Quantrium Guides
>

Tesseract är en motor för optisk teckenigenkänning som kan användas på olika operativsystem. Det är en fri programvara som släpps under Apachelicensen. Ursprungligen utvecklades Tesseract av Hewlett-Packard som proprietär programvara på 1980-talet, senare släpptes den som öppen programvara 2005. Sedan 2006 sponsras utvecklingen av Google. I den här guiden kommer jag att ta dig igenom de steg som jag följde för att installera Tesseract på min Windows 10-maskin. Jag ska också visa hur du kan använda tesseract från kommandoraden när du väl har installerat det framgångsrikt.
För att installera Tesseract 4 på vårt Windows-system går du till följande länk:
Ladda ner den körbara filen för Windows genom att klicka på hyperlänken med titeln tesseract-ocr-w64-setup-v4.1.0.20190314.exe. Ett meddelande som ber dig att spara en exe-fil som heter ”Tesseract-ocr-w64-setup-v4.1.0.20190314.exe” kommer att visas. Spara denna .exe-fil där du har tillräckligt med lagringsutrymme.
Öppna denna exe-fil. Om det fönster frågar dig ”Vill du tillåta den här programvaran att göra ändringar i ditt system”, klicka på ja. Du kommer till installationsavsnittet.
Klicka på nästa, klicka på Jag godkänner villkoren och efter att ha valt för vem och för vad du vill installera Tesseract (vem som helst som använder den här datorn/enbart för mig. Du kan välja endera), klicka på nästa.
Kryssa i rutorna som säger ”ScrollView”, ”Training Tools”, ”Shortcuts creation” och viktigt ”Language data”. Dessa bör vara ikryssade som standard, men gör det bara ifall de inte är ikryssade i ditt system.
Nu, om du vill göra förutsägelser på främmande språk som japanska, kinesiska, kurdiska eller indiska språk som hindi, tamil, bengali etc., ska du också kryssa för ”additional script data” och ”additional language data”. Om du bara vill göra förutsägelser för det engelska språket behöver du inte kryssa för det här alternativet.
Klicka på Nästa. Välj den katalog där du vill installera Tesseract. Som standard visas C:\Program Files\Tesseract-OCR för mig och det var där jag installerade det. Du kan installera den enligt ditt val. Men notera den sökväg där du installerade Tesseract på din maskin. Detta är viktigt.
Nu kan du välja den mapp i startmenyn där du vill skapa programmets genväg. Jag skapade den i en mapp som heter ”Tesseract-OCR”. Om du vill ha den i en ny mapp skriver du bara namnet på mappen i det tomma utrymmet precis under texten ”Select the Start Menu folder in which you would want ….”.
Du kan också kryssa i rutan ”Do not create shortcuts” längst ner till vänster om du inte vill skapa några genvägar. När du är klar med att välja det alternativ du föredrar klickar du på Installera. Det bör ta några minuter innan installationen sker.
När installationen är klar går du till den katalog där du har installerat din Tesseract. Vi vill använda Tesseract från vår Windows-kommandorad och för att göra det måste vi lägga till Tesseract till vår sökväg i systemets miljövariabel.
För att göra det klickar du på din startknapp i Windows och söker efter ”environment variable”. Du kommer att se ett resultat som heter ”Redigera systemets miljövariabler”. Klicka på det. När du har klickat på detta bör du befinna dig i avsnittet ”Avancerat” i ”Systemegenskaper” och en knapp som heter ”Miljövariabler ….” bör vara synlig längst ner till höger. Klicka på den knappen.
Nu ser du två tabeller här. En som heter User variables for <username>. Här är <username> en variabel som står för det användarnamn som använder datorn för närvarande. Den andra tabellen heter ”Systemvariabler”. I tabellen ”Systemvariabler” klickar du på variabeln som heter ”Path” och klickar sedan på den här knappen som heter ”Edit” (redigera) precis ovanför ”OK”-knappen som visas i skärmdumpen nedan.
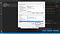
När du är klar med detta kommer du att se en sida som heter ”Redigera miljövariabel”. Här uppe till höger ser du en knapp som heter ”New” (ny). Klicka på den där knappen ”New”. Du kommer att få ett tomt utrymme där du kan lägga till lite text. Här lägger du till ditt katalognamn där alla dina Tesseract-OCR-filer lagras.
När du har skrivit in katalognamnet trycker du på ”Enter” och kontrollerar om ditt katalognamn har lagts till i ”Edit environment variable table”. När det har gjorts klickar du på ”OK”. Klicka på OK igen på sidan ”Environment Variables” (miljövariabler). Klicka på ”OK” på sidan ”Systemegenskaper” igen. Du måste ha avslutat alla inställningsalternativ nu.
Öppna kommandotolken och skriv tesseract --version i kommandotolken och tryck på enter. Du kommer att se något som liknar detta:
Om du ser ett fel som tesseract command not found, så har du troligen gjort något misstag när du följde denna guide. Gå tillbaka och se var du har gjort fel och försök att rätta till det. Alternativt kan du upprepa hela processen igen.
Great! Nu har du installerat Tesseract på din maskin. Du kan börja leka med det och utforska det vidare.
Hur man använder Tesseract 4 med hjälp av kommandoraden på en Windows-maskin
Först ska du se till att du har ett handskrivet dokument eller ett maskinskrivet dokument i form av en bild. Låt oss säga att du har någon bild i png-form som heter handwritten_photo_1 på ditt skrivbord och vill testa Tesseract med den. Öppna kommandotolken. Du börjar i den här katalogen:
C:\Users\username>
där username är ditt användarnamn på det systemet. Jag måste gå till skrivbordskatalogen. Så jag använder följande kommando:
C:\Users\username> cd Desktop
Nu är jag i skrivbordskatalogen, där min bild finns. Du kan se vad Tesseract förutspår för text i dokumentet genom att använda följande kommando:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseract ger ut texten direkt i själva kommandoraden. Parametern -l används för att ange språket. Här har vi angett det som engelska, vilket ändå är standard, så att använda -l eng var överflödigt i det här fallet. Om du vill använda något annat språk för OCR kan du kontrollera den här länken som innehåller alla .traineddata-filer som anger språket:
Säg att du har ett textdokument som är skrivet på hindi. Gå då till den här länken ovan, klicka på filen med titeln hin.traineddata och ladda ner den. När du har laddat ner den måste du flytta till mappen ”tessdata”, som kommer att finnas i den katalog där du ursprungligen hade installerat tesseract. När du har gjort det kan du utföra OCR av Hindi-dokument med hjälp av följande kommando:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
Istället för att visa OCR-utmatningen på själva kommandoraden, låt oss säga att du vill att din OCR-utmatning ska lagras i en textfil. I det fallet kan du i stället ange följande kommando:
tesseract handwritten_photo_1.png output.txt
Texten i handwritten_photo_1.png kommer att lagras i en textfil med namnet output.txt som kommer att ligga i din nuvarande arbetskatalog, vilket i mitt fall var Desktop.
Tesseract kan också ta en textfil som indata, där texten måste innehålla alla absoluta sökvägar till de bilder som du vill bearbeta.
Detta är särskilt användbart när, låt oss säga att du har två bilder handskrivna på engelska som heter handwritten_photo_1.png och handwritten_photo_2.png i katalogen C:\Program Files. I din nuvarande arbetskatalog har du nu en textfil som heter input.txt vars innehåll är:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
I den första respektive andra raden.
Om du nu vill lagra innehållet i de här två handskrivna bilderna i en textfil kan du bara göra följande:
tesseract input.txt output.txt -l eng
output.txt kommer att ha OCR-innehållet i både handwritten_photo_1.png och handwritten_photo_2.png, i den ordningen. Här bör du notera att input.txt fanns i den aktuella arbetskatalogen. Du kan använda tesseract på en textfil som inte heller finns i din nuvarande arbetskatalog genom att inkludera katalogplatsen som här:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt kommer återigen att finnas i den nuvarande arbetskatalogen. Du kan också göra detta för mer än två bilder. Observera att förutsägelsen för ett nytt foto i output.txt-filen kommer att föregås av någon symbol som t.ex:
Så i det här fallet är Viral Calic förutsägelsen för den första bilden, CY am the king of the world förutsägelsen för den andra bilden, Com and Serr förutsägelsen för den tredje bilden och så vidare. Du kan kontrollera resultatet för alla dina inmatade bilder och kontrollera förutsägelsernas noggrannhet.
Det var allt! Grattis, du är nu redo att använda Tesseract på ditt Windows 10-system.