsentropin är ganska lika numeriskt.
När man bygger ett klassificeringsträd används vanligtvis antingen Gini-indexet eller korsentropin för att utvärdera kvaliteten på en viss uppdelning, eftersom de är mer känsliga för nodens renhet än vad klassificeringsfelprocenten är. Något av dessa tre tillvägagångssätt kan användas vid beskärning av trädet, men klassificeringsfelprocenten är att föredra om prediktionsnoggrannheten hos det slutliga beskurna trädet är målet.
Fördelar och nackdelar med beslutsträd
Den stora fördelen med att använda beslutsträd är att de intuitivt sett är mycket lätta att förklara. De speglar nära mänskligt beslutsfattande jämfört med andra regressions- och klassificeringsmetoder. De kan visas grafiskt och de kan enkelt hantera kvalitativa prediktorer utan att behöva skapa dummyvariabler.
Däremot har beslutsträd i allmänhet inte samma prediktiva noggrannhet som andra metoder, eftersom de inte är helt robusta. En liten förändring i data kan orsaka en stor förändring i det slutliga uppskattade trädet.
Då många beslutsträd aggregeras med hjälp av metoder som bagging, random forests och boosting kan beslutsträdens prediktiva prestanda förbättras avsevärt.
Trädbaserade metoder
Bagging
De beslutsträd som diskuterats ovan lider av hög varians, vilket innebär att om du delar upp träningsdata i två delar slumpmässigt, och anpassar ett beslutsträd till båda halvorna, kan resultaten som du får bli helt olika. Däremot kommer ett förfarande med låg varians att ge liknande resultat om det tillämpas upprepade gånger på olika dataset.
Bagging, eller bootstrap-aggregation, är en teknik som används för att minska variansen i dina förutsägelser genom att kombinera resultatet av flera klassificerare som modellerats på olika delprover av samma dataset. Här är ekvationen för bagging:
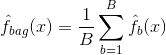
där du genererar $B$ olika bootstrappade träningsdatamängder. Du tränar sedan din metod på den $bth$ bootstrappade träningsuppsättningen för att få $\hat{f}_{b}(x)$, och slutligen genomsnittar du förutsägelserna.
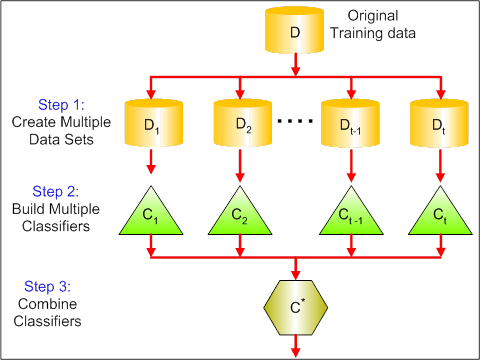
Den visuella bilden nedan visar de 3 olika stegen i bagging:
-
Steg 1: Här ersätter du originaldata med nya data. De nya uppgifterna har vanligtvis en bråkdel av de ursprungliga uppgifternas kolumner och rader, som sedan kan användas som hyperparametrar i baggingmodellen.
-
Steg 2: Du bygger klassificerare på varje dataset. I allmänhet kan du använda samma klassificerare för att göra modeller och förutsägelser.
-
Steg 3: Slutligen använder du ett medelvärde för att kombinera förutsägelserna från alla klassificerare, beroende på problemet. Generellt sett är dessa kombinerade värden mer robusta än en enskild modell.
Som bagging kan förbättra förutsägelserna för många regressions- och klassificeringsmetoder är det särskilt användbart för beslutsträd. För att tillämpa bagging på regressions-/klassificeringsträd konstruerar man helt enkelt $B$ regressions-/klassificeringsträd med hjälp av $B$ bootstrappade träningsuppsättningar och genomsnittar de resulterande förutsägelserna. Träden växer djupt och beskärs inte. Därför har varje enskilt träd hög varians, men låg bias. Genom att medelvärdesberäkna dessa $B$ träd minskar variansen.
Bredvid har bagging visat sig ge imponerande förbättringar av noggrannheten genom att kombinera hundratals eller till och med tusentals träd i ett enda förfarande.
Random Forests
Random Forests är en mångsidig metod för maskininlärning som kan utföra både regressions- och klassificeringsuppgifter. Den utför också dimensionella reduktionsmetoder, behandlar saknade värden, outlier-värden och andra viktiga steg i datautforskningen, och gör ett ganska bra jobb.
Random Forests ger en förbättring jämfört med bagged trees genom ett litet tweak som dekorrelerar träden. Precis som i bagging bygger du ett antal beslutsträd på bootstrappade träningsprov. Men när dessa beslutsträd byggs, varje gång en delning i ett träd övervägs, väljs ett slumpmässigt urval av m prediktorer som delningskandidater från den fullständiga uppsättningen av $p$ prediktorer. För delningen får endast en av dessa m$ prediktorer användas. Detta är den största skillnaden mellan slumpmässiga skogar och bagging; för precis som i bagging är valet av prediktor $m = p$.
För att odla en slumpmässig skog bör man:
-
Först anta att antalet fall i träningsuppsättningen är K. Ta sedan ett slumpmässigt urval av dessa K fall och använd sedan detta urval som träningsuppsättning för att odla trädet.
-
Om det finns $p$ ingångsvariabler ska du ange ett antal $m < p$ så att du vid varje nod kan välja $m$ slumpmässiga variabler av de $p$. Den bästa uppdelningen på dessa $m$ används för att dela upp noden.
-
Varje träd växer därefter i så stor utsträckning som möjligt och ingen beskärning behövs.
-
Slutligt aggregerar du förutsägelserna från målträden för att förutsäga nya data.
Random Forests är mycket effektiv när det gäller att skatta saknade data och bibehålla noggrannheten när en stor andel av data saknas. Den kan också balansera fel i dataset där klasserna är obalanserade. Viktigast av allt är att den kan hantera massiva datamängder med stor dimensionalitet. En nackdel med att använda Random Forests är dock att man lätt kan överanpassa bullriga dataset, särskilt när man gör regression.
Boosting
Boosting är ett annat tillvägagångssätt för att förbättra de förutsägelser som följer av ett beslutsträd. Liksom bagging och random forests är det ett allmänt tillvägagångssätt som kan tillämpas på många statistiska inlärningsmetoder för regression eller klassificering. Kom ihåg att bagging innebär att man skapar flera kopior av det ursprungliga träningsdatasetet med hjälp av bootstrap, anpassar ett separat beslutsträd till varje kopia och sedan kombinerar alla träd för att skapa en enda prediktiv modell. Varje träd byggs på ett bootstrappat dataset, oberoende av de andra träden.
Boosting fungerar på ett liknande sätt, förutom att träden odlas sekventiellt: varje träd odlas med hjälp av information från tidigare odlade träd. Boosting innebär inte bootstrap-sampling, utan varje träd anpassas på en modifierad version av den ursprungliga datamängden.
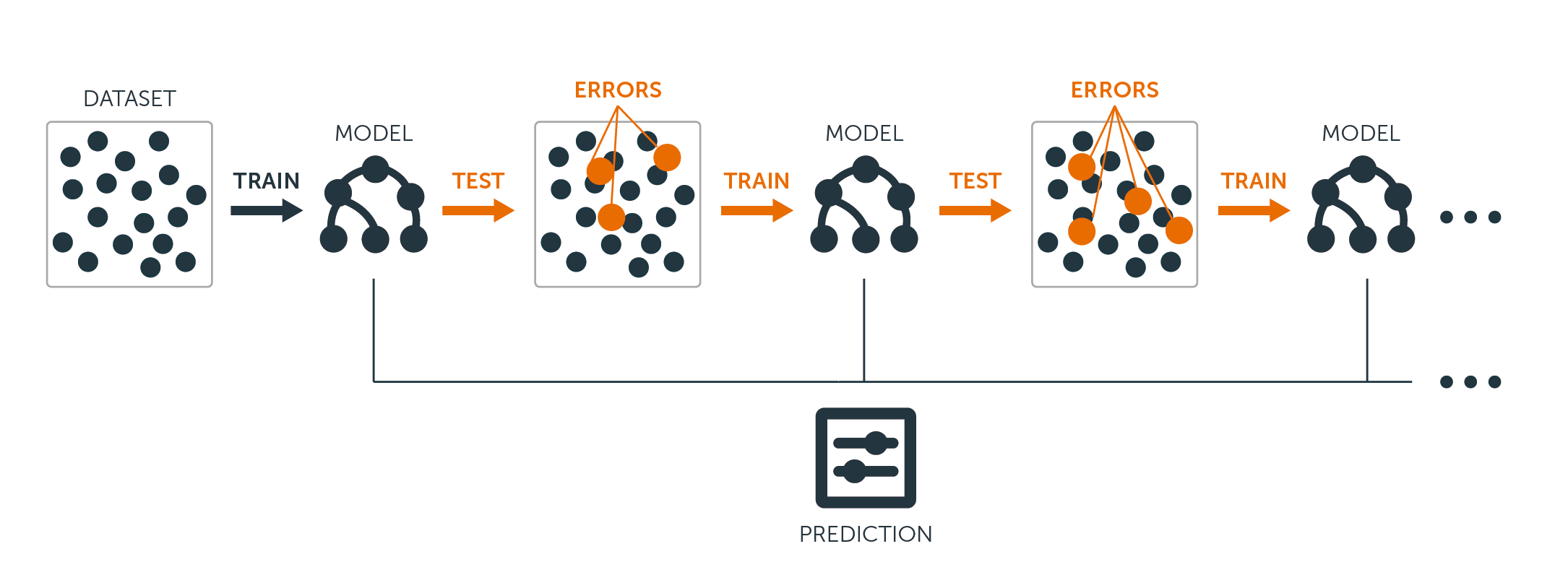
För både regressions- och klassificeringsträd fungerar boosting så här:
-
I motsats till att anpassa ett enda stort beslutsträd till data, vilket går ut på att anpassa data hårt och potentiellt överanpassa, så lär sig boosting-metoden i stället långsamt.
-
Givet den aktuella modellen anpassar du ett beslutsträd till residualerna från modellen. Det vill säga, du anpassar ett träd som använder de aktuella residualerna, snarare än resultatet $Y$, som svar.
-
Du lägger sedan till detta nya beslutsträd i den anpassade funktionen för att uppdatera residualerna. Vart och ett av dessa träd kan vara ganska litet, med bara ett fåtal terminala noder, som bestäms av parametern $d$ i algoritmen. Genom att anpassa små träd till residualerna förbättrar du långsamt $\hat{f}$ på områden där den inte presterar bra.
-
Krympningsparametern $\nu$ saktar ner processen ytterligare, vilket gör det möjligt för fler och olika formade träd att angripa residualerna.
Boosting är mycket användbart när du har mycket data och förväntar dig att beslutsträden ska vara mycket komplexa. Boosting har använts för att lösa många utmanande klassificerings- och regressionsproblem, bland annat riskanalys, sentimentsanalys, prediktiv reklam, prismodellering, försäljningsuppskattning och patientdiagnostik.
Decision Trees in R
Classification Trees
För den här delen arbetar du med datamängden Carseats med hjälp av tree-paketet i R. Tänk på att du först måste installera paketen ISLR och tree i din R Studio-miljö. Låt oss först ladda Carseats dataframe från ISLR-paketet.
library(ISLR)data(package="ISLR")carseats<-CarseatsLåt oss också ladda tree-paketet.
require(tree)Dataset Carseats är ett dataframe med 400 observationer på följande 11 variabler:
-
Verköp: Enhetsförsäljning i tusen
-
CompPrice: Pris som tas ut av konkurrenten på varje plats
-
Inkomst: Samhällets inkomstnivå i tusen dollar
-
Reklam:
-
Befolkning: regional befolkning i tusental
-
Pris: pris för bilbarnstolar på varje plats
-
ShelveLoc: Bad, Good eller Medium anger kvaliteten på hyllplatsen
-
Age: åldersnivå för befolkningen
-
Education: ed-nivå på platsen
-
Urban: Ja/Nej
-
US: Ja/Nej
names(carseats)Vi tar en titt på histogrammet över bilförsäljning:
hist(carseats$Sales)Observera att Sales är en kvantitativ variabel. Du vill demonstrera den med hjälp av träd med binärt svar. För att göra det omvandlar du Sales till en binär variabel som kallas High. Om försäljningen är mindre än 8 kommer den inte att vara hög. I annat fall kommer den att vara hög. Sedan kan du sätta den nya variabeln High tillbaka i dataframe.
High = ifelse(carseats$Sales<=8, "No", "Yes")carseats = data.frame(carseats, High)Nu ska vi fylla en modell med hjälp av beslutsträd. Naturligtvis kan du inte ha variabeln Sales här eftersom din svarsvariabel High skapades från Sales. Låt oss alltså utesluta den och anpassa trädet.
tree.carseats = tree(High~.-Sales, data=carseats)Låt oss se sammanfattningen av ditt klassificeringsträd:
summary(tree.carseats)Du kan se de variabler som är involverade, antalet terminala noder, den resterande medelavvikelsen samt felprocenten för felklassificering. För att göra det mer visuellt kan vi också plotta trädet och sedan kommentera det med den praktiska funktionen text:
plot(tree.carseats)text(tree.carseats, pretty = 0)Det finns så många variabler, vilket gör det mycket komplicerat att titta på trädet. Du kan åtminstone se att vid varje terminalnod är de märkta med Yes eller No. Vid varje delningsnod visas variablerna och värdet för delningsvalet (till exempel Price < 92.5 eller Advertising < 13.5).
För att få en detaljerad sammanfattning av trädet är det bara att skriva ut det. Den är praktisk om du vill ta fram detaljer ur trädet för andra ändamål:
tree.carseatsDet är dags att beskära trädet. Låt oss skapa en träningsuppsättning och en testuppsättning genom att dela upp carseats dataframe i 250 tränings- och 150 testprover. Först ställer du in ett frö för att göra resultaten reproducerbara. Sedan tar du ett slumpmässigt urval av ID-nummer (index) för proverna. Specifikt här gör du ett urval från uppsättningen 1 till n rad antal rader av bilsäten, vilket är 400. Du vill ha ett urval av storlek 250 (som standard används urvalet utan ersättning).
set.seed(101)train=sample(1:nrow(carseats), 250)Så nu får du detta index på train, som indexerar 250 av de 400 observationerna. Du kan återanpassa modellen med tree, genom att använda samma formel förutom att du talar om för trädet att använda en delmängd som är lika med train. Låt oss sedan göra en plott:
tree.carseats = tree(High~.-Sales, carseats, subset=train)plot(tree.carseats)text(tree.carseats, pretty=0)Plotten ser lite annorlunda ut på grund av den något annorlunda datamängden. Trots detta ser trädets komplexitet ungefär likadan ut.
Nu ska du ta detta träd och förutsäga det på testuppsättningen med hjälp av predict-metoden för träd. Här vill du faktiskt förutsäga class-etiketterna.
tree.pred = predict(tree.carseats, carseats, type="class")Därefter kan du utvärdera felet med hjälp av en felklassificeringstabell.
with(carseats, table(tree.pred, High))På diagonalerna finns de korrekta klassificeringarna, medan utanför diagonalerna finns de felaktiga. Du vill bara återköra de korrekta klassificeringarna. För att göra det kan du ta summan av de 2 diagonalerna dividerat med totalen (150 testobservationer).
(72 + 43) / 150Ok, du får ett fel på 0,76 med det här trädet.
När du odlar ett stort buskigt träd kan det ha för stor varians. Låt oss därför använda korsvalidering för att beskära trädet optimalt. Med hjälp av cv.tree använder du felklassificeringsfelet som grund för att göra beskärningen.
cv.carseats = cv.tree(tree.carseats, FUN = prune.misclass)cv.carseatsUtskrift av resultaten visar detaljerna i korsvalideringens väg. Du kan se storleken på träden när de beskars tillbaka, avvikelserna när beskärningen fortskred, samt den kostnadskomplexitetsparameter som användes i processen.
Låt oss plotta ut detta:
plot(cv.carseats)Om du tittar på plottet ser du en nedåtgående spiraldel på grund av felklassificeringsfelet på 250 korsvaliderade punkter. Så låt oss välja ett värde i de nedåtgående stegen (12). Låt oss sedan beskära trädet till en storlek på 12 för att identifiera det trädet. Låt oss slutligen plotta och kommentera trädet för att se resultatet.
prune.carseats = prune.misclass(tree.carseats, best = 12)plot(prune.carseats)text(prune.carseats, pretty=0)Det är lite ytligare än tidigare träd, och man kan faktiskt läsa etiketterna. Låt oss utvärdera det på testdatasetetet igen.
tree.pred = predict(prune.carseats, carseats, type="class")with(carseats, table(tree.pred, High))(74 + 39) / 150Det verkar som om de korrekta klassificeringarna minskade lite. Det har gjort ungefär samma sak som ditt ursprungliga träd, så beskärningen skadade inte mycket när det gäller felklassificeringsfel och gav ett enklare träd.
Ofta ger träd inte särskilt bra prediktionsfel, så låt oss gå vidare och ta en titt på random forests och boosting, som tenderar att överträffa träd när det gäller prediktion och felklassificering.
Random Forests
För den här delen kommer du att använda Boston housing data för att utforska random forests och boosting. Datasetet finns i paketet MASS. Den ger bostadsvärden och annan statistik i var och en av 506 förorter i Boston baserat på en folkräkning från 1970.
library(MASS)data(package="MASS")boston<-Bostondim(boston)names(boston)Låt oss också ladda paketet randomForest.
require(randomForest)För att förbereda data för slumpmässig skog, låt oss ställa in fröet och skapa en provträningsuppsättning med 300 observationer.
set.seed(101)train = sample(1:nrow(boston), 300)I den här datauppsättningen finns det 506 förorter i Boston. För varje förort finns variabler som brottslighet per capita, typer av industrier, genomsnittligt antal rum per bostad, genomsnittlig andel av husens ålder osv. Låt oss använda medv – medianvärdet av ägarboende bostäder för var och en av dessa förorter, som svarsvariabel.
Låt oss anpassa en slumpmässig skog och se hur väl den fungerar. Som sagt, du använder svaret medv, medianvärdet för bostäder (i 1 000 dollar) och träningsmallarna.
rf.boston = randomForest(medv~., data = boston, subset = train)rf.bostonUtskrift av den slumpmässiga skogen ger en sammanfattning: antalet träd (500 odlades), medelvärdet för kvadratiska residualer (MSR) och den procentuella andelen förklarad varians. MSR och % varians förklarad är baserade på out-of-bag-skattningarna, en mycket smart anordning i slumpskogar för att få ärliga felskattningar.
Den enda inställningsparametern i en slumpskog är argumentet som kallas mtry, vilket är antalet variabler som väljs ut vid varje delning av varje träd när du gör en delning. Som framgår här är mtry 4 av de 13 utforskande variablerna (exklusive medv) i Boston Housing-data – vilket innebär att varje gång trädet kommer att dela upp en nod, skulle 4 variabler väljas slumpmässigt, och sedan skulle uppdelningen begränsas till 1 av dessa 4 variabler. Det är så randomForests dekorrelerar träden.
Du kommer att anpassa en serie slumpmässiga skogar. Det finns 13 variabler, så låt mtry sträcka sig från 1 till 13:
-
För att registrera felen ställer du in 2 variabler
oob.errochtest.err. -
I en slinga av
mtryfrån 1 till 13 anpassar du förstrandomForestmed det värdet påmtrypå datasetettrain, och begränsar antalet träd till 350. -
Därefter extraherar du medelkvadratfelet på objektet (out-of-bag error).
-
Därefter förutsäger du på testdatasetet (
boston) med hjälp avfit(anpassningen avrandomForest). -
Sist beräknar du testfelet: medelkvadratiskt fel, som är lika med
mean( (medv - pred) ^ 2 ).
oob.err = double(13)test.err = double(13)for(mtry in 1:13){ fit = randomForest(medv~., data = boston, subset=train, mtry=mtry, ntree = 350) oob.err = fit$mse pred = predict(fit, boston) test.err = with(boston, mean( (medv-pred)^2 ))}Som synes har du precis odlat 4550 träd (13 gånger 350). Låt oss nu göra en plott med hjälp av kommandot matplot. Testfelet och felet utanför säcken binds ihop till en matris med två kolumner. Det finns några andra argument i matrisen, bland annat värdena för plottningstecknet (pch = 23 betyder fylld diamant), färger (röd och blå), typ är lika med båda (plottar båda punkterna och förbinder dem med linjerna) och namnet på y-axeln (Mean Squared Error). Du kan också sätta en legend i det övre högra hörnet av diagrammet.
matplot(1:mtry, cbind(test.err, oob.err), pch = 23, col = c("red", "blue"), type = "b", ylab="Mean Squared Error")legend("topright", legend = c("OOB", "Test"), pch = 23, col = c("red", "blue"))Idealt borde de här 2 kurvorna ligga i linje, men det verkar som om testfelet är lite lägre. Det finns dock en stor variabilitet i dessa uppskattningar av testfelet. Eftersom uppskattningen av felet utanför säcken beräknades på ett dataset och uppskattningen av testfelet beräknades på ett annat dataset, ligger dessa skillnader ganska väl inom standardfelen.
Märker du att den röda kurvan ligger jämnt ovanför den blå kurvan? Dessa feluppskattningar är mycket korrelerade, eftersom randomForest med mtry = 4 är mycket lik den med mtry = 5. Det är därför som var och en av kurvorna är ganska jämn. Vad du ser är att mtry runt 4 verkar vara det mest optimala valet, åtminstone för testfelet. Detta värde för mtry för felet utanför säcken är lika med 9.
Så med mycket få nivåer har du anpassat en mycket kraftfull prediktionsmodell med hjälp av slumpmässiga skogar. Hur kommer det sig? Den vänstra sidan visar prestandan för ett enda träd. Det genomsnittliga kvadratiska felet på out-of-bag är 26, och du har sjunkit ner till cirka 15 (strax över hälften). Detta innebär att du har minskat felet med hälften. På samma sätt för testfelet har du minskat felet från 20 till 12.
Boosting
Vid jämförelse med slumpmässiga skogar växer boosting mindre och stubbigare träd och går på bias. Du kommer att använda paketet GBM (Gradient Boosted Modeling), i R.
require(gbm)GBM frågar efter fördelningen, som är Gaussisk, eftersom du kommer att göra kvadrerade felförluster. Du kommer att be GBM om 10 000 träd, vilket låter som mycket, men det kommer att vara grunda träd. Interaktionsdjup är antalet delningar, så du vill ha 4 delningar i varje träd. Shrinkage är 0,01, vilket är hur mycket du kommer att krympa trädsteget tillbaka.
boost.boston = gbm(medv~., data = boston, distribution = "gaussian", n.trees = 10000, shrinkage = 0.01, interaction.depth = 4)summary(boost.boston)Funktionen summary ger en variabeltviktsdiagram. Det verkar som om det finns 2 variabler som har hög relativ betydelse: rm (antal rum) och lstat (andel personer med lägre ekonomisk status i samhället). Låt oss plotta dessa 2 variabler:
plot(boost.boston,i="lstat")plot(boost.boston,i="rm")Den första plotten visar att ju högre andel människor med lägre status i förorten, desto lägre värde på bostadspriserna. Den 2:a plotten visar det omvända förhållandet med antalet rum: det genomsnittliga antalet rum i huset ökar när priset ökar.
Det är dags att förutsäga en boostad modell på testdatasetetet. Låt oss titta på testprestanda som en funktion av antalet träd:
-
Först gör du ett rutnät av antalet träd i steg om 100 från 100 till 10 000.
-
Därefter kör du funktionen
predictpå den boostade modellen. Den tarn.treessom argument och producerar en matris med förutsägelser på testdata. -
Matrisens dimensioner är 206 testobservationer och 100 olika förutsägelsevektorer vid 100 olika värden på träd.
n.trees = seq(from = 100, to = 10000, by = 100)predmat = predict(boost.boston, newdata = boston, n.trees = n.trees)dim(predmat)
Det är dags att beräkna testfelet för var och en av förutsägelsevektorerna:
-
predmatär en matris,medvär en vektor, således är (predmat–medv) en matris av skillnader. Du kan använda funktionenapplytill kolumnerna för dessa kvadratiska skillnader (medelvärdet). Det skulle beräkna det kolumnvisa medelkvadratfelet för prediktionsvektorerna. -
Därefter gör du en plott med hjälp av liknande parametrar som den som används för Random Forest. Den skulle visa en plott för boosting error.
boost.err = with(boston, apply( (predmat - medv)^2, 2, mean) )plot(n.trees, boost.err, pch = 23, ylab = "Mean Squared Error", xlab = "# Trees", main = "Boosting Test Error")abline(h = min(test.err), col = "red")
Det boosting error sjunker ganska mycket när antalet träd ökar. Detta är ett bevis för att boosting är ovilligt att överanpassa. Låt oss också inkludera det bästa testfelet från randomForest i diagrammet. Boosting får faktiskt en rimlig mängd under testfelet för randomForest.
Slutsats
Så det är slutet på denna R-tutorial om att bygga beslutsträdsmodeller: klassificeringsträd, slumpmässiga skogar och boostade träd. De 2 sistnämnda är kraftfulla metoder som du kan använda när som helst efter behov. Enligt min erfarenhet brukar boosting överträffa RandomForest, men RandomForest är lättare att implementera. I RandomForest är den enda inställningsparametern antalet träd, medan det i boosting krävs fler inställningsparametrar förutom antalet träd, inklusive krympning och interaktionsdjup.
Om du vill lära dig mer ska du se till att ta en titt på vår kurs Machine Learning Toolbox för R.
.