Inleiding
Het is in elke bedrijfstak van cruciaal belang om het gedrag van klanten te begrijpen. Ik realiseerde me dit vorig jaar toen mijn chief marketing officer me vroeg – “Kun je me vertellen op welke bestaande klanten we ons moeten richten voor ons nieuwe product?”
Dat was nogal een leercurve voor me. Als datawetenschapper besefte ik al snel hoe belangrijk het is om klanten te segmenteren, zodat mijn organisatie gerichte strategieën op maat kan maken en bouwen. Hier kwam het concept van clustering heel goed van pas!
Problemen zoals het segmenteren van klanten zijn vaak bedrieglijk lastig, omdat we niet werken met een doelvariabele in gedachten. We zijn nu officieel in het land van het leren zonder toezicht, waar we patronen en structuren moeten ontdekken zonder een bepaald resultaat voor ogen te hebben. Het is zowel uitdagend als opwindend voor een datawetenschapper.
Nou, er zijn een paar verschillende manieren om clustering uit te voeren (zoals je hieronder zult zien). Ik zal u in dit artikel kennis laten maken met een van die typen – hiërarchische clustering.
We zullen leren wat hiërarchische clustering is, wat het voordeel ervan is ten opzichte van de andere clusteralgoritmen, de verschillende typen hiërarchische clustering en de stappen om het uit te voeren. Uiteindelijk zullen we een klantsegmentatie dataset nemen en dan hiërarchische clustering implementeren in Python. Ik hou van deze techniek en ik weet zeker dat je dat na dit artikel ook zult doen!
Note: Zoals gezegd, zijn er meerdere manieren om clustering uit te voeren. Ik raad u aan onze geweldige gids over de verschillende soorten clustering te bekijken:
- Een inleiding tot clustering en verschillende methoden om te clusteren
Om meer te weten te komen over clustering en andere algoritmen voor machinaal leren (zowel supervised als unsupervised), kunt u het volgende uitgebreide programma raadplegen-
- An Introduction to Clustering and different methods of clustering
.
- Certified AI & ML Blackbelt+ Program
Inhoudsopgave
- Supervised vs Unsupervised Learning
- Waarom hiërarchisch clusteren?
- Wat is hiërarchisch groeperen?
- Typen hiërarchisch clusteren
- Agglomeratief hiërarchisch clusteren
- Divisief hiërarchisch clusteren
- Stappen om hiërarchisch clusteren uit te voeren
- Hoe kies je het aantal clusters bij hiërarchisch clusteren?
- Het oplossen van een groothandelsklantsegmentatieprobleem met behulp van hiërarchische clustering
Leren onder toezicht versus leren zonder toezicht
Het is belangrijk om het verschil te begrijpen tussen leren onder toezicht en leren zonder toezicht
Het is belangrijk om het verschil te begrijpen tussen leren onder toezicht en leren zonder toezicht
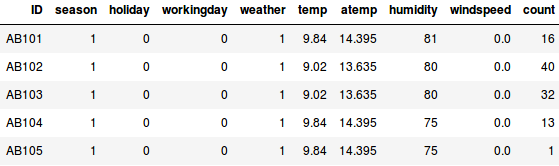
Stel dat we een schatting willen maken van het aantal fietsen dat elke dag in een stad wordt verhuurd:
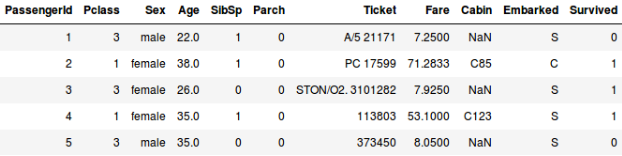
Of stel dat we willen voorspellen of iemand aan boord van de Titanic het heeft overleefd of niet:
We hebben in beide voorbeelden een vast doel dat we moeten bereiken:
- In het eerste voorbeeld moeten we het aantal fietsen voorspellen op basis van kenmerken als het seizoen, de vakantie, de werkdag, het weer, de temperatuur, enz.
- In het tweede voorbeeld voorspellen we of een passagier het heeft overleefd of niet. In de variabele ‘overleefd’ betekent 0 dat de persoon het niet heeft overleefd en 1 dat hij het er levend vanaf heeft gebracht. De onafhankelijke variabelen hier zijn klasse, geslacht, leeftijd, tarief, enz.
Dus, wanneer we een doelvariabele krijgen (telling en overleving in de twee bovenstaande gevallen) die we moeten voorspellen op basis van een gegeven reeks voorspellers of onafhankelijke variabelen (seizoen, vakantie, geslacht, leeftijd, enz.), worden dergelijke problemen problemen met gesuperviseerd leren genoemd.
Laten we eens naar de onderstaande figuur kijken om dit visueel te begrijpen:
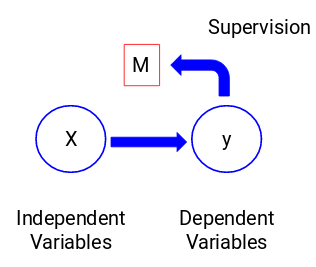
Hier is y onze afhankelijke of doelvariabele, en X vertegenwoordigt de onafhankelijke variabelen. De doelvariabele is afhankelijk van X en wordt daarom ook wel een afhankelijke variabele genoemd. We trainen ons model met behulp van de onafhankelijke variabelen in de supervisie van de doelvariabele en vandaar de naam supervised learning.
Het doel van het trainen van het model is een functie te genereren die de onafhankelijke variabelen aan het gewenste doel koppelt. Als het model eenmaal is getraind, kunnen we nieuwe reeksen waarnemingen doorgeven en zal het model het doel voor hen voorspellen. Dit is, in een notendop, leren onder toezicht.
Er kunnen zich situaties voordoen waarin we geen doelvariabele hebben om te voorspellen. Dergelijke problemen, zonder expliciete doelvariabele, staan bekend als problemen met leren zonder toezicht. We hebben alleen de onafhankelijke variabelen en geen doel-/afhankelijke variabele in deze problemen.

We proberen in deze gevallen de volledige gegevens te verdelen in een reeks groepen. Deze groepen staan bekend als clusters en het proces waarbij deze clusters worden gemaakt, staat bekend als clustering.
Deze techniek wordt in het algemeen gebruikt voor het clusteren van een populatie in verschillende groepen. Een paar veel voorkomende voorbeelden zijn het segmenteren van klanten, het clusteren van vergelijkbare documenten, het aanbevelen van vergelijkbare liedjes of films, enz.
Er zijn nog VEEL meer toepassingen van leren zonder toezicht. Als u een interessante toepassing tegenkomt, voel je vrij om ze te delen in het commentaargedeelte hieronder!
Nu, er zijn verschillende algoritmen die ons helpen om deze clusters te maken. De meest gebruikte clusteringalgoritmen zijn K-means en hiërarchische clustering.
Waarom hiërarchische clustering?
We moeten eerst weten hoe K-means werkt voordat we in hiërarchische clustering duiken. Geloof me, het zal het concept van hiërarchisch clusteren des te gemakkelijker maken.
Hier volgt een kort overzicht van hoe K-means werkt:
- Bepaal het aantal clusters (k)
- Selecteer k willekeurige punten uit de data als centroïden
- Benoem alle punten aan het dichtstbijzijnde clustermiddenpunt
- Bereken het middenpunt van nieuw gevormde clusters
- Herhaal stap 3 en 4
Het is een iteratief proces. Het blijft lopen totdat de centroïden van nieuw gevormde clusters niet meer veranderen of totdat het maximum aantal iteraties is bereikt.
Maar er zijn bepaalde uitdagingen met K-means. Het probeert altijd clusters van dezelfde grootte te maken. Ook moeten we het aantal clusters aan het begin van het algoritme bepalen. Idealiter zouden we niet weten hoeveel clusters moeten we hebben, in het begin van het algoritme en dus is het een uitdaging met K-means.
Dit is een kloof hiërarchische clustering overbrugt met aplomb. Het neemt het probleem weg van het vooraf moeten definiëren van het aantal clusters. Klinkt als een droom! Dus, laten we eens kijken wat hiërarchisch clusteren is en hoe het K-means verbetert.
Wat is hiërarchisch clusteren?
Laten we zeggen dat we de onderstaande punten hebben en we willen ze in groepen clusteren:

We kunnen elk van deze punten aan een aparte cluster toewijzen:

Nu kunnen we, op basis van de overeenkomst van deze clusters, de clusters die het meest op elkaar lijken samenvoegen en dit proces herhalen totdat er nog maar één cluster over is:
We bouwen in wezen een hiërarchie van clusters op. Daarom wordt dit algoritme hiërarchisch clusteren genoemd. Ik zal later bespreken hoe het aantal clusters wordt bepaald. Laten we nu eens kijken naar de verschillende soorten hiërarchische clustering.
Typen hiërarchische clustering
Er zijn hoofdzakelijk twee soorten hiërarchische clustering:
- Agglomeratieve hiërarchische clustering
- Divisieve hiërarchische clustering
Laten we elk type eens in detail bekijken.
Agglomeratieve hiërarchische clustering
Bij deze techniek wijzen we elk punt aan een individuele cluster toe. Stel dat er 4 datapunten zijn. We wijzen elk van deze punten aan een cluster toe en hebben dus in het begin 4 clusters:
Daarna voegen we bij elke iteratie het dichtstbijzijnde clusterpaar samen en herhalen deze stap totdat er nog maar één cluster over is:
We voegen de clusters bij elke stap samen (of voegen ze toe), toch? Vandaar dat dit type clustering ook wel additieve hiërarchische clustering wordt genoemd.
Divisieve hiërarchische clustering
Divisieve hiërarchische clustering werkt op de tegenovergestelde manier. In plaats van te beginnen met n clusters (in het geval van n waarnemingen), beginnen we met een enkele cluster en wijzen we alle punten aan die cluster toe.
Het maakt dus niet uit of we 10 of 1000 datapunten hebben. Al deze punten zullen in het begin tot dezelfde cluster behoren:
Nu splitsen we bij elke iteratie het verste punt in de cluster en herhalen dit proces totdat elke cluster nog maar één punt bevat:
We splitsen (of verdelen) de clusters bij elke stap, vandaar de naam divisive hierarchical clustering.
Agglomeratieve clustering wordt veel gebruikt in de industrie en dat zal in dit artikel centraal staan. Divisief hiërarchisch clusteren wordt een fluitje van een cent als we eenmaal het agglomeratieve type onder de knie hebben.
Stappen om hiërarchisch clusteren uit te voeren
Bij hiërarchisch clusteren voegen we de meest gelijkende punten of clusters samen – dat weten we. Nu is de vraag – hoe beslissen we welke punten gelijkaardig zijn en welke niet? Dat is een van de belangrijkste vragen bij het clusteren!
Hier is een manier om overeenkomst te berekenen – Neem de afstand tussen de centroïden van deze clusters. De punten met de kleinste afstand worden gelijksoortige punten genoemd en we kunnen ze samenvoegen. We kunnen dit ook een op afstand gebaseerd algoritme noemen (omdat we de afstanden tussen de clusters berekenen).
In hiërarchische clustering hebben we een concept dat een nabijheidsmatrix wordt genoemd. Hierin worden de afstanden tussen elk punt opgeslagen. Laten we een voorbeeld nemen om deze matrix te begrijpen, evenals de stappen om hiërarchisch clusteren uit te voeren.
Opzetten van het voorbeeld

Stel dat een lerares haar leerlingen in verschillende groepen wil verdelen. Zij beschikt over de cijfers die elke leerling voor een opdracht heeft behaald en op basis van deze cijfers wil zij de leerlingen in groepen indelen. Er is geen vast doel voor hoeveel groepen er moeten zijn. Aangezien de lerares niet weet welk type leerlingen in welke groep moet worden ingedeeld, kan dit niet worden opgelost als een probleem van gesuperviseerd leren. We zullen dus proberen hier hiërarchische clustering toe te passen en de leerlingen in verschillende groepen te verdelen.
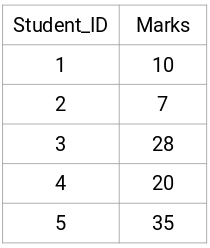
Laten we een steekproef van 5 leerlingen nemen:
Een nabijheidsmatrix maken
Eerst maken we een nabijheidsmatrix die ons de afstand tussen elk van deze punten vertelt. Omdat we de afstand van elk punt tot elk van de andere punten berekenen, krijgen we een vierkante matrix van de vorm n X n (waarbij n het aantal waarnemingen is).
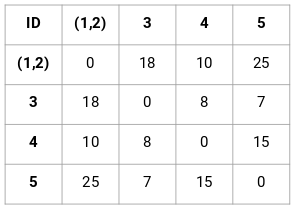
Laten we de 5 x 5 nabijheidsmatrix voor ons voorbeeld maken:
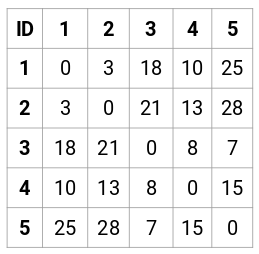
De diagonale elementen van deze matrix zullen altijd 0 zijn, omdat de afstand van een punt tot zichzelf altijd 0 is. We zullen de formule van de Euclidische afstand gebruiken om de rest van de afstanden te berekenen. Stel dat we de afstand tussen punt 1 en 2 willen berekenen:
√(10-7)^2 = √9 = 3
Op dezelfde manier kunnen we alle afstanden berekenen en de nabijheidsmatrix vullen.
Stappen om hiërarchische clustering uit te voeren
Stap 1: Eerst wijzen we alle punten aan een individuele cluster toe:
![]()
Verschillende kleuren staan hier voor verschillende clusters. U kunt zien dat we 5 verschillende clusters hebben voor de 5 punten in onze gegevens.
Stap 2: Vervolgens kijken we naar de kleinste afstand in de nabijheidsmatrix en voegen we de punten met de kleinste afstand samen. Vervolgens werken we de nabijheidsmatrix bij:
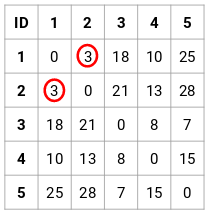
Hier is de kleinste afstand 3 en daarom voegen we punt 1 en 2 samen:
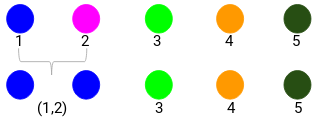
Laten we eens kijken naar de bijgewerkte clusters en dienovereenkomstig de nabijheidsmatrix bijwerken:
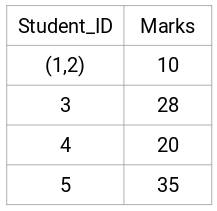
Hier hebben we het maximum van de twee punten (7, 10) genomen om de punten voor deze cluster te vervangen. In plaats van het maximum kunnen we ook de minimumwaarde of de gemiddelde waarden nemen. Nu berekenen we opnieuw de nabijheidsmatrix voor deze clusters:
Stap 3: We herhalen stap 2 totdat er nog maar één cluster over is.
Dus kijken we eerst naar de minimale afstand in de nabijheidsmatrix en voegen dan het dichtstbijzijnde paar clusters samen. Na herhaling van deze stappen krijgen we de samengevoegde clusters zoals hieronder afgebeeld:
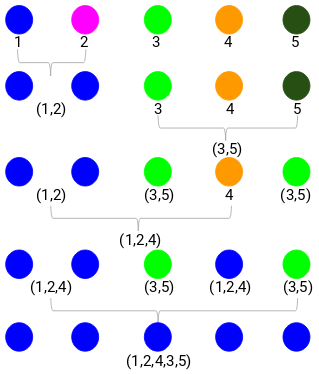
We begonnen met 5 clusters en hebben uiteindelijk één cluster. Dit is hoe agglomeratieve hiërarchische clustering werkt. Maar de brandende vraag blijft – hoe beslissen we over het aantal clusters? Laten we dat in de volgende sectie begrijpen.
Hoe kiezen we het aantal clusters bij hiërarchisch clusteren?
Klaar om eindelijk deze vraag te beantwoorden die al rondhangt sinds we met leren zijn begonnen? Om het aantal clusters voor hiërarchische clustering te bepalen, maken we gebruik van een geweldig concept dat een dendrogram wordt genoemd.
Een dendrogram is een boomvormig diagram dat de opeenvolging van samenvoegingen of splitsingen vastlegt.
Laten we teruggaan naar ons voorbeeld van leraar en leerling. Telkens wanneer we twee clusters samenvoegen, wordt in een dendrogram de afstand tussen deze clusters vastgelegd en in grafiekvorm weergegeven. Laten we eens kijken hoe een dendrogram eruit ziet:
We hebben de monsters van de dataset op de x-as en de afstand op de y-as. Wanneer twee clusters worden samengevoegd, voegen we ze samen in dit dendrogram en de hoogte van de samenvoeging is de afstand tussen deze punten. Laten we het dendrogram voor ons voorbeeld samenstellen:
Neem even de tijd om de bovenstaande afbeelding te verwerken. We zijn begonnen met monster 1 en 2 samen te voegen en de afstand tussen deze twee monsters was 3 (zie de eerste nabijheidsmatrix in de vorige sectie). Laten we dit plotten in het dendrogram:
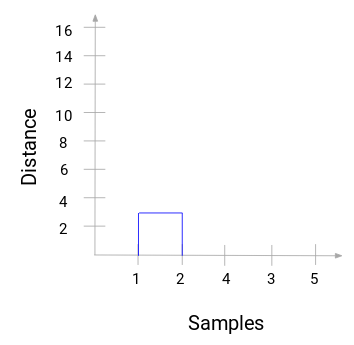
Hier kunnen we zien dat we monster 1 en 2 hebben samengevoegd. De verticale lijn geeft de afstand tussen deze monsters weer. Op dezelfde manier plotten we alle stappen waarin we de clusters hebben samengevoegd en uiteindelijk krijgen we een dendrogram als dit:
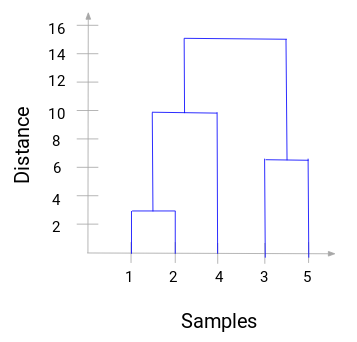
We kunnen de stappen van hiërarchische clustering duidelijk visualiseren. Hoe groter de afstand tussen de verticale lijnen in het dendrogram, hoe groter de afstand tussen die clusters.
Nu kunnen we een drempelafstand instellen en een horizontale lijn tekenen (In het algemeen proberen we de drempel zo in te stellen dat hij de hoogste verticale lijn snijdt). Stel deze drempelwaarde in op 12 en trek een horizontale lijn:
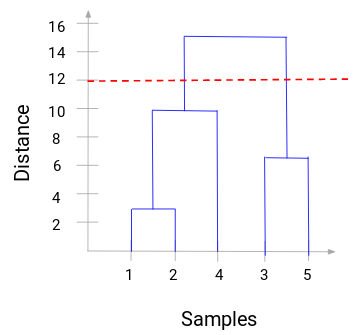
Het aantal clusters is het aantal verticale lijnen dat wordt doorsneden door de lijn die met behulp van de drempelwaarde is getrokken. Aangezien in bovenstaand voorbeeld de rode lijn 2 verticale lijnen snijdt, zullen we 2 clusters hebben. Eén cluster heeft een monster (1,2,4) en de andere heeft een monster (3,5). Nogal eenvoudig, toch?
Dit is hoe we het aantal clusters kunnen bepalen met behulp van een dendrogram in Hiërarchisch Clusteren. In de volgende sectie zullen we hiërarchische clustering implementeren, wat u zal helpen om alle concepten te begrijpen die we in dit artikel hebben geleerd.
Het oplossen van het Groothandel klantsegmentatie probleem met behulp van hiërarchische clustering
Tijd om onze handen vuil te maken in Python!
We zullen werken aan een groothandel klantsegmentatie probleem. U kunt de dataset downloaden via deze link. De data wordt gehost op de UCI Machine Learning repository. Het doel van dit probleem is om de klanten van een groothandelaar te segmenteren op basis van hun jaarlijkse uitgaven aan diverse productcategorieën, zoals melk, kruidenierswaren, regio, enz.
Laten we eerst de gegevens verkennen en vervolgens Hiërarchische Clustering toepassen om de klanten te segmenteren.
We zullen eerst de vereiste bibliotheken importeren:
Laad de gegevens en bekijk de eerste paar rijen:
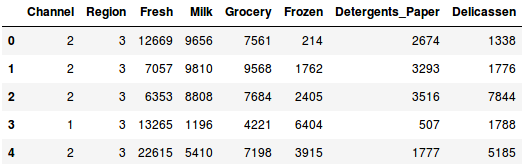
Er zijn meerdere productcategorieën – Vers, Melk, Kruidenier, enz. De waarden vertegenwoordigen het aantal eenheden dat door elke klant voor elk product is gekocht. Ons doel is om uit deze gegevens clusters te maken die soortgelijke klanten kunnen segmenteren. Voor dit probleem gebruiken we natuurlijk Hiërarchische Clustering.
Maar voordat we Hiërarchische Clustering toepassen, moeten we de gegevens normaliseren, zodat de schaal van elke variabele gelijk is. Waarom is dit belangrijk? Welnu, als de schaal van de variabelen niet dezelfde is, kan het model een vertekend beeld geven van de variabelen met een grotere magnitude, zoals Vers of Melk (zie de bovenstaande tabel).
Dus laten we eerst de gegevens normaliseren en alle variabelen op dezelfde schaal brengen:
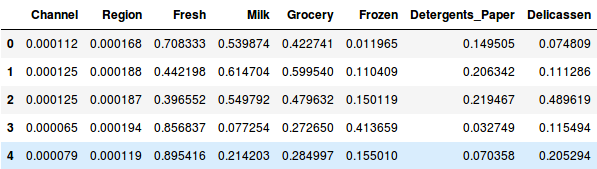
Hier kunnen we zien dat de schaal van alle variabelen bijna gelijk is. Nu zijn we klaar om te gaan. Laten we eerst het dendrogram tekenen om ons te helpen het aantal clusters voor dit specifieke probleem te bepalen:
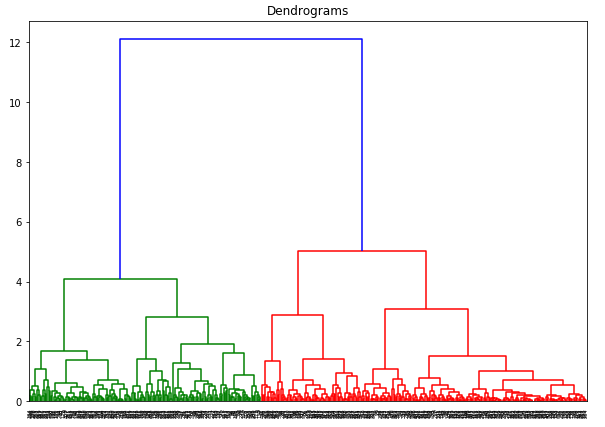
De x-as bevat de monsters en de y-as vertegenwoordigt de afstand tussen deze monsters. De verticale lijn met de maximale afstand is de blauwe lijn en daarom kunnen we een drempel van 6 kiezen en het dendrogram doorsnijden:
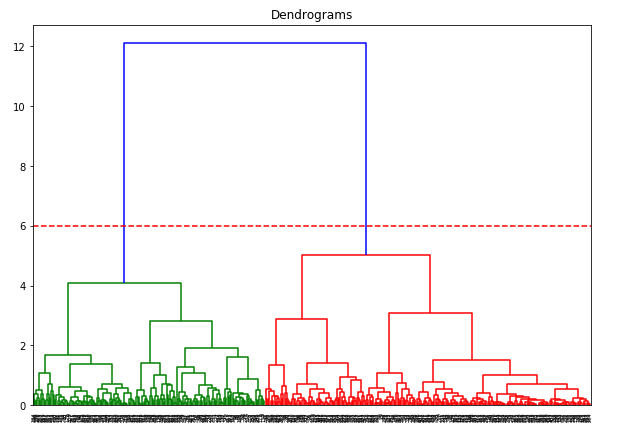
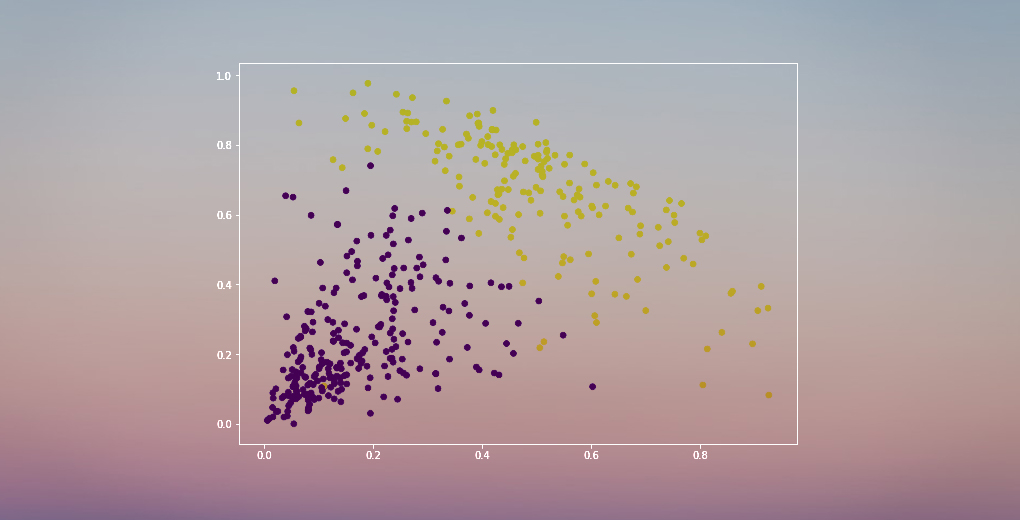
We hebben twee clusters aangezien deze lijn het dendrogram op twee punten doorsnijdt. Laten we nu hiërarchische clustering toepassen voor 2 clusters:
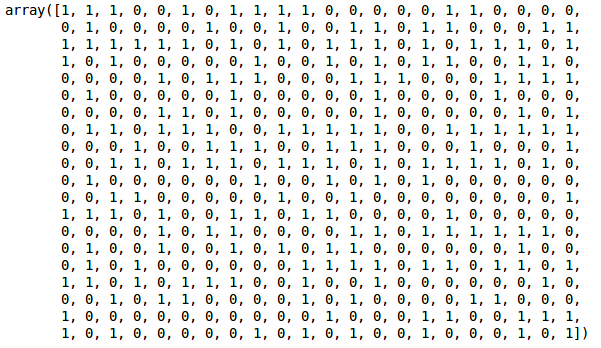
We kunnen de waarden van 0s en 1s in de uitvoer zien aangezien we 2 clusters hebben gedefinieerd. 0 vertegenwoordigt de punten die tot de eerste cluster behoren en 1 vertegenwoordigt de punten in de tweede cluster. Laten we nu de twee clusters visualiseren:
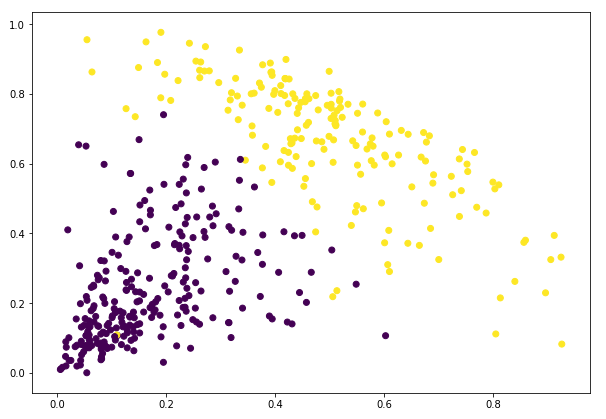
Geweldig! We kunnen de twee clusters hier duidelijk visualiseren. Dit is hoe we hiërarchisch clusteren in Python kunnen implementeren.
End Notes
Hiërarchisch clusteren is een super handige manier om waarnemingen te segmenteren. Het voordeel van het niet vooraf hoeven definiëren van het aantal clusters geeft het een behoorlijk voordeel ten opzichte van k-Means.
Als je nog relatief nieuw bent in data science, raad ik je sterk aan om de Applied Machine Learning cursus te volgen. Het is een van de meest uitgebreide cursussen over machinaal leren die je kunt vinden. Hiërarchische clustering is slechts een van de vele onderwerpen die we in de cursus behandelen.