Quantrium útmutatók

A Tesseract egy optikai karakterfelismerő motor, amely különböző operációs rendszereken használható. Szabad szoftver, amelyet az Apache License alatt adtak ki. A Tesseractot eredetileg a Hewlett-Packard fejlesztette ki szabadalmaztatott szoftverként az 1980-as években, később, 2005-ben nyílt forráskódú szoftverként adták ki. Majd 2006-tól a Google szponzorálja a fejlesztését. Ebben az útmutatóban végigvezetem azokat a lépéseket, amelyeket én követtem a Tesseract telepítéséhez a Windows 10-es gépemre. Azt is megmutatom, hogyan használhatja a tesseractot a parancssorból, miután sikeresen telepítette.
A Tesseract 4 telepítéséhez a Windows rendszerünkre a következő linkre kell lépni:
Töltse le a Windows futtatható fájlt a tesseract-ocr-w64-setup-v4.1.0.20190314.exe című hiperlinkre kattintva. Megjelenik egy értesítés, amely a “Tesseract-ocr-w64-setup-v4.1.0.20190314.exe” nevű exe fájl mentését kéri. Mentse ezt az .exe fájlt oda, ahol elegendő tárhellyel rendelkezik.
Nyissa meg ezt az exe fájlt. Ha az ablak megkérdezi, hogy “Akarja-e engedélyezni, hogy ez a szoftver változtatásokat hajtson végre a rendszerén”, kattintson az igen gombra. A telepítési részbe kerül.
Kattintson a következőre, kattintson az Egyetértek a feltételekkel, és miután kiválasztotta, hogy kinek és mire szeretné telepíteni a Tesseractot (bárki, aki használja ezt a számítógépet/csak nekem. Bármelyiket választhatja), kattintson a következőre.
Pipálja ki a “ScrollView”, “Training Tools”, “Shortcuts creation” és fontos, hogy “Language data” feliratú négyzeteket. Ezeket alapértelmezés szerint be kell jelölni, de csak abban az esetben tegye meg őket, ha az Ön rendszerében még nincsenek bejelölve.
Most, ha idegen nyelveken, például japánul, kínaiul, kurdul vagy indiai nyelveken, például hindi, tamil, bengáli stb. szeretne előrejelzéseket készíteni, jelölje be a “kiegészítő írásadatok” és a “kiegészítő nyelvi adatok” négyzetet is. Ha csak az angol nyelvre szeretne előrejelzéseket készíteni, akkor ezt a lehetőséget nem kell bejelölnie.
Kattintson a Tovább gombra. Válassza ki azt a könyvtárat, ahová a Tesseractot telepíteni kívánja. Nekem alapértelmezés szerint a C:\Program Files\Tesseract-OCR jelenik meg, és én oda telepítettem. Ön a saját választása szerint telepítheti. De vegye figyelembe azt az elérési utat, ahová a Tesseractot telepítette a gépén. Ez fontos.
Most kiválaszthatja a Start menü mappáját, amelyben a programok parancsikonját szeretné létrehozni. Én a “Tesseract-OCR” nevű mappában hoztam létre. Ha egy új mappában szeretné, csak írja be a mappa nevét a “Select the Start Menu folder in which you would like ….” szöveg alatti üres helyre.
A bal alsó sarokban lévő “Do not create shortcuts” négyzetet is bejelölheti, ha nem szeretne parancsikonokat létrehozni. Ha végzett a kívánt opció kiválasztásával, kattintson a telepítés gombra. A telepítésnek néhány percet kell igénybe vennie.
A telepítés befejezése után menjen abba a könyvtárba, ahová a Tesseractot telepítette. A Tesseractot a windows parancssorából szeretnénk használni, ehhez pedig hozzá kell adnunk a Tesseractot a rendszer környezeti változójának elérési útvonalához.
Ezért kattintsunk a start gombra a windowson, és keressük meg a “környezeti változó” szót. Megjelenik a “Rendszerkörnyezeti változók szerkesztése” nevű találat. Kattints rá erre. Miután erre kattintottál, a “Rendszer tulajdonságai” “Speciális” részében kell lenned, és a jobb alsó sarokban láthatóvá kell válnia a “Környezeti változók ….” nevű gombnak. Kattintson erre a gombra.
Most, itt két táblázatot fog látni. Az egyiknek a neve User variables for <username>. Itt a <username> egy változó, ami a PC-t jelenleg használó felhasználónevet jelöli. A másik táblázat neve “Rendszer változók”. A “Rendszer változók” táblázatban kattintson a “Path” nevű változóra, majd kattintson erre a “Edit” nevű gombra, közvetlenül az “OK” gomb felett, ahogy az alábbi képernyőképen lent látható.
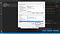
Ha ezzel végzett, megjelenik a “Edit environment variable” nevű oldal. Itt a jobb felső sarokban egy “Új” nevű gombot fogsz látni. Kattints erre az “Új” gombra. Kapsz egy üres helyet, ahol hozzáadhatsz egy kis szöveget. Ide írja be a könyvtár nevét, ahol az összes Tesseract-OCR fájlját tárolja.
Amikor beírta a könyvtár nevét, nyomja meg az “Enter”-t, és ellenőrizze, hogy a könyvtár neve bekerült-e a “Környezeti változó szerkesztése táblázatba”. Ha ez megtörtént, kattintson az “OK” gombra. Kattintson ismét az OK gombra a “Környezeti változók” oldalon. Kattintson ismét az “OK” gombra a “Rendszer tulajdonságai” oldalon. Most már minden beállítási lehetőségből ki kell lépnie.
Nyissa meg a parancssort, és írja be a tesseract --version parancsot a parancssorba, majd nyomja meg az Entert. Valami ilyesmit fog látni:
Ha bármilyen hibát lát, mint tesseract command not found, akkor valószínűleg valamilyen hibát követett el az útmutató követése során. Menjen vissza, és nézze meg, hol rontotta el, és próbálja meg kijavítani. Alternatívaként megismételheti az egész folyamatot újra.
Nagyszerű! Most már telepítette a Tesseractot a gépére. Elkezdhetsz vele játszani és tovább vizsgálódni.
Hogyan használd a Tesseract 4-et parancssor segítségével Windows gépen
Először is, győződj meg róla, hogy van valamilyen kézzel írt dokumentumod vagy valamilyen gépelt dokumentumod kép formájában. Tegyük fel, hogy van valamilyen png formátumú fényképed handwritten_photo_1 néven az asztalon, és ezzel szeretnéd tesztelni a Tesseractot. Nyissa meg a parancssorát. Ebben a könyvtárban fogsz indulni:
C:\Users\username>
ahol username a felhasználóneved az adott rendszeren. Az asztali könyvtárba kell mennem. Ezért a következő parancsot használom:
C:\Users\username> cd Desktop
Most már az Asztal könyvtárban vagyok, ahol a képem található. A következő paranccsal láthatjuk, hogy a Tesseract mit jósol a dokumentumban lévő szövegnek:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
A Tesseract közvetlenül magában a parancssorban adja ki a szöveget. A -l paraméter a nyelv megadására szolgál. Itt angolul adtuk meg, ami alapértelmezés szerint amúgy is így van, így a -l eng használata ebben az esetben felesleges volt. Ha más nyelvet szeretne használni az OCR-hez, nézze meg ezt a linket, amely tartalmazza az összes .traineddata fájlt, amely meghatározza a nyelvet:
Tegyük fel, hogy van egy hindi nyelven írt szöveges dokumentum. Ezután lépjen erre a fenti linkre, kattintson a hin.traineddata című fájlra, és töltse le. Miután letöltötte, át kell helyeznie a “tessdata” mappába, amely a tesseract eredeti telepítési helyének könyvtárában lesz. Miután ezt megtette, a következő paranccsal végezheti el a hindi dokumentumok OCR-felismerését:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
Ahelyett, hogy az OCR-kimenetet magában a parancssorban jelenítené meg, tegyük fel, hogy az OCR-kimenetet egy szöveges fájlban szeretné tárolni. Ebben az esetben a következő parancsot adhatja be helyette:
tesseract handwritten_photo_1.png output.txt
A handwritten_photo_1.png-ban lévő szöveget egy output.txt nevű szöveges fájlban fogja tárolni, amely a jelenlegi munkakönyvtárában lesz, ami az én esetemben az Asztal volt.
A Tesseract egy szöveges fájlt is elfogadhat bemenetként, ahol a szövegnek tartalmaznia kell a feldolgozni kívánt képek összes abszolút elérési útvonalát.
Ez különösen akkor hasznos, ha, mondjuk, két kézzel írt angol nyelvű képed van handwritten_photo_1.png és handwritten_photo_2.png néven a C:\Program Files könyvtárban. Most a jelenlegi munkakönyvtáradban van egy input.txt nevű szövegfájlod, amelynek tartalma:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
Az első és a második sorban.
Ha most ennek a két kézzel írt képnek a tartalmát akarod egy szövegfájlban tárolni, akkor csak a következőt kell tenned:
tesseract input.txt output.txt -l eng
output.txt mind a handwritten_photo_1.png és handwritten_photo_2.png OCR tartalmát tartalmazza, ebben a sorrendben. Itt érdemes megjegyezni, hogy a input.txt az aktuális munkakönyvtárban volt. A tesseractot használhatja olyan szövegfájlra is, amely nem a jelenlegi munkakönyvtárban van, ha a könyvtár helyét is megadja, mint itt:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt ismét a jelenlegi munkakönyvtárban lesz. Ezt kettőnél több fotó esetében is megteheti. Vegye figyelembe, hogy a output.txt fájlban lévő új fotó előrejelzését valamilyen szimbólum fogja megelőzni, mint:
Ez esetben tehát Viral Calic az első kép előrejelzése, CY am the king of the world a második kép előrejelzése, Com and Serr a harmadik kép előrejelzése és így tovább. Ellenőrizheti a kimenetet az összes bemeneti képre, és ellenőrizheti a jóslatok pontosságát.
Ez az! Gratulálunk, most már minden készen áll, és készen áll a Tesseract használatára a Windows 10 rendszerén.