Introduktion
Det är viktigt att förstå kundernas beteende i alla branscher. Jag insåg detta förra året när min marknadschef frågade mig – ”Kan du berätta för mig vilka befintliga kunder vi ska rikta in oss på för vår nya produkt?”
Det var en rejäl inlärningskurva för mig. Jag insåg snabbt som datavetare hur viktigt det är att segmentera kunderna så att min organisation kan skräddarsy och bygga riktade strategier. Här kom begreppet klusterindelning väl till pass!
Problem som segmentering av kunder är ofta bedrägligt knepiga eftersom vi inte arbetar med någon målvariabel i åtanke. Vi befinner oss officiellt i landet för oövervakad inlärning där vi måste ta reda på mönster och strukturer utan att ha ett bestämt resultat i åtanke. Det är både utmanande och spännande som datavetare.
Nu finns det några olika sätt att utföra klusterbildning (som du kommer att se nedan). Jag kommer att presentera en sådan typ i den här artikeln – hierarkisk klustring.
Vi kommer att lära oss vad hierarkisk klustring är, dess fördel jämfört med andra klusteralgoritmer, de olika typerna av hierarkisk klustring och stegen för att utföra den. Vi kommer slutligen att ta upp ett dataset för kundsegmentering och sedan genomföra hierarkisk klustring i Python. Jag älskar den här tekniken och jag är säker på att du också kommer att göra det efter den här artikeln!
Note: Som nämnts finns det flera sätt att utföra klusterbildning. Jag uppmuntrar dig att kolla in vår grymma guide om de olika typerna av klusterbildning:
- An Introduction to Clustering and different methods of clustering
För att lära dig mer om klustring och andra algoritmer för maskininlärning (både övervakade och oövervakade) kan du läsa följande omfattande program-
- Certified AI & ML Blackbelt+ Program
Innehållsförteckning
- Supervised vs Unsupervised Learning
- Why Hierarchical Clustering?
- Vad är hierarkisk klustring?
- Typer av hierarkisk klustring
- Agglomerativ hierarkisk klustring
- Divisiv hierarkisk klustring
- Steg för att utföra hierarkisk klustring
- Hur väljer man antalet kluster i hierarkisk klustring?
- Lösning av ett problem med segmentering av grossistkunder med hjälp av hierarkisk klustring
Supervised vs Unsupervised Learning
Det är viktigt att förstå skillnaden mellan supervised och unsupervised learningunsupervised learning innan vi dyker ner i hierarkisk klustring. Låt mig förklara skillnaden med hjälp av ett enkelt exempel.
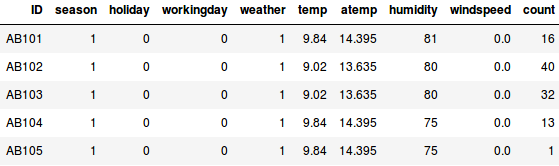
Säg att vi vill uppskatta antalet cyklar som kommer att hyras i en stad varje dag:
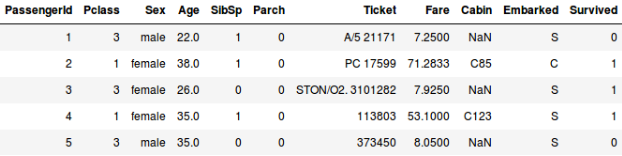
Och låt oss säga att vi vill förutsäga om en person ombord på Titanic överlevde eller inte:
Vi har ett fast mål att uppnå i båda dessa exempel:
- I det första exemplet måste vi förutsäga antalet cyklar baserat på egenskaper som säsong, semester, arbetsdag, väder, temperatur osv.
- I det andra exemplet ska vi förutsäga om en passagerare överlevde eller inte. I variabeln ”Överlevde” står 0 för att personen inte överlevde och 1 för att personen klarade sig levande. De oberoende variablerna här inkluderar Pclass, Sex, Age, Fare, etc.
Så, när vi får en målvariabel (count och Survival i de två ovanstående fallen) som vi måste förutsäga baserat på en given uppsättning prediktorer eller oberoende variabler (säsong, semester, Sex, Age, etc.), kallas sådana problem för problem med övervakad inlärning.
Låt oss titta på figuren nedan för att förstå detta visuellt:
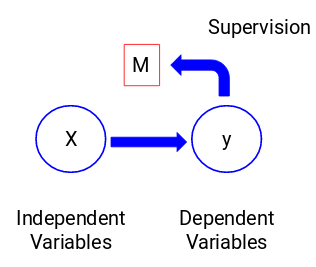
Här är y vår beroende eller målvariabel och X representerar de oberoende variablerna. Målvariabeln är beroende av X och kallas därför också för en beroende variabel. Vi tränar vår modell med hjälp av de oberoende variablerna i övervakningen av målvariabeln och därav namnet övervakad inlärning.
Vårt mål när vi tränar modellen är att generera en funktion som mappar de oberoende variablerna till det önskade målet. När modellen väl är tränad kan vi skicka nya uppsättningar observationer och modellen kommer att förutsäga målet för dem. Detta är i korthet övervakad inlärning.
Det kan finnas situationer då vi inte har någon målvariabel att förutsäga. Sådana problem, utan någon explicit målvariabel, kallas problem med oövervakad inlärning. Vi har bara de oberoende variablerna och ingen mål-/beroendevariabel i dessa problem.

Vi försöker dela in hela data i en uppsättning grupper i dessa fall. Dessa grupper kallas kluster och processen för att skapa dessa kluster kallas klustring.
Denna teknik används i allmänhet för att klustra en population i olika grupper. Några vanliga exempel är att segmentera kunder, klustra liknande dokument, rekommendera liknande låtar eller filmer osv.
Det finns många fler tillämpningar av oövervakad inlärning. Om du stöter på någon intressant tillämpning, dela gärna med dig av dem i kommentarsfältet nedan!
Nu finns det olika algoritmer som hjälper oss att göra dessa kluster. De vanligaste klusteralgoritmerna är K-means och hierarkisk klustring.
Varför hierarkisk klustring?
Vi bör först veta hur K-means fungerar innan vi dyker ner i hierarkisk klustring. Lita på mig, det kommer att göra begreppet hierarkisk klustring desto enklare.
Här kommer en kort översikt över hur K-means fungerar:
- Beslut antalet kluster (k)
- Välj k slumpmässiga punkter från datamaterialet som centroider
- Tilldela alla punkter till närmaste klustercentroid
- Beräkna centroid för nybildade kluster
- Upprepa steg 3 och 4
Det är en iterativ process. Den fortsätter att köras tills centroiderna för de nybildade klustren inte ändras eller tills det maximala antalet iterationer har uppnåtts.
Men det finns vissa utmaningar med K-means. Den försöker alltid skapa kluster av samma storlek. Dessutom måste vi bestämma antalet kluster i början av algoritmen. I idealfallet skulle vi inte veta hur många kluster vi ska ha i början av algoritmen och därför är det en utmaning med K-means.
Detta är en lucka som hierarkisk klusterbildning överbryggar med bravur. Den tar bort problemet med att behöva fördefiniera antalet kluster i förväg. Det låter som en dröm! Låt oss se vad hierarkisk klustring är och hur den förbättrar K-means.
Vad är hierarkisk klustring?
Säg att vi har nedanstående punkter och vill klustra dem i grupper:

Vi kan tilldela var och en av dessa punkter till ett separat kluster:

Nu kan vi, baserat på likheten mellan dessa kluster, kombinera de mest likartade klustren tillsammans och upprepa denna process tills endast ett enda kluster återstår:
Vi bygger i huvudsak en hierarki av kluster. Det är därför denna algoritm kallas hierarkisk klustring. Jag kommer att diskutera hur man bestämmer antalet kluster i ett senare avsnitt. För tillfället ska vi titta på de olika typerna av hierarkisk klustring.
Typer av hierarkisk klustring
Det finns huvudsakligen två typer av hierarkisk klustring:
- Agglomerativ hierarkisk klustring
- Dividuell hierarkisk klustring
Låts oss förstå varje typ i detalj.
Agglomerativ hierarkisk klustring
Vi tilldelar varje punkt till ett enskilt kluster i denna teknik. Anta att det finns fyra datapunkter. Vi tilldelar var och en av dessa punkter till ett kluster och får därmed 4 kluster i början:
Därefter, vid varje iteration, slår vi samman det närmaste paret av kluster och upprepar detta steg tills endast ett enda kluster återstår:
Vi slår samman (eller lägger till) kluster vid varje steg, eller hur? Därför kallas den här typen av klusterbildning också för additiv hierarkisk klusterbildning.
Divisiv hierarkisk klusterbildning
Divisiv hierarkisk klusterbildning fungerar på motsatt sätt. I stället för att börja med n kluster (vid n observationer) börjar vi med ett enda kluster och tilldelar alla punkter till det klustret.
Det spelar alltså ingen roll om vi har 10 eller 1000 datapunkter. Alla dessa punkter kommer att tillhöra samma kluster i början:
Nu, vid varje iteration, delar vi upp den längst bort belägna punkten i klustret och upprepar denna process tills varje kluster endast innehåller en enda punkt:
Vi delar upp (eller dividerar) klustren vid varje steg, därav namnet divisive hierarchical clustering.
Agglomerative Clustering används flitigt inom industrin och det kommer att vara fokus i den här artikeln. Divisive hierarchical clustering blir en barnlek när vi väl har koll på den agglomerativa typen.
Steg för att utföra hierarkisk klustring
Vi slår ihop de mest likartade punkterna eller klustren i hierarkisk klustring – det vet vi. Nu är frågan – hur bestämmer vi vilka punkter som är likartade och vilka som inte är det? Det är en av de viktigaste frågorna inom klusterbildning!
Här är ett sätt att beräkna likhet – Ta avståndet mellan centroiderna för dessa kluster. De punkter som har det minsta avståndet kallas liknande punkter och vi kan slå ihop dem. Vi kan också hänvisa till detta som en avståndsbaserad algoritm (eftersom vi beräknar avstånden mellan klustren).
I hierarkisk klustring har vi ett begrepp som kallas närhetsmatris. I denna lagras avstånden mellan varje punkt. Låt oss ta ett exempel för att förstå denna matris samt stegen för att utföra hierarkisk klustring.
Sätt upp exemplet

Antag att en lärare vill dela in sina elever i olika grupper. Hon har de poäng som varje elev fått i en uppgift och utifrån dessa poäng vill hon dela in dem i grupper. Det finns inget fast mål här för hur många grupper man ska ha. Eftersom läraren inte vet vilken typ av elever som ska delas in i vilken grupp kan detta inte lösas som ett övervakat inlärningsproblem. Så vi kommer att försöka tillämpa hierarkisk klustring här och segmentera eleverna i olika grupper.
Låt oss ta ett urval av 5 elever:
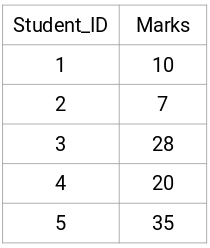
Skapa en närhetsmatris
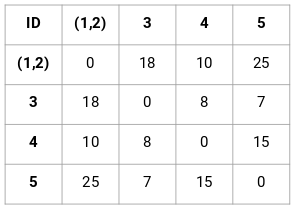
Först kommer vi att skapa en närhetsmatris som talar om avståndet mellan var och en av dessa punkter. Eftersom vi beräknar avståndet mellan varje punkt och var och en av de andra punkterna kommer vi att få en kvadratisk matris med formen n X n (där n är antalet observationer).
Låt oss skapa en närhetsmatris på 5 x 5 för vårt exempel:
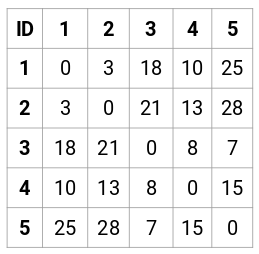
De diagonala delarna av denna matris kommer alltid att vara 0 eftersom avståndet mellan en punkt och sig själv alltid är 0. Vi kommer att använda formeln för euklidiskt avstånd för att beräkna resten av avstånden. Så låt oss säga att vi vill beräkna avståndet mellan punkt 1 och 2:
√(10-7)^2 = √9 = 3
På samma sätt kan vi beräkna alla avstånd och fylla närhetsmatrisen.
Steg för att utföra hierarkisk klustring
Steg 1: Först tilldelar vi alla punkter till ett enskilt kluster:
![]()
Olika färger här representerar olika kluster. Du kan se att vi har 5 olika kluster för de 5 punkterna i våra data.
Steg 2: Därefter tittar vi på det minsta avståndet i närhetsmatrisen och slår ihop punkterna med det minsta avståndet. Vi uppdaterar sedan närhetsmatrisen:
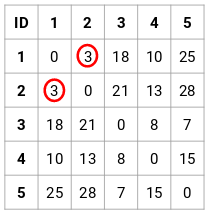
Här är det minsta avståndet 3 och därför slår vi ihop punkt 1 och 2:
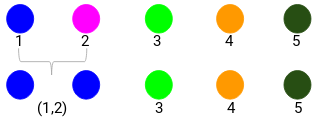
Vi tittar på de uppdaterade klustren och uppdaterar följaktligen närhetsmatrisen:
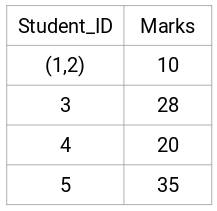
Här har vi tagit det största av de två märkena (7, 10) för att ersätta märkena för detta kluster. Istället för maximum kan vi också ta minimivärdet eller medelvärdena också. Nu beräknar vi återigen närhetsmatrisen för dessa kluster:
Steg 3: Vi upprepar steg 2 tills endast ett enda kluster återstår.
Så vi tittar först på det minsta avståndet i närhetsmatrisen och slår sedan ihop det närmaste klusterparet. Vi får de sammanslagna klustren enligt nedan efter att ha upprepat dessa steg:
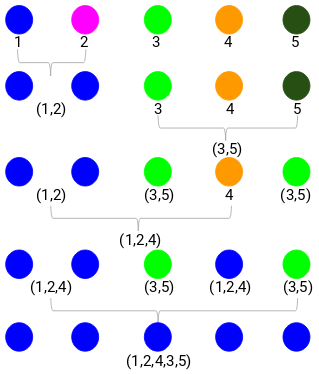
Vi började med 5 kluster och har slutligen ett enda kluster. Så här fungerar agglomerativ hierarkisk klustring. Men den brännande frågan kvarstår fortfarande – hur bestämmer vi antalet kluster? Låt oss förstå det i nästa avsnitt.
Hur ska vi välja antalet kluster i hierarkisk klustring?
Är du redo att äntligen besvara den här frågan som har hängt kvar sedan vi började lära oss? För att få fram antalet kluster för hierarkisk klustring använder vi oss av ett fantastiskt koncept som kallas dendrogram.
Ett dendrogram är ett trädliknande diagram som registrerar sekvenserna av sammanslagningar eller uppdelningar.
Låt oss återgå till vårt exempel lärare-elev. När vi slår ihop två kluster kommer ett dendrogram att registrera avståndet mellan dessa kluster och representera det i diagramform. Låt oss se hur ett dendrogram ser ut:
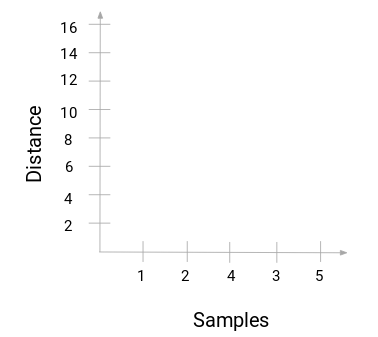
Vi har datamängdens prover på x-axeln och avståndet på y-axeln. När två kluster slås ihop kommer vi att sammanfoga dem i detta dendrogram och höjden på sammanfogningen kommer att vara avståndet mellan dessa punkter. Låt oss bygga upp dendrogrammet för vårt exempel:
Ta en stund för att bearbeta bilden ovan. Vi började med att slå samman prov 1 och 2 och avståndet mellan dessa två prov var 3 (se den första närhetsmatrisen i föregående avsnitt). Låt oss plotta detta i dendrogrammet:
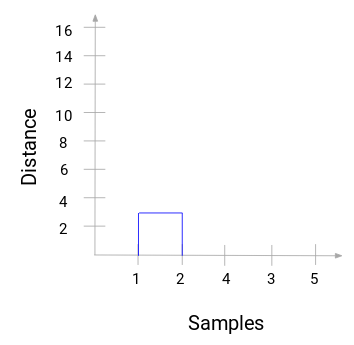
Här kan vi se att vi har slagit samman prov 1 och 2. Den vertikala linjen representerar avståndet mellan dessa prover. På samma sätt plottar vi alla steg där vi slagit ihop klustren och slutligen får vi ett dendrogram som detta:
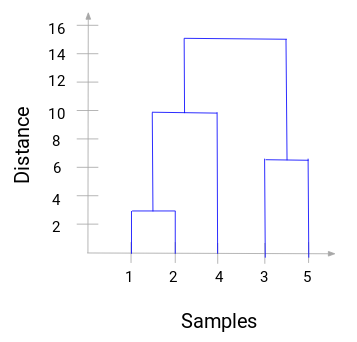
Vi kan tydligt visualisera stegen i den hierarkiska klusterbildningen. Ju större avståndet mellan de vertikala linjerna i dendrogrammet är, desto större är avståndet mellan dessa kluster.
Nu kan vi ställa in ett tröskelavstånd och rita en horisontell linje (i allmänhet försöker vi ställa in tröskeln så att den skär den högsta vertikala linjen). Låt oss sätta tröskelvärdet till 12 och rita en horisontell linje:
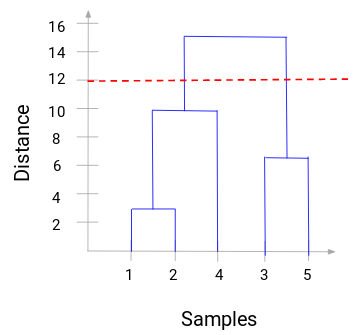
Antalet kluster kommer att vara antalet vertikala linjer som skärs av den linje som ritas med hjälp av tröskelvärdet. I exemplet ovan skär den röda linjen två vertikala linjer, vilket innebär att vi får två kluster. Ett kluster kommer att ha ett urval (1,2,4) och det andra kommer att ha ett urval (3,5). Ganska enkelt, eller hur?
Detta är hur vi kan bestämma antalet kluster med hjälp av ett dendrogram i hierarkisk klustring. I nästa avsnitt kommer vi att implementera hierarkisk klustring vilket kommer att hjälpa dig att förstå alla begrepp som vi har lärt oss i den här artikeln.
Lösning av problemet med segmentering av grossistkunder med hjälp av hierarkisk klustring
Det är dags att smutsa ner händerna i Python!
Vi kommer att arbeta med ett problem med segmentering av grossistkunder. Du kan ladda ner datasetet via den här länken. Datamaterialet finns på UCI Machine Learning repository. Syftet med detta problem är att segmentera kunderna hos en grossistdistributör baserat på deras årliga utgifter för olika produktkategorier, som mjölk, livsmedel, region etc.
Vi utforskar data först och tillämpar sedan hierarkisk klustring för att segmentera kunderna.
Vi kommer först att importera de nödvändiga biblioteken:
Lad in data och titta på de första raderna:
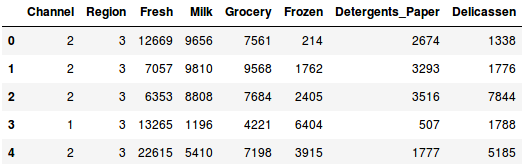
Det finns flera produktkategorier – färskvaror, mjölk, dagligvaror osv. Värdena representerar det antal enheter som köpts av varje kund för varje produkt. Vårt mål är att göra kluster av dessa data som kan segmentera liknande kunder tillsammans. Vi kommer naturligtvis att använda hierarkisk klustring för detta problem.
Men innan vi tillämpar hierarkisk klustring måste vi normalisera uppgifterna så att skalan för varje variabel är densamma. Varför är detta viktigt? Jo, om skalan för variablerna inte är densamma kan modellen bli snedvriden mot variablerna med en högre magnitud som Fresh eller Milk (se tabellen ovan).
Så, låt oss först normalisera data och föra alla variabler till samma skala:
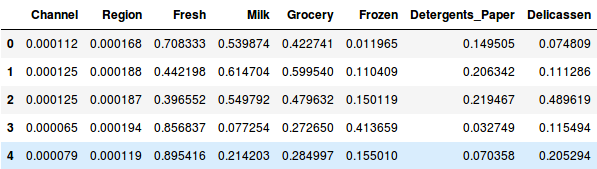
Här kan vi se att skalan för alla variablerna är nästan likartad. Nu är vi redo att gå vidare. Låt oss först rita dendrogrammet för att hjälpa oss att bestämma antalet kluster för just detta problem:
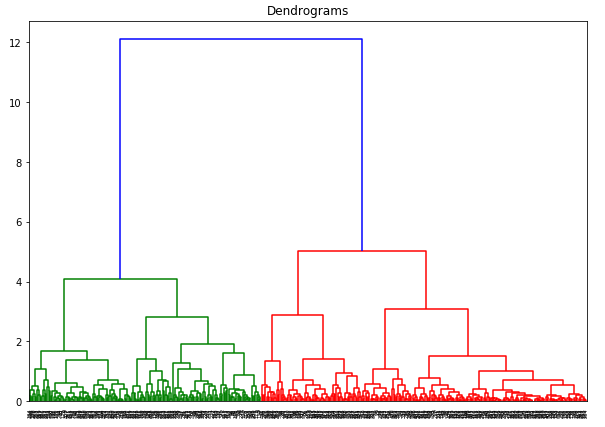
X-axeln innehåller proverna och y-axeln representerar avståndet mellan dessa prover. Den vertikala linjen med maximalt avstånd är den blå linjen och därför kan vi bestämma ett tröskelvärde på 6 och skära av dendrogrammet:
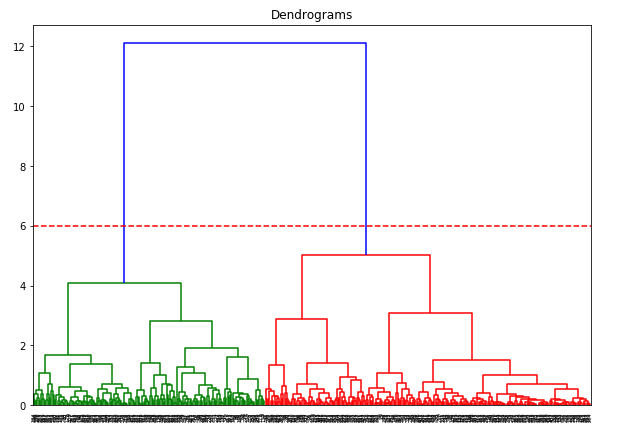
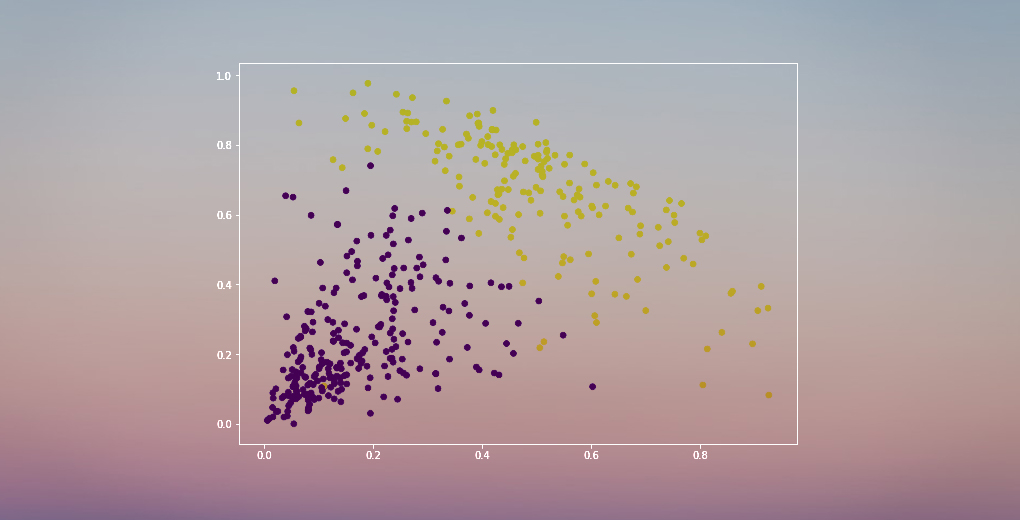
Vi har två kluster eftersom denna linje skär av dendrogrammet i två punkter. Låt oss nu tillämpa hierarkisk klustring för 2 kluster:
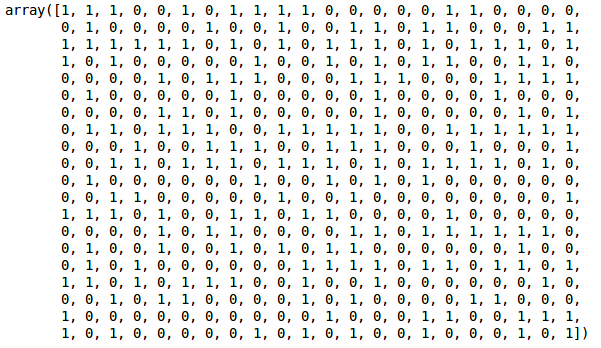
Vi kan se värdena 0s och 1s i resultatet eftersom vi definierat 2 kluster. 0 representerar de punkter som tillhör det första klustret och 1 representerar punkter i det andra klustret. Låt oss nu visualisera de två klustren:
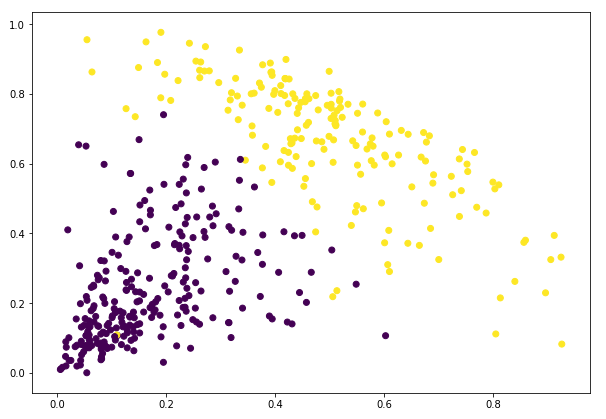
Awesome! Vi kan tydligt visualisera de två klustren här. Så här kan vi implementera hierarkisk klustring i Python.
Slutanteckningar
Hierarkisk klustring är ett superanvändbart sätt att segmentera observationer. Fördelen med att inte behöva fördefiniera antalet kluster i förväg ger det en fördel jämfört med k-Means.
Om du fortfarande är relativt ny inom datavetenskap rekommenderar jag starkt att du läser kursen Applied Machine Learning. Det är en av de mest omfattande kurserna i maskininlärning från början till slut som du kan hitta någonstans. Hierarkisk klusterbildning är bara ett av många olika ämnen som vi tar upp i kursen.