Quantrium Guides

Tesseract is een engine voor optische tekenherkenning die op verschillende besturingssystemen kan worden gebruikt. Het is vrije software, vrijgegeven onder de Apache-licentie. Oorspronkelijk werd Tesseract in de jaren tachtig door Hewlett-Packard ontwikkeld als bedrijfseigen software, maar later, in 2005, werd het vrijgegeven als open source-software. Vanaf 2006 wordt de ontwikkeling ervan gesponsord door Google. In deze gids zal ik je meenemen door de stappen die ik heb gevolgd om Tesseract te installeren op mijn Windows 10 machine. Ik zal u ook laten zien hoe u tesseract kunt gebruiken vanaf de opdrachtregel zodra u het met succes hebt geïnstalleerd.
Om Tesseract 4 op ons Windows-systeem te installeren, gaat u naar de volgende link:
Download het uitvoerbare bestand voor Windows door op de hyperlink met de titel tesseract-ocr-w64-setup-v4.1.0.20190314.exe te klikken. Er verschijnt een melding waarin u wordt gevraagd een exe-bestand met de naam “Tesseract-ocr-w64-setup-v4.1.0.20190314.exe” op te slaan. Sla dit .exe bestand op waar u voldoende opslagruimte heeft.
Open dit exe bestand. Als het venster u vraagt “Wilt u toestaan dat deze software wijzigingen aanbrengt in uw systeem”, klikt u op ja. U wordt naar het installatiegedeelte gebracht.
Klik op volgende, klik op ik ga akkoord met de voorwaarden en na te hebben geselecteerd voor wie en wat u Tesseract wilt installeren (iedereen die deze computer gebruikt/alleen voor mij. U kunt een van beide selecteren), klik op volgende.
Vink de vakjes aan voor “ScrollView”, “Training Tools”, “Shortcuts creation” en belangrijk “Language data”. Deze zouden standaard aangevinkt moeten zijn, maar doe ze gewoon voor het geval ze in uw systeem niet zijn aangevinkt.
Nu, als u voorspellingen wilt doen in vreemde talen zoals Japans, Chinees, Koerdisch of Indiase talen zoals Hindi, Tamil, Bengali etc., vink dan ook de “aanvullende scriptgegevens” en “aanvullende taalgegevens” aan. Als u alleen voorspellingen wilt doen voor de Engelse taal, hoeft u deze optie niet aan te vinken.
Klik op Volgende. Selecteer de map waar u Tesseract wilt installeren. Standaard staat er C:\Program Files\Tesseract-OCR voor mij en dat is waar ik het geïnstalleerd heb. Je kunt het installeren zoals je wilt. Maar let wel op het pad waar je Tesseract op je machine hebt geïnstalleerd. Dit is belangrijk.
Nu kun je de map in het startmenu kiezen waarin je de snelkoppeling wilt maken. Ik heb hem gemaakt in een map genaamd “Tesseract-OCR”. Als je het in een nieuwe map wilt, typ dan de naam van de map in de lege ruimte rechts onder de tekst “Selecteer de Start Menu map waarin je …. wilt hebben”.
Je kunt ook het vakje “Maak geen snelkoppelingen” linksonder aanvinken als je geen snelkoppelingen wilt maken. Zodra u klaar bent met het selecteren van uw voorkeursoptie, klikt u op installeren. Het zou een paar minuten moeten duren voordat de installatie is voltooid.
Zodra de installatie is voltooid, gaat u naar de map waar u Tesseract hebt geïnstalleerd. We willen Tesseract vanaf onze Windows opdrachtregel gebruiken en om dat te doen, moeten we Tesseract toevoegen aan ons pad in de omgevingsvariabele van het systeem.
Om dat te doen, klik je op de startknop van Windows en zoek je op “omgevingsvariabele”. Je zult een resultaat zien met de naam “Bewerk de systeem omgevingsvariabelen”. Klik daarop. Nadat je hierop geklikt hebt, zou je in de “Geavanceerd” sectie van “Systeemeigenschappen” moeten zijn en een knop genaamd “Omgevingsvariabelen ….” zou zichtbaar moeten zijn aan de onderkant rechts. Klik op die knop.
Nu ziet u hier twee tabellen. Een met de naam User variables for <username>. Hier is de <username> een variabele die staat voor de gebruikersnaam die de PC momenteel gebruikt. De andere tabel heet “Systeemvariabelen”. Klik in de tabel “Systeemvariabelen” op de variabele “Pad” en klik vervolgens op de knop “Bewerken” recht boven de knop “OK”, zoals hieronder in de schermafbeelding te zien is.
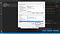
Als u hiermee klaar bent, ziet u een pagina met de naam “Omgevingsvariabele bewerken”. Rechtsboven ziet u een knop met de naam “Nieuw”. Klik op de knop “Nieuw”. Je krijgt een lege ruimte waar je wat tekst kunt toevoegen. Voeg hier uw mapnaam toe waar al uw Tesseract-OCR bestanden zijn opgeslagen.
Zodra u de mapnaam hebt ingevoerd, drukt u op “Enter” en controleert u of uw mapnaam is toegevoegd aan de tabel “omgevingsvariabele bewerken”. Zodra dat het geval is, klikt u op “OK”. Klik nogmaals op OK in de “Omgevingsvariabelen” pagina. Klik nogmaals op “OK” in de “Systeemeigenschappen” pagina. U moet nu alle opties voor de instellingen hebben verlaten.
Open command prompt en typ tesseract --version op de command prompt en druk op enter. U zult iets als dit te zien krijgen:
Als u een fout ziet zoals tesseract command not found, hebt u hoogstwaarschijnlijk een fout gemaakt tijdens het volgen van deze handleiding. Ga terug en kijk waar je fout bent gegaan en probeer het op te lossen. Als alternatief kunt u het hele proces opnieuw herhalen.
Geweldig! Nu heb je Tesseract op je machine geïnstalleerd. Je kunt ermee gaan spelen en het verder verkennen.
Hoe gebruik je Tesseract 4 met behulp van Command Line op een Windows Machine
Zorg er eerst voor dat je een handgeschreven document of een getypt document hebt in de vorm van een afbeelding. Laten we zeggen dat u een foto in png-vorm met de naam handwritten_photo_1 op uw Bureaublad hebt staan en dat u Tesseract daarmee wilt testen. Open uw opdrachtprompt. U start in deze directory:
C:\Users\username>
waar username uw gebruikersnaam is op dat systeem. Ik moet naar de desktop directory gaan. Dus gebruik ik het volgende commando:
C:\Users\username> cd Desktop
Nu ben ik in de Desktop directory, waar mijn image zich bevindt. Je kunt zien wat Tesseract voorspelt voor de tekst in het document met het volgende commando:
C:\Users\username\Desktop> tesseract handwritten_photo_1.png stdout -l eng
Tesseract zal de tekst direct in de opdrachtregel zelf uitvoeren. De parameter -l wordt gebruikt om de taal op te geven. Hier hebben we het als Engels opgegeven, wat standaard toch al het geval is, dus het gebruik van -l eng was in dit geval overbodig. Als u een andere taal voor OCR wilt gebruiken, controleer dan deze link hier, die alle .traineddata bestanden heeft, die de taal specificeren:
Stel u heeft een tekst document geschreven in Hindi. Ga dan naar deze bovenstaande link, klik op het bestand met de titel hin.traineddata en download het. Zodra je het hebt gedownload, moet je het verplaatsen naar de “tessdata” map, die zich in de map bevindt waar je tesseract oorspronkelijk had geïnstalleerd. Zodra u dat gedaan hebt, kunt u de OCR van Hindi documenten uitvoeren met het volgende commando:
C:\Users\username\Desktop> tesseract hindi_image.png stdout -l hin
In plaats van de OCR uitvoer op de commandoregel zelf weer te geven, stel dat u wilt dat uw OCR uitvoer in een tekstbestand wordt opgeslagen. In dat geval kunt u het volgende commando invoeren:
tesseract handwritten_photo_1.png output.txt
De tekst in handwritten_photo_1.png wordt opgeslagen in een tekstbestand met de naam output.txt dat zich in uw huidige werkdirectory bevindt, wat in mijn geval Desktop was.
Tesseract kan ook een tekstbestand als invoer nemen, waarbij de tekst alle absolute paden moet bevatten van de afbeeldingen die je wilt verwerken.
Dit is vooral handig wanneer je, laten we zeggen, twee handgeschreven afbeeldingen in het Engels hebt, genaamd handwritten_photo_1.png en handwritten_photo_2.png in de C:\Program Files directory. In uw huidige werkmap heeft u een tekstbestand met de naam input.txt waarvan de inhoud is:
C:\Program Files\handwritten_photo_1.png
C:\Program Files\handwritten_photo_2.png
In respectievelijk de eerste en tweede regel.
Wilt u nu de inhoud van deze twee handgeschreven foto’s in een tekstbestand opslaan, dan kunt u gewoon het volgende doen:
tesseract input.txt output.txt -l eng
output.txt zal de OCR-inhoud hebben van zowel handwritten_photo_1.png als handwritten_photo_2.png, in die volgorde. Hier moet je opmerken dat input.txt in de huidige werkdirectory stond. U kunt tesseract ook gebruiken op een tekstbestand dat niet in uw huidige werkdirectory staat, door de locatie van de directory op te nemen, zoals hier:
tesseract C:\Program Files\input.txt output.txt -l eng
output.txt zal zich weer in de huidige werkdirectory bevinden. U kunt dit ook voor meer dan twee foto’s doen. Merk op dat de voorspelling voor een nieuwe foto in het output.txt bestand zal worden voorafgegaan door een of ander symbool als:
Dus in dit geval is Viral Calic de voorspelling voor de eerste foto, CY am the king of the world de voorspelling voor de tweede foto, Com and Serr de voorspelling voor de derde foto enzovoorts. U kunt de uitvoer voor al uw ingevoerde beelden controleren en de nauwkeurigheid van de voorspellingen controleren.
Dat is het! Gefeliciteerd, u bent nu helemaal klaar om Tesseract op uw Windows 10-systeem te gebruiken.