GuideQuantrium

Tesseract è un motore di riconoscimento ottico dei caratteri che può essere utilizzato su vari sistemi operativi. È un software libero, rilasciato sotto la licenza Apache. Originariamente, Tesseract è stato sviluppato da Hewlett-Packard come software proprietario negli anni ’80, poi è stato rilasciato come software open source nel 2005. Poi dal 2006, il suo sviluppo è stato sponsorizzato da Google. In questa guida, vi porterò attraverso i passi che ho seguito per installare Tesseract sulla mia macchina Windows 10. Vi mostrerò anche come potete usare tesseract dalla linea di comando una volta che l’avete installato con successo.
Per installare Tesseract 4 sul nostro sistema Windows, andate al seguente link:
Scaricate il file eseguibile di windows cliccando sull’hyper link intitolato tesseract-ocr-w64-setup-v4.1.0.20190314.exe. Apparirà una notifica che ti chiederà di salvare un file exe chiamato “Tesseract-ocr-w64-setup-v4.1.0.20190314.exe”. Salva questo file .exe ovunque tu abbia abbastanza spazio di archiviazione.
Apri questo file exe. Se la finestra ti chiede “Do you want to allow this software to make changes to your system”, clicca su yes. Sarai portato alla sezione di installazione.
Prendi Avanti, clicca su Accetto i termini e le condizioni e dopo aver selezionato per chi e tutto ciò che vuoi installare Tesseract (chiunque usi questo computer/solo per me. Puoi selezionare entrambi), clicca Avanti.
Spunta le caselle che dicono “ScrollView”, “Training Tools”, “Shortcuts creation” e, importante, “Language data”. Questi dovrebbero essere spuntati per impostazione predefinita, ma fatelo solo nel caso in cui non siano stati spuntati nel vostro sistema.
Ora, se volete fare previsioni in lingue straniere come giapponese, cinese, curdo o lingue indiane come hindi, tamil, bengali ecc, spuntate anche i “dati script aggiuntivi” e “dati lingua aggiuntivi”. Se vuoi fare previsioni solo per la lingua inglese, non devi spuntare questa opzione.
Clicca su Next. Seleziona la directory dove vuoi installare Tesseract. Di default mostra C:\Program Files\Tesseract-OCR per me ed è lì che l’ho installato. Puoi installarlo come preferisci. Ma prendete nota del percorso in cui avete installato Tesseract sulla vostra macchina. Questo è importante.
Ora puoi selezionare la cartella del menu di avvio in cui vorresti creare il collegamento ai programmi. Io l’ho creato in una cartella chiamata “Tesseract-OCR”. Se lo vuoi in una nuova cartella, basta digitare il nome della cartella nello spazio vuoto proprio sotto il testo “Select the Start Menu folder in which you would like ….”.
Puoi anche spuntare la casella “Do not create shortcuts” in basso a sinistra se non vuoi creare alcun collegamento. Una volta che hai finito di selezionare la tua opzione preferita, clicca su installa. L’installazione dovrebbe durare qualche minuto.
Una volta che l’installazione è finita, vai nella directory dove hai installato Tesseract. Vogliamo usare Tesseract dalla nostra linea di comando di Windows e per farlo, dobbiamo aggiungere Tesseract al nostro percorso nella variabile d’ambiente del sistema.
Per farlo, cliccate sul pulsante start di Windows e cercate “variabile d’ambiente”. Vedrete un risultato chiamato “Modifica le variabili d’ambiente del sistema”. Cliccate su quello. Dopo aver cliccato su questo, dovresti essere nella sezione “Avanzate” di “Proprietà di sistema” e un pulsante chiamato “Variabili d’ambiente ….” dovrebbe essere visibile in basso a destra. Clicca su quel pulsante.
Ora, vedrai due tabelle qui. Una si chiama User variables for <username>. Qui, il <username> è una variabile che sta per il nome utente che usa il PC attualmente. L’altra tabella chiamata “Variabili di sistema”. Nella tabella “Variabili di sistema” clicca sulla variabile chiamata “Percorso” e poi clicca su questo pulsante chiamato “Modifica” proprio sopra il pulsante “OK” come mostrato nello screenshot qui sotto.
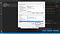
Una volta fatto questo, vedrai una pagina chiamata “Modifica variabile d’ambiente”. Qui, in alto a destra, vedrai un pulsante chiamato “Nuovo”. Clicca su quel pulsante “Nuovo”. Otterrai uno spazio vuoto dove potrai aggiungere del testo. Qui, aggiungi il nome della tua directory dove sono memorizzati tutti i tuoi file Tesseract-OCR.
Una volta digitato il nome della directory, premi “Enter” e controlla se il tuo nome di directory è stato aggiunto alla “Edit environment variable table”. Una volta che lo è stato, clicca su “OK”. Clicca nuovamente su OK nella pagina “Variabili d’ambiente”. Clicca di nuovo su “OK” nella pagina “Proprietà del sistema”. Ora devi essere uscito da tutte le opzioni di impostazione.
Apri il prompt dei comandi e digita tesseract --version sul prompt dei comandi e premi invio. Vedrai qualcosa di simile a questo:
Se vedi qualche errore come tesseract command not found, molto probabilmente hai fatto qualche errore mentre seguivi questa guida. Tornate indietro e vedete dove avete sbagliato e provate a correggerlo. In alternativa, puoi ripetere l’intero processo di nuovo.
Grande! Ora avete Tesseract installato sulla vostra macchina. Puoi iniziare a giocarci ed esplorarlo ulteriormente.
Come usare Tesseract 4 usando la riga di comando su una macchina Windows
Primo, assicurati di avere qualche documento scritto a mano o qualche documento digitato sotto forma di immagine. Diciamo che avete qualche foto in forma png chiamata handwritten_photo_1 sul vostro Desktop e volete testare Tesseract con essa. Aprite il vostro prompt dei comandi. Inizierai in questa directory:
C:\Users\username>
dove username è il tuo nome utente su quel sistema. Ho bisogno di andare nella directory del desktop. Quindi uso il seguente comando:
C:\Users\username> cd Desktop
Ora sono nella directory Desktop, dove si trova la mia immagine. Puoi vedere cosa Tesseract predice il testo nel documento usando il seguente comando:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseract mostrerà direttamente il testo nella linea di comando stessa. Il parametro -l è usato per specificare la lingua. Qui abbiamo specificato l’inglese, che è comunque il caso di default, quindi usare -l eng era ridondante in questo caso. Se vuoi usare qualche altra lingua per l’OCR, controlla questo link qui che ha tutti i file .traineddata, che specificano la lingua:
Supponiamo che tu abbia un documento di testo scritto in Hindi. Poi, vai a questo link qui sopra, clicca sul file intitolato hin.traineddata e scaricalo. Una volta scaricato, dovete spostarvi nella cartella “tessdata”, che sarà all’interno della vostra directory dove avevate originariamente installato tesseract. Una volta fatto questo, puoi eseguire l’OCR dei documenti Hindi usando il seguente comando:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
Invece di visualizzare l’output OCR sulla linea di comando stessa, diciamo che vuoi che il tuo output OCR sia memorizzato in un file di testo. In questo caso puoi invece inserire il seguente comando:
tesseract handwritten_photo_1.png output.txt
Il testo in handwritten_photo_1.png sarà memorizzato in un file di testo chiamato output.txt che si troverà nella tua attuale directory di lavoro, che nel mio caso era Desktop.
Tesseract può anche prendere un file di testo come input, dove il testo deve contenere tutti i percorsi assoluti delle immagini che volete elaborare.
Questo è particolarmente utile quando, diciamo che avete due immagini scritte a mano in inglese chiamate handwritten_photo_1.png e handwritten_photo_2.png nella directory C:\Program Files. Ora, nella tua attuale directory di lavoro, hai un file di testo chiamato input.txt il cui contenuto è:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
rispettivamente nella prima e nella seconda riga.
Ora, se vuoi memorizzare il contenuto di queste due foto scritte a mano in un file di testo, puoi semplicemente fare come segue:
tesseract input.txt output.txt -l eng
output.txt avrà il contenuto OCR di entrambi handwritten_photo_1.png e handwritten_photo_2.png, in questo ordine. Qui, dovreste notare che input.txt era nella directory di lavoro corrente. Potete usare tesseract su un file di testo che non si trova nell’attuale directory di lavoro includendo la posizione della directory come qui:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt si troverà nuovamente nell’attuale directory di lavoro. Puoi fare così anche per più di due foto. Nota che la previsione di una nuova foto nel file output.txt sarà preceduta da qualche simbolo come:
Quindi in questo caso, Viral Calic è la predizione per la prima immagine, CY am the king of the world la predizione per la seconda immagine, Com and Serr la predizione per la terza immagine e così via. Puoi controllare l’output per tutte le tue immagini in ingresso e verificare l’accuratezza delle predizioni.
Ecco fatto! Congratulazioni, ora sei pronto a usare Tesseract sul tuo sistema Windows 10.
.