Introduzione
È fondamentale capire il comportamento dei clienti in qualsiasi settore. Me ne sono reso conto l’anno scorso quando il mio capo marketing mi ha chiesto: “Puoi dirmi a quali clienti esistenti dovremmo puntare per il nostro nuovo prodotto?”
Questa è stata una bella curva di apprendimento per me. Ho capito subito, come scienziato dei dati, quanto sia importante segmentare i clienti in modo che la mia organizzazione possa personalizzare e costruire strategie mirate. È qui che il concetto di clustering si è rivelato molto utile!
Problemi come la segmentazione dei clienti sono spesso ingannevolmente difficili perché non stiamo lavorando con nessuna variabile target in mente. Siamo ufficialmente nella terra dell’apprendimento non supervisionato dove abbiamo bisogno di capire i modelli e le strutture senza un risultato stabilito in mente. È sia impegnativo che eccitante come scienziato dei dati.
Ora, ci sono alcuni modi diversi per eseguire il clustering (come vedrete di seguito). Vi presenterò uno di questi tipi in questo articolo – il clustering gerarchico.
Impareremo cos’è il clustering gerarchico, il suo vantaggio rispetto agli altri algoritmi di clustering, i diversi tipi di clustering gerarchico e i passi per eseguirlo. Infine prenderemo un set di dati di segmentazione dei clienti e poi implementeremo il clustering gerarchico in Python. Amo questa tecnica e sono sicuro che anche voi la amerete dopo questo articolo!
Nota: Come detto, ci sono diversi modi per eseguire il clustering. Vi incoraggio a controllare la nostra fantastica guida ai diversi tipi di clustering:
- Un’introduzione al clustering e ai diversi metodi di clustering
Per saperne di più sul clustering e su altri algoritmi di apprendimento automatico (sia supervisionati che non supervisionati) controlla il seguente programma completo-
- Programma certificato AI & ML Blackbelt+
Tabella dei contenuti
- Apprendimento supervisionato vs non supervisionato
- Perché il clustering gerarchico?
- Che cos’è il Clustering gerarchico?
- Tipi di Clustering Gerarchico
- Clustering Gerarchico Agglomerativo
- Clustering Gerarchico Divisivo
- Passi per eseguire il Clustering Gerarchico
- Come scegliere il numero di cluster nel Clustering Gerarchico?
- Risolvere un problema di segmentazione dei clienti all’ingrosso usando il clustering gerarchico
Apprendimento supervisionato e non supervisionato
È importante capire la differenza tra apprendimento supervisionato e non supervisionato prima di immergerci nel clustering gerarchico. Lasciatemi spiegare questa differenza usando un semplice esempio.
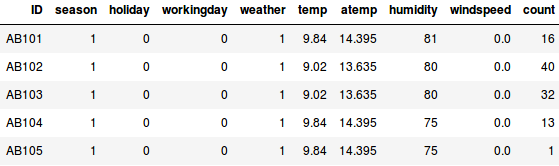
Supponiamo di voler stimare il numero di biciclette che saranno affittate in una città ogni giorno:
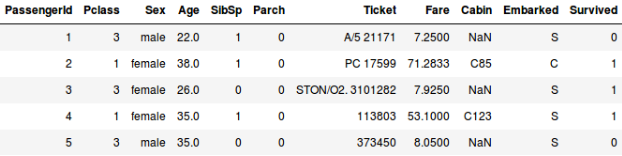
Oppure, diciamo che vogliamo prevedere se una persona a bordo del Titanic è sopravvissuta o meno:
Abbiamo un obiettivo fisso da raggiungere in entrambi questi esempi:
- Nel primo esempio, dobbiamo prevedere il numero di biciclette in base a caratteristiche come la stagione, le vacanze, il giorno lavorativo, il tempo, la temperatura, ecc.
- Nel secondo esempio stiamo prevedendo se un passeggero è sopravvissuto o meno. Nella variabile ‘Sopravvissuto’, 0 rappresenta che la persona non è sopravvissuta e 1 significa che la persona ne è uscita viva. Le variabili indipendenti qui includono Pclass, Sex, Age, Fare, etc.
Quindi, quando ci viene data una variabile target (count e Survival nei due casi precedenti) che dobbiamo predire sulla base di un dato set di predittori o variabili indipendenti (season, holiday, Sex, Age, etc.), tali problemi sono chiamati supervised.), tali problemi sono chiamati problemi di apprendimento supervisionato.
Guardiamo la figura qui sotto per capirlo visivamente:
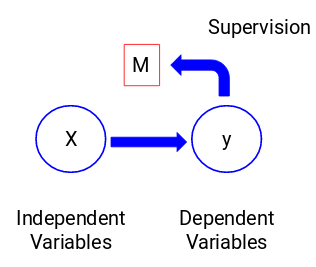
Qui, y è la nostra variabile dipendente o target, e X rappresenta le variabili indipendenti. La variabile obiettivo dipende da X e quindi è anche chiamata variabile dipendente. Addestriamo il nostro modello usando le variabili indipendenti nella supervisione della variabile obiettivo e da qui il nome di apprendimento supervisionato.
Il nostro obiettivo, quando addestriamo il modello, è quello di generare una funzione che mappa le variabili indipendenti all’obiettivo desiderato. Una volta che il modello è addestrato, possiamo passare nuove serie di osservazioni e il modello predirà l’obiettivo per esse. Questo, in poche parole, è l’apprendimento supervisionato.
Ci possono essere situazioni in cui non abbiamo alcuna variabile target da prevedere. Tali problemi, senza alcuna variabile obiettivo esplicita, sono noti come problemi di apprendimento non supervisionato. In questi problemi abbiamo solo le variabili indipendenti e nessuna variabile obiettivo/dipendente.

Tentiamo di dividere l’insieme dei dati in un insieme di gruppi in questi casi. Questi gruppi sono conosciuti come cluster e il processo di creazione di questi cluster è conosciuto come clustering.
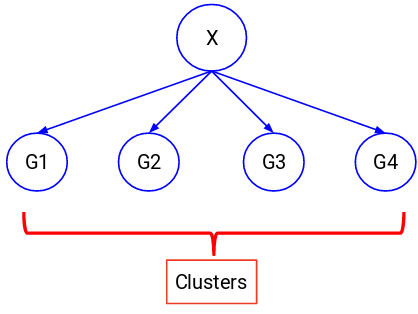
Questa tecnica è generalmente usata per raggruppare una popolazione in diversi gruppi. Alcuni esempi comuni includono la segmentazione dei clienti, il raggruppamento di documenti simili, la raccomandazione di canzoni o film simili, ecc.
Ci sono molte altre applicazioni di apprendimento non supervisionato. Se ti imbatti in qualche applicazione interessante, sentiti libero di condividerla nella sezione commenti qui sotto!
Ora, ci sono vari algoritmi che ci aiutano a fare questi cluster. Gli algoritmi di clustering più comunemente usati sono K-means e Hierarchical clustering.
Perché Hierarchical Clustering?
Dovremmo prima sapere come funziona K-means prima di tuffarci nel clustering gerarchico. Credetemi, renderà il concetto di clustering gerarchico ancora più facile.
Ecco una breve panoramica su come funziona K-means:
- Decidere il numero di cluster (k)
- Selezionare k punti casuali dai dati come centroidi
- Assegnare tutti i punti al centroide del cluster più vicino
- Calcolare il centroide dei cluster appena formati
- Ripetere i passi 3 e 4
È un processo iterativo. Continuerà a funzionare fino a quando i centroidi dei cluster appena formati non cambiano o il numero massimo di iterazioni viene raggiunto.
Ma ci sono alcune sfide con K-means. Cerca sempre di fare cluster della stessa dimensione. Inoltre, dobbiamo decidere il numero di cluster all’inizio dell’algoritmo. Idealmente, non sapremmo quanti cluster dovremmo avere, all’inizio dell’algoritmo e quindi è una sfida con K-means.
Questo è un gap che il clustering gerarchico supera con aplomb. Toglie il problema di dover predefinire il numero di cluster. Sembra un sogno! Quindi, vediamo cos’è il clustering gerarchico e come migliora il K-means.
Che cos’è il clustering gerarchico?
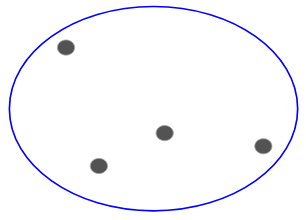
Diciamo che abbiamo i seguenti punti e vogliamo raggrupparli:

Possiamo assegnare ciascuno di questi punti ad un cluster separato:

Ora, in base alla somiglianza di questi cluster, possiamo combinare i cluster più simili insieme e ripetere questo processo fino a quando rimane un solo cluster:
Stiamo essenzialmente costruendo una gerarchia di cluster. Ecco perché questo algoritmo è chiamato clustering gerarchico. Discuterò come decidere il numero di cluster in una sezione successiva. Per ora, guardiamo i diversi tipi di clustering gerarchico.
Tipi di clustering gerarchico
Ci sono principalmente due tipi di clustering gerarchico:
- Clustering gerarchico aggregativo
- Clustering gerarchico divisivo
Capiamo ogni tipo in dettaglio.
Clustering gerarchico aggregativo
In questa tecnica assegniamo ogni punto ad un cluster individuale. Supponiamo che ci siano 4 punti di dati. Assegneremo ognuno di questi punti ad un cluster e quindi avremo 4 cluster all’inizio:
Poi, ad ogni iterazione, fondiamo la coppia di cluster più vicina e ripetiamo questo passo fino a quando rimane un solo cluster:
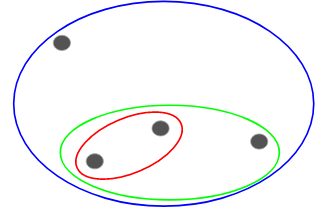
Siamo fondendo (o aggiungendo) i cluster ad ogni passo, giusto? Quindi, questo tipo di clustering è anche conosciuto come clustering gerarchico additivo.
Clustering gerarchico divisivo
Il clustering gerarchico divisivo funziona al contrario. Invece di iniziare con n cluster (nel caso di n osservazioni), iniziamo con un solo cluster e assegniamo tutti i punti a quel cluster.
Quindi, non importa se abbiamo 10 o 1000 punti dati. Tutti questi punti apparterranno allo stesso cluster all’inizio:
Ora, ad ogni iterazione, dividiamo il punto più lontano nel cluster e ripetiamo questo processo fino a quando ogni cluster contiene un solo punto:
Stiamo dividendo (o dividendo) i cluster ad ogni passo, da cui il nome clustering gerarchico divisivo.
Il clustering aggregativo è ampiamente usato nell’industria e sarà l’obiettivo di questo articolo. Il clustering gerarchico divisivo sarà un gioco da ragazzi una volta che avremo un’idea del tipo agglomerativo.
Passi per eseguire il clustering gerarchico
Con il clustering gerarchico uniamo i punti o cluster più simili – lo sappiamo. Ora la domanda è: come decidiamo quali punti sono simili e quali no? È una delle domande più importanti nel clustering!
Ecco un modo per calcolare la somiglianza – Prendi la distanza tra i centroidi di questi cluster. I punti che hanno la distanza minore sono indicati come punti simili e possiamo unirli. Possiamo riferirci a questo come un algoritmo basato sulla distanza (dato che stiamo calcolando le distanze tra i cluster).
Nel clustering gerarchico, abbiamo un concetto chiamato matrice di prossimità. Questa memorizza le distanze tra ogni punto. Facciamo un esempio per capire questa matrice e i passi per eseguire il clustering gerarchico.
Impostazione dell’esempio

Supponiamo che un insegnante voglia dividere i suoi studenti in diversi gruppi. Ha i voti ottenuti da ogni studente in un compito e in base a questi voti, vuole segmentarli in gruppi. Non c’è un obiettivo fisso su quanti gruppi avere. Poiché l’insegnante non sa che tipo di studenti dovrebbe essere assegnato a quale gruppo, non può essere risolto come un problema di apprendimento supervisionato. Quindi, cercheremo di applicare il clustering gerarchico qui e segmentare gli studenti in diversi gruppi.
Prendiamo un campione di 5 studenti:
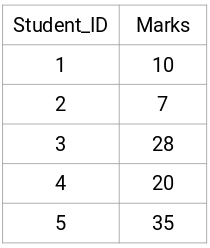
Creazione di una matrice di prossimità
Primo, creeremo una matrice di prossimità che ci dirà la distanza tra ciascuno di questi punti. Poiché stiamo calcolando la distanza di ogni punto da ognuno degli altri punti, otterremo una matrice quadrata di forma n X n (dove n è il numero di osservazioni).
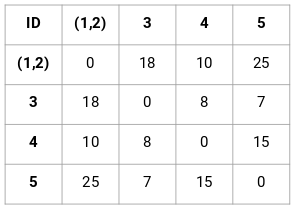
Creiamo la matrice di prossimità 5 x 5 per il nostro esempio:
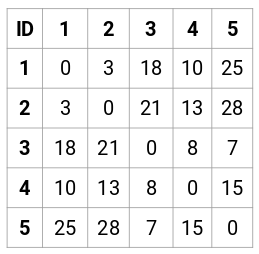
Gli elementi diagonali di questa matrice saranno sempre 0 poiché la distanza di un punto con se stesso è sempre 0. Useremo la formula della distanza euclidea per calcolare il resto delle distanze. Quindi, diciamo che vogliamo calcolare la distanza tra il punto 1 e 2:
√(10-7)^2 = √9 = 3
Similmente, possiamo calcolare tutte le distanze e riempire la matrice di prossimità.
Passi per eseguire il clustering gerarchico
Passo 1: Per prima cosa, assegniamo tutti i punti ad un cluster individuale:
![]()
I colori diversi qui rappresentano cluster diversi. Potete vedere che abbiamo 5 cluster diversi per i 5 punti nei nostri dati.
Passo 2: Poi, guardiamo la distanza più piccola nella matrice di prossimità e uniamo i punti con la distanza più piccola. Aggiorniamo quindi la matrice di prossimità:
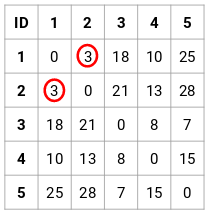
Qui la distanza più piccola è 3 e quindi uniremo i punti 1 e 2:
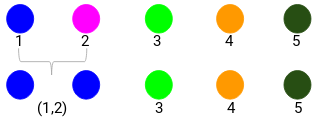
Guardiamo i cluster aggiornati e aggiorniamo di conseguenza la matrice di prossimità:
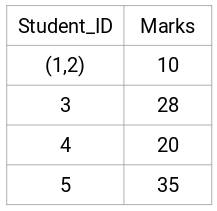
Qui abbiamo preso il massimo dei due segni (7, 10) per sostituire i segni per questo cluster. Invece del massimo, possiamo anche prendere il valore minimo o i valori medi. Ora, calcoleremo di nuovo la matrice di prossimità per questi cluster:
Passo 3: Ripeteremo il passo 2 fino a quando rimarrà un solo cluster.
Quindi, guarderemo prima la distanza minima nella matrice di prossimità e poi fonderemo la coppia di cluster più vicina. Otterremo i cluster fusi come mostrato di seguito dopo aver ripetuto questi passaggi:
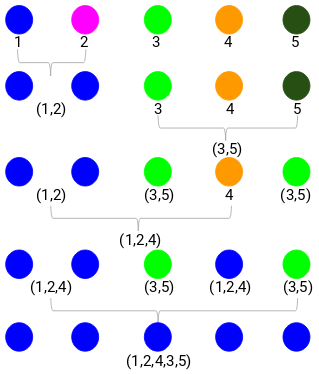
Abbiamo iniziato con 5 cluster e finalmente abbiamo un unico cluster. Ecco come funziona il clustering gerarchico agglomerativo. Ma la domanda scottante rimane ancora – come decidiamo il numero di cluster? Cerchiamo di capirlo nella prossima sezione.
Come scegliere il numero di cluster nel clustering gerarchico?
Pronti a rispondere finalmente a questa domanda che è rimasta in sospeso da quando abbiamo iniziato a imparare? Per ottenere il numero di cluster per il clustering gerarchico, facciamo uso di un concetto fantastico chiamato dendrogramma.
Un dendrogramma è un diagramma ad albero che registra le sequenze di fusioni o suddivisioni.
Torniamo al nostro esempio insegnante-studente. Ogni volta che fondiamo due cluster, un dendrogramma registrerà la distanza tra questi cluster e la rappresenterà in forma di grafico. Vediamo come appare un dendrogramma:
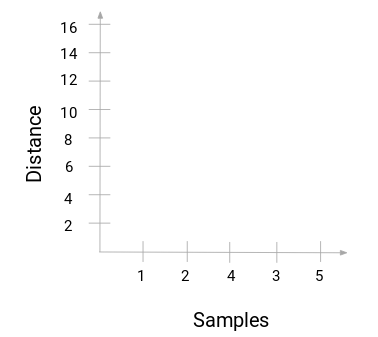
Abbiamo i campioni del dataset sull’asse delle x e la distanza sull’asse delle y. Ogni volta che due cluster si uniscono, li uniremo in questo dendrogramma e l’altezza dell’unione sarà la distanza tra questi punti. Costruiamo il dendrogramma per il nostro esempio:
Prendetevi un momento per elaborare l’immagine sopra. Abbiamo iniziato unendo i campioni 1 e 2 e la distanza tra questi due campioni è 3 (fate riferimento alla prima matrice di prossimità nella sezione precedente). Tracciamo questo nel dendrogramma:
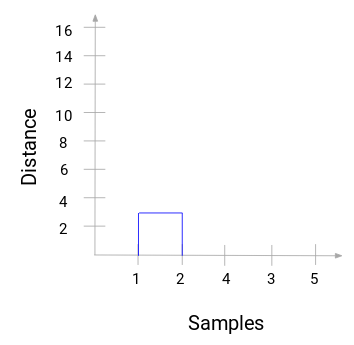
Qui possiamo vedere che abbiamo unito il campione 1 e 2. La linea verticale rappresenta la distanza tra questi campioni. Allo stesso modo, tracciamo tutti i passi in cui abbiamo unito i cluster e infine, otteniamo un dendrogramma come questo:
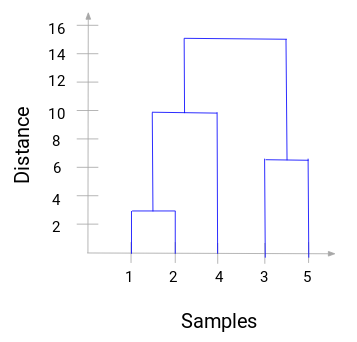
Possiamo visualizzare chiaramente i passi del clustering gerarchico. Più la distanza delle linee verticali nel dendrogramma, più la distanza tra questi cluster.
Ora, possiamo impostare una distanza di soglia e disegnare una linea orizzontale (generalmente, cerchiamo di impostare la soglia in modo tale che tagli la linea verticale più alta). Impostiamo questa soglia a 12 e disegniamo una linea orizzontale:
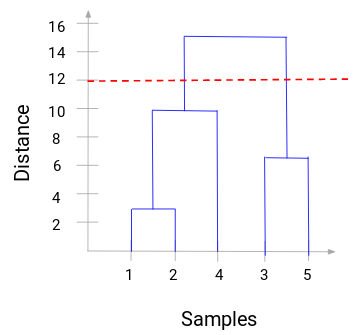
Il numero di cluster sarà il numero di linee verticali che vengono intersecate dalla linea disegnata usando la soglia. Nell’esempio precedente, poiché la linea rossa interseca 2 linee verticali, avremo 2 cluster. Un cluster avrà un campione (1,2,4) e l’altro avrà un campione (3,5). Abbastanza semplice, vero?
Ecco come possiamo decidere il numero di cluster usando un dendrogramma in Hierarchical Clustering. Nella prossima sezione, implementeremo il clustering gerarchico che vi aiuterà a capire tutti i concetti che abbiamo imparato in questo articolo.
Risolvere il problema della segmentazione dei clienti all’ingrosso usando il clustering gerarchico
E’ ora di sporcarsi le mani in Python!
Lavoreremo su un problema di segmentazione dei clienti all’ingrosso. Potete scaricare il set di dati usando questo link. I dati sono ospitati sul repository UCI Machine Learning. Lo scopo di questo problema è di segmentare i clienti di un distributore all’ingrosso in base alla loro spesa annuale per diverse categorie di prodotti, come latte, alimentari, regione, ecc.
Prima esploriamo i dati e poi applichiamo il Clustering gerarchico per segmentare i clienti.
Prima importiamo le librerie necessarie:
Carichiamo i dati e guardiamo le prime righe:
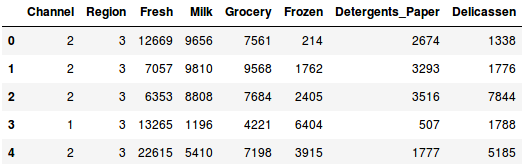
Ci sono più categorie di prodotti – Fresco, Latte, Alimentari, ecc. I valori rappresentano il numero di unità acquistate da ogni cliente per ogni prodotto. Il nostro obiettivo è quello di creare dei cluster da questi dati che possano segmentare insieme clienti simili. Useremo, naturalmente, il Clustering Gerarchico per questo problema.
Ma prima di applicare il Clustering Gerarchico, dobbiamo normalizzare i dati in modo che la scala di ogni variabile sia la stessa. Perché questo è importante? Beh, se la scala delle variabili non è la stessa, il modello potrebbe essere distorto verso le variabili con una grandezza maggiore come Fresco o Latte (fare riferimento alla tabella sopra).
Quindi, per prima cosa normalizziamo i dati e portiamo tutte le variabili alla stessa scala:
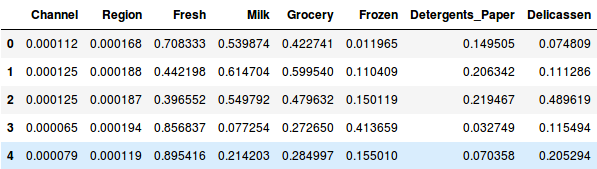
Qui, possiamo vedere che la scala di tutte le variabili è quasi simile. Ora, siamo pronti a partire. Disegniamo prima il dendrogramma per aiutarci a decidere il numero di cluster per questo particolare problema:
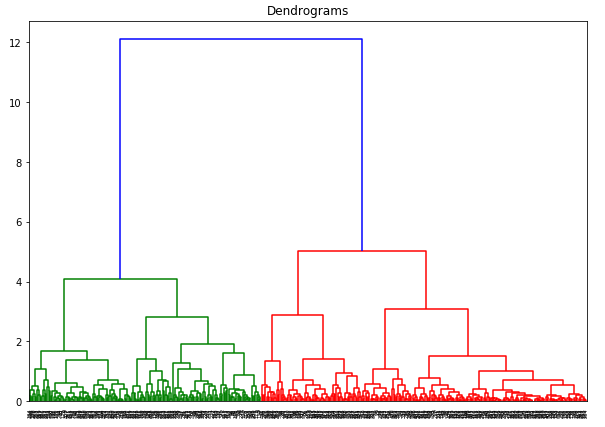
L’asse x contiene i campioni e l’asse y rappresenta la distanza tra questi campioni. La linea verticale con la distanza massima è la linea blu e quindi possiamo decidere una soglia di 6 e tagliare il dendrogramma:
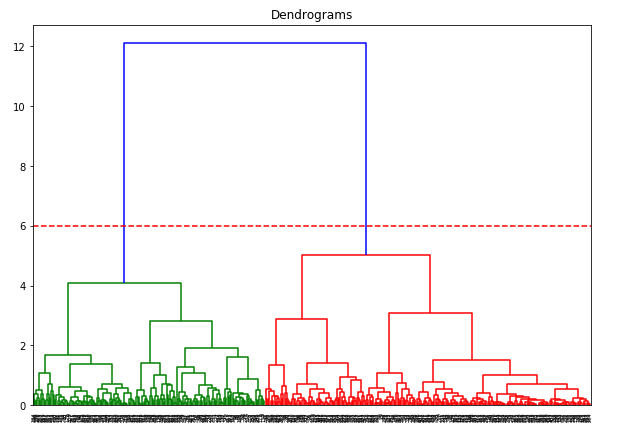
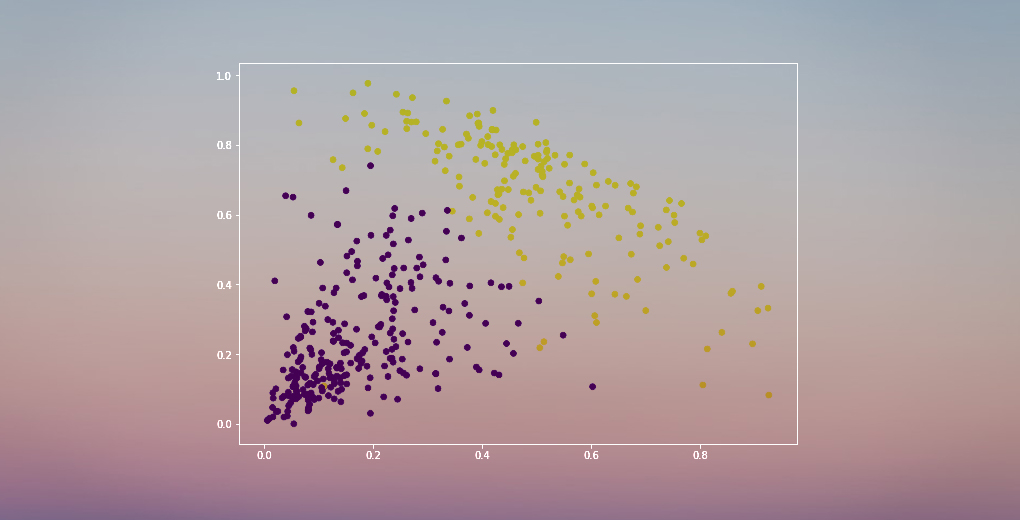
Abbiamo due cluster poiché questa linea taglia il dendrogramma in due punti. Applichiamo ora il clustering gerarchico per 2 cluster:
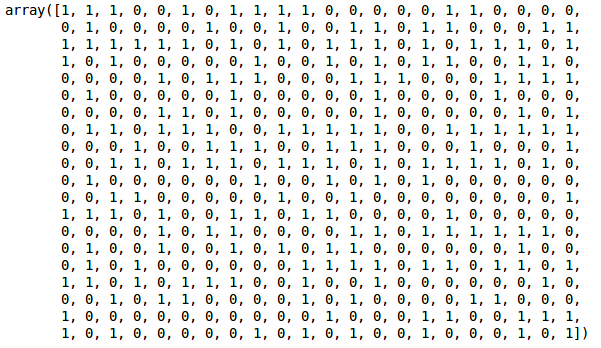
Possiamo vedere i valori di 0s e 1s nell’output poiché abbiamo definito 2 cluster. 0 rappresenta i punti che appartengono al primo cluster e 1 rappresenta i punti nel secondo cluster. Visualizziamo ora i due cluster:
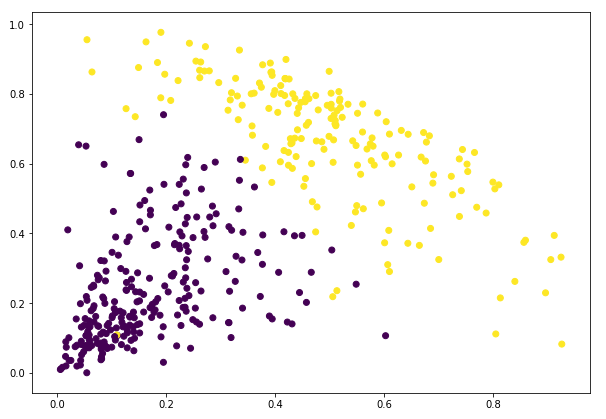
Fantastico! Qui possiamo visualizzare chiaramente i due cluster. Ecco come possiamo implementare il clustering gerarchico in Python.
Note finali
Il clustering gerarchico è un modo super utile per segmentare le osservazioni. Il vantaggio di non dover predefinire il numero di cluster gli conferisce un certo vantaggio rispetto a k-Means.
Se sei ancora relativamente nuovo alla scienza dei dati, ti consiglio vivamente di seguire il corso Applied Machine Learning. E’ uno dei corsi di apprendimento automatico più completi che possiate trovare ovunque. Il clustering gerarchico è solo uno dei diversi argomenti che trattiamo nel corso.
Il clustering gerarchico è solo uno dei diversi argomenti che trattiamo nel corso.