Introduction
Az ügyfelek viselkedésének megértése minden iparágban kulcsfontosságú. Erre tavaly jöttem rá, amikor a marketingvezetőm megkérdezte tőlem – “Meg tudná mondani, hogy mely meglévő ügyfeleket célozzuk meg az új termékünkkel?”
Ez eléggé tanulságos volt számomra. Adattudósként gyorsan rájöttem, hogy mennyire fontos az ügyfelek szegmentálása, hogy a szervezetem testre szabhassa és célzott stratégiákat építhessen. Itt jött jól a klaszterezés fogalma!
A vevők szegmentálásához hasonló problémák gyakran megtévesztően trükkösek, mert nem egy célváltozóval a fejünkben dolgozunk. Hivatalosan is a felügyelet nélküli tanulás földjén vagyunk, ahol mintákat és struktúrákat kell kitalálnunk anélkül, hogy meghatározott eredményt tartanánk szem előtt. Ez adatkutatóként egyszerre kihívás és izgalmas.
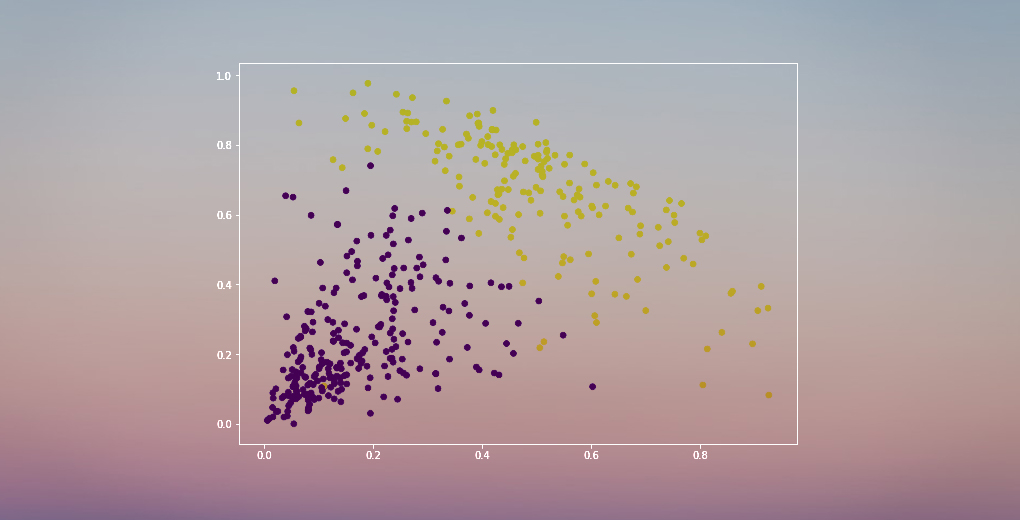
Most, a klaszterezésnek többféle módja is van (amint azt alább látni fogja). Ebben a cikkben egy ilyen típust fogok bemutatni – a hierarchikus klaszterezést.
Megtanuljuk, mi a hierarchikus klaszterezés, mi az előnye a többi klaszterező algoritmussal szemben, a hierarchikus klaszterezés különböző típusait és a végrehajtás lépéseit. Végül felveszünk egy ügyfélszegmentációs adathalmazt, majd implementáljuk a hierarchikus klaszterezést Pythonban. Imádom ezt a technikát, és biztos vagyok benne, hogy te is imádni fogod ezt a cikk után!
Megjegyzés: Mint említettük, a klaszterezésnek többféle módja van. Javaslom, hogy nézze meg a klaszterezés különböző típusairól szóló fantasztikus útmutatónkat:
- Egy bevezetés a klaszterezésbe és a klaszterezés különböző módszerei
Ha többet szeretne megtudni a klaszterezésről és más gépi tanulási algoritmusokról (felügyelt és nem felügyelt), nézze meg a következő átfogó programot.
- Certified AI & ML Blackbelt+ Program
Tartalomjegyzék
- Supervised vs Unsupervised Learning
- Miért hierarchikus klaszterezés?
- Mi a hierarchikus klaszterezés?
- A hierarchikus klaszterezés típusai
- Agglomeratív hierarchikus klaszterezés
- Divizatív hierarchikus klaszterezés
- A hierarchikus klaszterezés végrehajtásának lépései
- Hogyan válasszuk meg a klaszterek számát a hierarchikus klaszterezésben?
- Egy nagykereskedelmi ügyfélszegmentációs probléma megoldása hierarchikus klaszterezéssel
Supervised vs Unsupervised Learning
Nagyon fontos, hogy megértsük a különbséget a felügyelt és a felügyelet nélküli tanulássupervised learning között, mielőtt belemerülnénk a hierarchikus klaszterezésbe. Hadd magyarázzam el ezt a különbséget egy egyszerű példán keresztül.
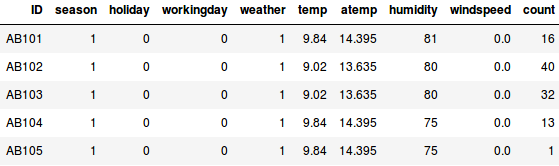
Tegyük fel, hogy meg akarjuk becsülni, hány kerékpárt bérelnek ki naponta egy városban:
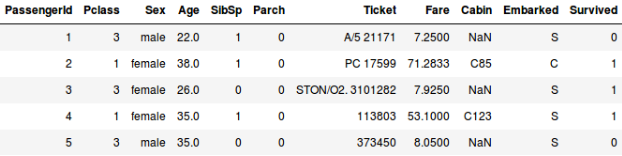
Vagy tegyük fel, hogy meg akarjuk jósolni, hogy egy személy a Titanic fedélzetén túlélte-e vagy sem:
Egy rögzített célt kell elérnünk mindkét példában:
- Az első példában a kerékpárok számát kell megjósolnunk olyan jellemzők alapján, mint az évszak, ünnepnap, munkanap, időjárás, hőmérséklet stb.
- A második példában azt jósoljuk meg, hogy egy utas túlélte-e vagy sem. A “Survived” változóban a 0 azt jelenti, hogy az illető nem élte túl, az 1 pedig azt, hogy az illető élve megúszta. A független változók itt a következők: Pclass, Sex, Age, Fare, stb.
Amikor tehát kapunk egy célváltozót (count és Survival a fenti két esetben), amelyet egy adott prediktor- vagy független változóhalmaz alapján kell megjósolnunk (season, holiday, Sex, Age, stb.), az ilyen problémákat felügyelt tanulási problémáknak nevezzük.
Nézzük meg az alábbi ábrát, hogy ezt vizuálisan is megértsük:
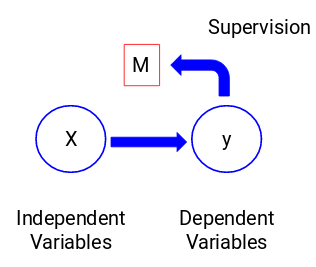
Itt y a függő vagy célváltozónk, X pedig a független változókat jelenti. A célváltozó X-től függ, ezért függő változónak is nevezzük. A modellünket a független változók segítségével képezzük a célváltozó felügyelete mellett, innen a felügyelt tanulás elnevezés.
A modell képzése során az a célunk, hogy olyan függvényt hozzunk létre, amely a független változókat a kívánt célváltozóra képezi le. Miután a modellt betanítottuk, átadhatunk új megfigyelési halmazokat, és a modell megjósolja a célváltozót ezekhez. Dióhéjban ez a felügyelt tanulás.
Létezhetnek olyan helyzetek, amikor nincs olyan célváltozó, amelyet megjósolhatnánk. Az ilyen, explicit célváltozó nélküli problémákat nevezzük felügyelet nélküli tanulási problémáknak. Ezekben a problémákban csak a független változókkal rendelkezünk, és nincs cél/függő változó.

Ezekben az esetekben megpróbáljuk a teljes adatot csoportokra osztani. Ezeket a csoportokat klasztereknek nevezzük, és a klaszterek létrehozásának folyamatát klaszterezésnek nevezzük.
Ezt a technikát általában egy populáció különböző csoportokra történő klaszterezésére használják. Néhány gyakori példa erre az ügyfelek szegmentálása, hasonló dokumentumok klaszterezése, hasonló dalok vagy filmek ajánlása stb.
A felügyelet nélküli tanulásnak még sok más alkalmazása is van. Ha bármilyen érdekes alkalmazással találkozik, ossza meg velünk az alábbi megjegyzések között!
Most, vannak különböző algoritmusok, amelyek segítenek nekünk a klaszterek létrehozásában. A leggyakrabban használt klaszterező algoritmusok a K-means és a hierarchikus klaszterezés.
Miért hierarchikus klaszterezés?
Először is tudnunk kell, hogyan működik a K-means, mielőtt belemerülnénk a hierarchikus klaszterezésbe. Higgye el, ez még könnyebbé teszi a hierarchikus klaszterezés fogalmát.
Itt egy rövid áttekintés arról, hogyan működik a K-means:
- Döntsük el a klaszterek számát (k)
- Válasszunk ki k véletlenszerű pontot az adatokból centroidként
- Az összes pontot rendeljük hozzá a klaszterekhez. legközelebbi klasztercentroidhoz
- Kalkulálja ki az újonnan kialakított klaszterek centroidját
- Ismételje meg a 3. és 4. lépést
Ez egy iteratív folyamat. Addig fut, amíg az újonnan kialakított klaszterek centroidjai nem változnak, vagy amíg az iterációk maximális számát el nem érjük.
A K-means módszerrel kapcsolatban azonban vannak bizonyos kihívások. Mindig azonos méretű klasztereket próbál létrehozni. Emellett az algoritmus elején el kell döntenünk a klaszterek számát. Ideális esetben nem tudnánk, hogy hány klaszterünk legyen, az algoritmus elején, és ezért ez egy kihívás a K-means-nél.
Ez egy hiányosság, amit a hierarchikus klaszterezés nagyszerűen áthidal. Megszünteti azt a problémát, hogy előre meg kell határozni a klaszterek számát. Úgy hangzik, mint egy álom! Lássuk tehát, mi is az a hierarchikus klaszterezés, és hogyan javítja a K-means-t.
Mi az a hierarchikus klaszterezés?
Tegyük fel, hogy vannak az alábbi pontok, és csoportosítani szeretnénk őket:

Mindegyik pontot külön klaszterbe sorolhatjuk:

Most e klaszterek hasonlósága alapján a leghasonlóbb klasztereket egyesíthetjük, és ezt a folyamatot addig ismételjük, amíg csak egyetlen klaszter marad:
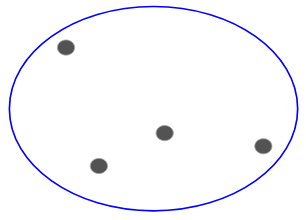
Lényegében egy klaszterhierarchiát építünk. Ezért nevezik ezt az algoritmust hierarchikus klaszterezésnek. A klaszterek számának eldöntését egy későbbi fejezetben fogom tárgyalni. Egyelőre nézzük meg a hierarchikus klaszterezés különböző típusait.
A hierarchikus klaszterezés típusai
A hierarchikus klaszterezésnek főként két típusa van:
- Agglomeratív hierarchikus klaszterezés
- Divizatív hierarchikus klaszterezés
Magyarázzuk el részletesen az egyes típusokat.
Agglomeratív hierarchikus klaszterezés
Ebben a technikában minden egyes pontot egy-egy klaszterhez rendelünk. Tegyük fel, hogy 4 adatpont van. Mindegyik pontot hozzárendeljük egy-egy klaszterhez, és így kezdetben 4 klaszterünk lesz:
Majd minden iterációnál összevonjuk a legközelebbi klaszterpárt, és ezt a lépést addig ismételjük, amíg csak egyetlen klaszter marad:
Minden lépésnél összevonjuk (vagy hozzáadjuk) a klasztereket, igaz? Ezért ezt a fajta klaszterezést additív hierarchikus klaszterezésnek is nevezik.
Divizív hierarchikus klaszterezés
A divizív hierarchikus klaszterezés ezzel ellentétesen működik. Ahelyett, hogy n klaszterrel kezdenénk (n megfigyelés esetén), egyetlen klaszterrel kezdünk, és az összes pontot ehhez a klaszterhez rendeljük.
Ezért nem számít, hogy 10 vagy 1000 adatpontunk van. Ezek a pontok mind ugyanabba a klaszterbe fognak tartozni az elején:
Most minden iterációnál felosztjuk a klaszter legtávolabbi pontját, és ezt a folyamatot addig ismételjük, amíg minden klaszter csak egyetlen pontot tartalmaz:
Minden lépésnél felosztjuk (vagy felosztjuk) a klasztereket, innen a felosztó hierarchikus klaszterezés elnevezés.
Az iparágban széles körben használják az agglomeratív klaszterezést, és ebben a cikkben ez lesz a középpontban. Az osztó hierarchikus klaszterezés gyerekjáték lesz, ha már ismerjük az agglomeratív típust.
A hierarchikus klaszterezés végrehajtásának lépései
A hierarchikus klaszterezés során a leghasonlóbb pontokat vagy klasztereket egyesítjük – ezt tudjuk. Most az a kérdés – hogyan döntjük el, hogy mely pontok hasonlóak és melyek nem? Ez az egyik legfontosabb kérdés a klaszterezésben!
Itt az egyik módja a hasonlóság kiszámításának – Vegyük a klaszterek középpontjai közötti távolságot. A legkisebb távolsággal rendelkező pontokat nevezzük hasonló pontoknak, és összevonhatjuk őket. Ezt nevezhetjük távolságalapú algoritmusnak is (mivel a klaszterek közötti távolságokat számoljuk).
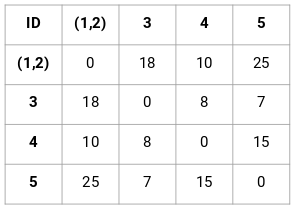
A hierarchikus klaszterezésben van egy fogalom, amit közelségmátrixnak nevezünk. Ez tárolja az egyes pontok közötti távolságokat. Vegyünk egy példát, hogy megértsük ezt a mátrixot, valamint a hierarchikus klaszterezés végrehajtásának lépéseit.
A példa felállítása

Tegyük fel, hogy egy tanár különböző csoportokba akarja osztani a diákjait. Rendelkezik az egyes tanulók által egy feladatban elért pontszámokkal, és ezek alapján szeretné csoportokra osztani őket. Itt nincs fix cél, hogy hány csoportot kell létrehozni. Mivel a tanár nem tudja, hogy milyen típusú diákokat melyik csoportba kell beosztani, ez nem oldható meg felügyelt tanulási problémaként. Ezért itt megpróbáljuk alkalmazni a hierarchikus klaszterezést, és különböző csoportokba szegmentálni a diákokat.
Vegyünk egy 5 diákból álló mintát:
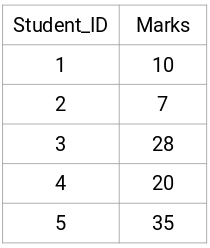
Közelségmátrix létrehozása
Először is létrehozunk egy közelségmátrixot, amely megadja az egyes pontok közötti távolságot. Mivel minden egyes pontnak a többi ponttól való távolságát számítjuk ki, egy n X n alakú négyzetmátrixot kapunk (ahol n a megfigyelések száma).
Készítsük el példánkhoz az 5 x 5 közelségmátrixot:
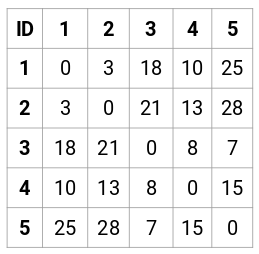
A mátrix átlós elemei mindig 0 lesznek, mivel egy pont önmagától való távolsága mindig 0 lesz. A többi távolság kiszámításához az euklideszi távolság képletét fogjuk használni. Tegyük fel tehát, hogy az 1 és 2 pont közötti távolságot akarjuk kiszámítani:
√(10-7)^2 = √9 = 3
Hasonlóképpen kiszámíthatjuk az összes távolságot és kitölthetjük a közelségmátrixot.
Lépések a hierarchikus klaszterezés elvégzéséhez
1. lépés: Először minden pontot egy-egy klaszterhez rendelünk:
![]()
A különböző színek itt különböző klasztereket jelölnek. Láthatjuk, hogy adataink 5 pontjához 5 különböző klaszter tartozik.
2. lépés: Ezután megnézzük a legkisebb távolságot a közelségmátrixban, és a legkisebb távolsággal rendelkező pontokat egyesítjük. Ezután frissítjük a közelségmátrixot:
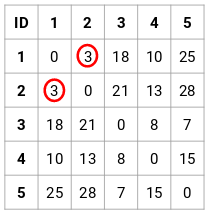
Itt a legkisebb távolság 3, ezért az 1. és 2. pontot egyesítjük:
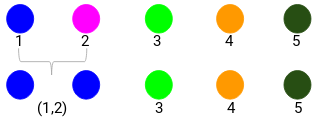
Nézzük meg a frissített klasztereket, és ennek megfelelően frissítjük a közelségmátrixot:
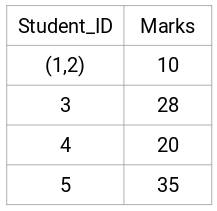
Itt a két jel (7, 10) maximumát vettük a klaszterhez tartozó jelek helyett. A maximum helyett vehetjük a minimumértéket vagy az átlagértékeket is. Most ismét kiszámítjuk ezeknek a klasztereknek a közelségmátrixát:
3. lépés: Addig ismételjük a 2. lépést, amíg csak egyetlen klaszter nem marad.
Ezért először a minimális távolságot nézzük meg a közelségmátrixban, majd a legközelebbi klaszterpárt egyesítjük. A lépések megismétlése után az alábbiakban látható módon kapjuk meg az egyesített klasztereket:
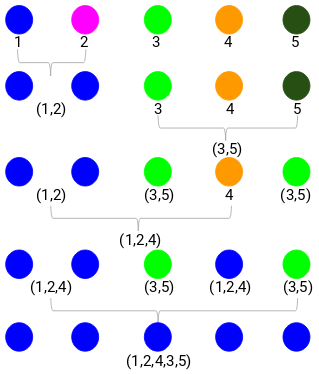
Öt klaszterrel kezdtük, és végül egyetlen klaszterünk maradt. Így működik az agglomeratív hierarchikus klaszterezés. De az égető kérdés még mindig fennáll – hogyan döntjük el a klaszterek számát? Értsük meg ezt a következő részben.
Hogyan válasszuk ki a klaszterek számát a hierarchikus klaszterezésben?
Készen állunk arra, hogy végre megválaszoljuk ezt a kérdést, amely a tanulás kezdete óta lóg a fejünkben? A klaszterek számának meghatározásához a hierarchikus klaszterezéshez egy fantasztikus fogalmat használunk, amelyet dendrogramnak nevezünk.
A dendrogram egy fa-szerű diagram, amely az egyesülések vagy szétválások sorrendjét rögzíti.
Visszatérjünk vissza a tanár-diák példánkhoz. Amikor két klasztert egyesítünk, egy dendrogram rögzíti a klaszterek közötti távolságot, és grafikon formájában ábrázolja azt. Lássuk, hogyan néz ki egy dendrogram:
Az x tengelyen az adathalmaz mintái, az y tengelyen pedig a távolság látható. Amikor két klasztert összevonunk, ebben a dendrogramban összekötjük őket, és az összekötés magassága a pontok közötti távolság lesz. Készítsük el a dendrogramot a példánkhoz:
Várjunk egy pillanatot a fenti kép feldolgozásával. Az 1. és 2. minta összevonásával kezdtük, és a két minta közötti távolság 3 volt (lásd az első közelségmátrixot az előző szakaszban). Ábrázoljuk ezt a dendrogramban:
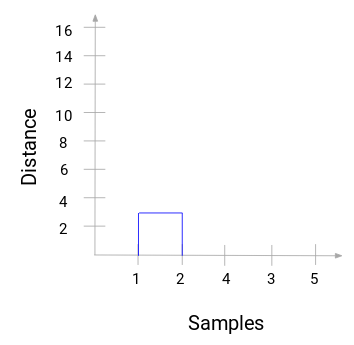
Itt láthatjuk, hogy az 1-es és a 2-es mintát összevontuk. A függőleges vonal e minták közötti távolságot jelöli. Hasonlóképpen ábrázoljuk az összes lépést, ahol egyesítettük a klasztereket, és végül egy ilyen dendrogramot kapunk:
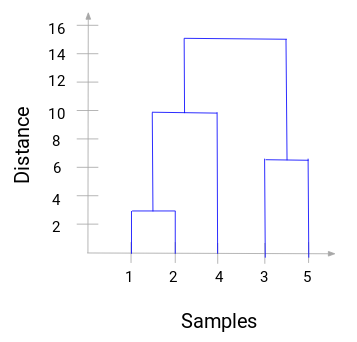
A hierarchikus klaszterezés lépéseit jól láthatóvá tehetjük. Minél nagyobb a függőleges vonalak távolsága a dendrogramban, annál nagyobb a távolság e klaszterek között.
Most beállíthatunk egy küszöbtávolságot, és rajzolhatunk egy vízszintes vonalat (általában úgy próbáljuk beállítani a küszöböt, hogy a legmagasabb függőleges vonalat vágja el). Állítsuk be ezt a küszöbértéket 12-nek, és rajzoljunk egy vízszintes vonalat:
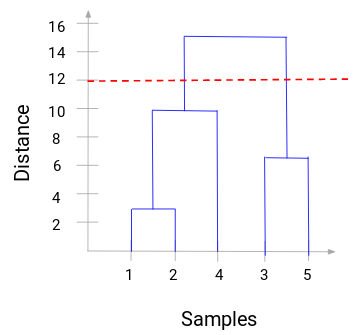
A klaszterek száma azoknak a függőleges vonalaknak a száma lesz, amelyeket a küszöbértékkel rajzolt vonal metsz. A fenti példában, mivel a piros vonal 2 függőleges vonalat metsz, 2 klaszterünk lesz. Az egyik klaszter mintája (1,2,4), a másiké pedig (3,5) lesz. Elég egyszerű, nem?
Így dönthetjük el a klaszterek számát a hierarchikus klaszterezés dendrogramjának segítségével. A következő részben megvalósítjuk a hierarchikus klaszterezést, ami segít megérteni az összes fogalmat, amit ebben a cikkben tanultunk.
A nagykereskedelmi ügyfelek szegmentálási problémájának megoldása hierarchikus klaszterezéssel
Ideje, hogy bepiszkítsuk a kezünket Pythonban!
Egy nagykereskedelmi ügyfelek szegmentálási problémán fogunk dolgozni. Az adatkészletet letöltheti ezen a linken. Az adatokat az UCI Machine Learning repositoryban tároljuk. A probléma célja, hogy szegmentáljuk egy nagykereskedelmi forgalmazó ügyfeleit az alapján, hogy évente mennyit költenek különböző termékkategóriákra, például tejre, élelmiszerre, régióra stb.
Először vizsgáljuk meg az adatokat, majd alkalmazzuk a hierarchikus klaszterezést az ügyfelek szegmentálására.
Először importáljuk a szükséges könyvtárakat:
Töltsük be az adatokat, és nézzük meg az első néhány sort:
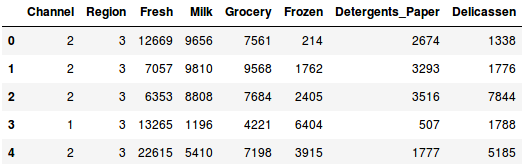
Több termékkategória van – friss, tej, élelmiszerbolt stb. Az értékek az egyes termékek esetében az egyes ügyfelek által vásárolt egységek számát jelentik. Célunk, hogy ezekből az adatokból olyan klasztereket hozzunk létre, amelyekkel a hasonló ügyfelek együttesen szegmentálhatók. Ehhez a feladathoz természetesen hierarchikus klaszterezést fogunk használni.
A hierarchikus klaszterezés alkalmazása előtt azonban normalizálnunk kell az adatokat, hogy az egyes változók skálája azonos legyen. Miért fontos ez? Nos, ha a változók skálája nem azonos, a modell torzíthat a nagyobb nagyságrendű változók, például a Fresh vagy a Milk (lásd a fenti táblázatot) felé.
Ezért először normalizáljuk az adatokat, és hozzuk az összes változót azonos skálára:
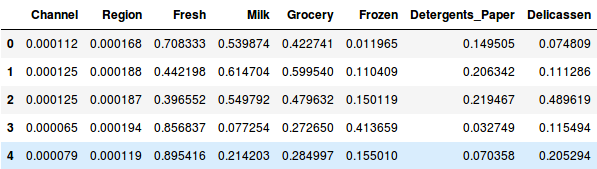
Itt láthatjuk, hogy az összes változó skálája majdnem hasonló. Most már készen állunk. Először rajzoljuk meg a dendrogramot, amely segít eldönteni a klaszterek számát az adott problémához:
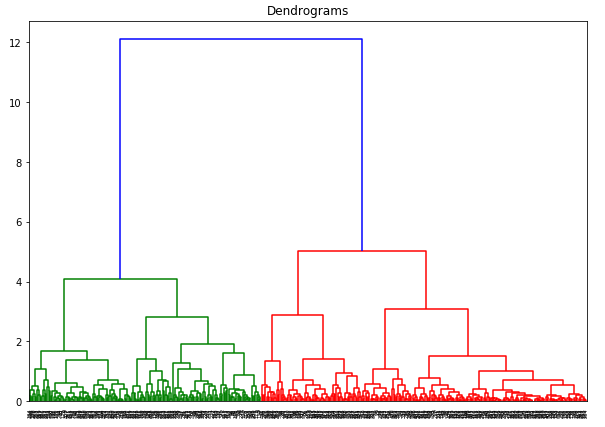
Az x tengely a mintákat tartalmazza, az y tengely pedig a minták közötti távolságot. A maximális távolságot tartalmazó függőleges vonal a kék vonal, és így dönthetünk egy 6-os küszöbértékről, és vághatjuk a dendrogramot:
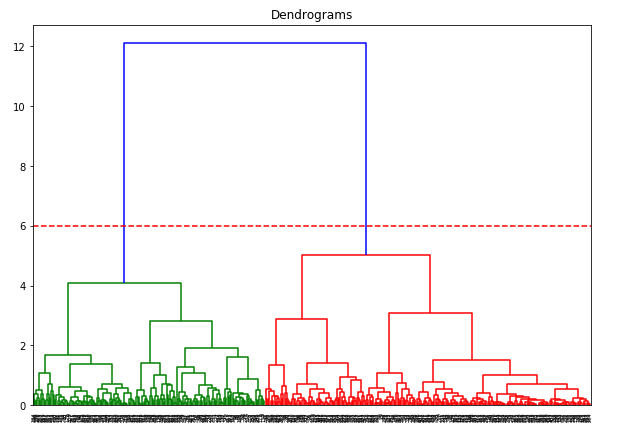
Két klaszterünk van, mivel ez a vonal két ponton vágja a dendrogramot. Alkalmazzuk most a hierarchikus klaszterezést 2 klaszterre:
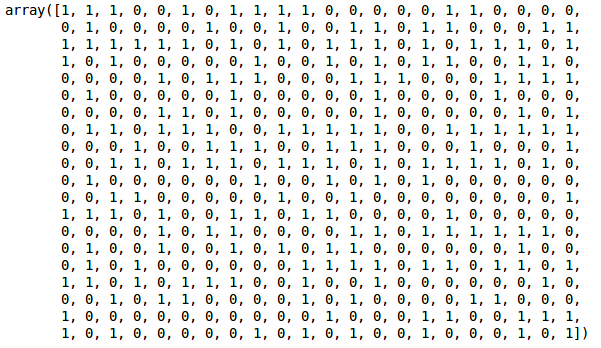
A kimeneten láthatjuk a 0s és 1s értékeket, mivel 2 klasztert definiáltunk. A 0 az első klaszterbe tartozó pontokat, az 1 pedig a második klaszterbe tartozó pontokat jelöli. Most vizualizáljuk a két klasztert:
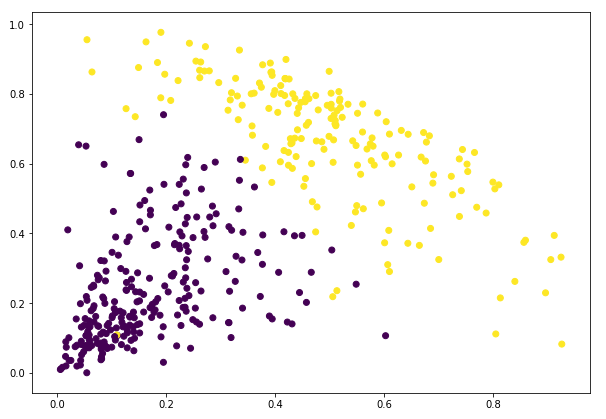
Félelmetes! Itt jól láthatóan vizualizálhatjuk a két klasztert. Így valósíthatjuk meg a hierarchikus klaszterezést Pythonban.
Végjegyzetek
A hierarchikus klaszterezés egy szuper hasznos módja a megfigyelések szegmentálásának. Az az előnye, hogy nem kell előre meghatározni a klaszterek számát, elég nagy előnyt jelent a k-Means-hez képest.
Ha még viszonylag új vagy az adattudományban, nagyon ajánlom az Alkalmazott gépi tanulás kurzus elvégzését. Ez az egyik legátfogóbb végponttól végpontig tartó gépi tanfolyam, amit bárhol találsz. A hierarchikus klaszterezés csak egy a sokféle téma közül, amelyet a kurzuson tárgyalunk.