Einführung
In jeder Branche ist es wichtig, das Kundenverhalten zu verstehen. Das wurde mir letztes Jahr klar, als mein Marketingleiter mich fragte: „Können Sie mir sagen, welche bestehenden Kunden wir für unser neues Produkt ansprechen sollten?“
Das war eine ziemliche Lernkurve für mich. Als Datenwissenschaftler wurde mir schnell klar, wie wichtig es ist, Kunden zu segmentieren, damit mein Unternehmen maßgeschneiderte und zielgerichtete Strategien entwickeln kann. Hier kam mir das Konzept des Clustering sehr gelegen!
Probleme wie die Segmentierung von Kunden sind oft trügerisch knifflig, weil wir nicht mit einer Zielvariablen im Kopf arbeiten. Wir befinden uns offiziell im Land des unüberwachten Lernens, wo wir Muster und Strukturen herausfinden müssen, ohne ein bestimmtes Ergebnis vor Augen zu haben. Als Datenwissenschaftler ist das sowohl eine Herausforderung als auch aufregend.
Nun gibt es ein paar verschiedene Möglichkeiten, Clustering durchzuführen (wie Sie weiter unten sehen werden). In diesem Artikel werde ich Ihnen eine davon vorstellen – das hierarchische Clustering.
Wir werden lernen, was hierarchisches Clustering ist, welche Vorteile es gegenüber anderen Clustering-Algorithmen hat, welche verschiedenen Arten von hierarchischem Clustering es gibt und wie man es durchführt. Schließlich werden wir uns einen Datensatz zur Kundensegmentierung vornehmen und dann hierarchisches Clustering in Python implementieren. Ich liebe diese Technik, und ich bin sicher, Sie werden es nach diesem Artikel auch tun!
Hinweis: Wie bereits erwähnt, gibt es mehrere Möglichkeiten, Clustering durchzuführen. Ich empfehle Ihnen, sich unseren großartigen Leitfaden zu den verschiedenen Arten von Clustering anzusehen:
- Einführung in das Clustering und verschiedene Methoden des Clustering
Um mehr über Clustering und andere Algorithmen des maschinellen Lernens (sowohl überwacht als auch unbeaufsichtigt) zu erfahren, sehen Sie sich das folgende umfassende Programm an.
- Certified AI & ML Blackbelt+ Programm
Inhaltsverzeichnis
- Überwachtes vs. unüberwachtes Lernen
- Warum Hierarchisches Clustering?
- Was ist hierarchisches Clustering?
- Typen des hierarchischen Clustering
- Agglomeratives hierarchisches Clustering
- Divisives hierarchisches Clustering
- Schritte zur Durchführung des hierarchischen Clustering
- Wie wählt man die Anzahl der Cluster beim hierarchischen Clustering?
- Lösung eines Kundensegmentierungsproblems im Großhandel mit hierarchischem Clustering
Überwachtes vs. unüberwachtes Lernen
Es ist wichtig, den Unterschied zwischen überwachtem und unüberwachtem Lernen zu verstehen, bevor wir uns mit hierarchischem Clustering beschäftigen. Lassen Sie mich diesen Unterschied anhand eines einfachen Beispiels erklären.
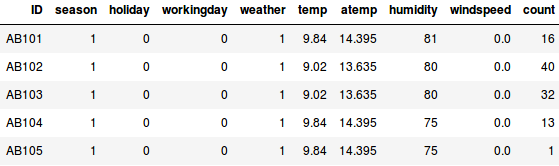
Angenommen, wir wollen die Anzahl der Fahrräder schätzen, die jeden Tag in einer Stadt ausgeliehen werden:
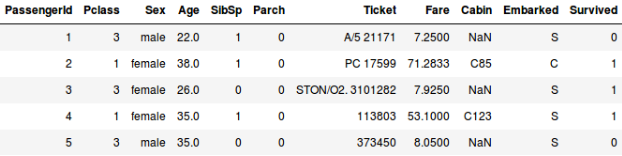
Oder nehmen wir an, wir wollen vorhersagen, ob eine Person an Bord der Titanic überlebt hat oder nicht:
In beiden Beispielen haben wir ein festes Ziel zu erreichen:
- Im ersten Beispiel müssen wir die Anzahl der Fahrräder anhand von Merkmalen wie Jahreszeit, Feiertag, Arbeitstag, Wetter, Temperatur usw. vorhersagen.
- Im zweiten Beispiel wird vorhergesagt, ob ein Fahrgast überlebt hat oder nicht. In der Variable „Überlebt“ bedeutet 0, dass die Person nicht überlebt hat, und 1, dass sie es lebend geschafft hat. Zu den unabhängigen Variablen gehören hier Pclass, Geschlecht, Alter, Fahrpreis usw.
Wenn wir also eine Zielvariable erhalten (Anzahl und Überleben in den beiden obigen Fällen), die wir auf der Grundlage eines gegebenen Satzes von Prädiktoren oder unabhängigen Variablen (Jahreszeit, Urlaub, Geschlecht, Alter usw.
Schauen wir uns die folgende Abbildung an, um dies visuell zu verstehen:
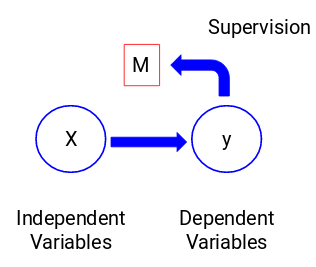
Hier ist y unsere abhängige oder Zielvariable, und X steht für die unabhängigen Variablen. Die Zielvariable ist von X abhängig und wird daher auch als abhängige Variable bezeichnet. Wir trainieren unser Modell, indem wir die unabhängigen Variablen zur Überwachung der Zielvariablen heranziehen, daher der Name überwachtes Lernen.
Unser Ziel beim Training des Modells ist es, eine Funktion zu erzeugen, die die unabhängigen Variablen auf das gewünschte Ziel abbildet. Sobald das Modell trainiert ist, können wir neue Sätze von Beobachtungen übergeben und das Modell wird das Ziel für sie vorhersagen. Dies ist, kurz gesagt, überwachtes Lernen.
Es kann Situationen geben, in denen wir keine Zielvariable zur Vorhersage haben. Solche Probleme, ohne explizite Zielvariable, werden als unüberwachte Lernprobleme bezeichnet. Bei diesen Problemen haben wir nur die unabhängigen Variablen und keine Zielvariable/abhängige Variable.

In diesen Fällen versuchen wir, die gesamten Daten in eine Reihe von Gruppen zu unterteilen. Diese Gruppen werden als Cluster bezeichnet, und der Prozess der Bildung dieser Cluster wird als Clustering bezeichnet.
Diese Technik wird im Allgemeinen zur Einteilung einer Population in verschiedene Gruppen verwendet. Einige gängige Beispiele sind die Segmentierung von Kunden, das Clustern ähnlicher Dokumente, die Empfehlung ähnlicher Lieder oder Filme usw.
Es gibt noch VIELE weitere Anwendungen des unüberwachten Lernens. Wenn Ihnen eine interessante Anwendung einfällt, können Sie sie gerne in den Kommentaren unten mitteilen!
Nun gibt es verschiedene Algorithmen, die uns helfen, diese Cluster zu erstellen. Die am häufigsten verwendeten Clustering-Algorithmen sind K-means und hierarchisches Clustering.
Warum hierarchisches Clustering?
Wir sollten zuerst wissen, wie K-means funktioniert, bevor wir uns mit hierarchischem Clustering beschäftigen. Glauben Sie mir, es wird das Konzept des hierarchischen Clustering um so einfacher machen.
Hier ist ein kurzer Überblick über die Funktionsweise von K-means:
- Bestimmen Sie die Anzahl der Cluster (k)
- Wählen Sie k zufällige Punkte aus den Daten als Zentroide
- Zuordnen Sie alle Punkte dem nächstgelegenen Clusterschwerpunkt zu
- Berechnen Sie den Schwerpunkt der neu gebildeten Cluster
- Wiederholen Sie die Schritte 3 und 4
Es handelt sich um einen iterativen Prozess. Er wird so lange durchgeführt, bis sich die Zentren der neu gebildeten Cluster nicht mehr ändern oder die maximale Anzahl der Iterationen erreicht ist.
Es gibt jedoch einige Probleme mit K-means. Es wird immer versucht, gleich große Cluster zu bilden. Außerdem müssen wir die Anzahl der Cluster zu Beginn des Algorithmus festlegen. Im Idealfall wissen wir zu Beginn des Algorithmus nicht, wie viele Cluster wir haben sollten, und das ist eine Herausforderung bei K-means.
Dies ist eine Lücke, die hierarchisches Clustering mit Bravour überbrückt. Es beseitigt das Problem, die Anzahl der Cluster vordefinieren zu müssen. Das klingt wie ein Traum! Sehen wir uns also an, was hierarchisches Clustering ist und wie es K-means verbessert.
Was ist hierarchisches Clustering?
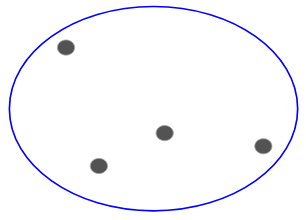
Angenommen, wir haben die folgenden Punkte und wollen sie in Gruppen zusammenfassen:

Wir können jeden dieser Punkte einem eigenen Cluster zuordnen:

Auf der Grundlage der Ähnlichkeit dieser Cluster können wir nun die ähnlichsten Cluster zusammenfassen und diesen Vorgang wiederholen, bis nur noch ein einziger Cluster übrig ist:
Wir bauen im Wesentlichen eine Hierarchie von Clustern auf. Deshalb wird dieser Algorithmus als hierarchisches Clustering bezeichnet. Wie man die Anzahl der Cluster bestimmt, werde ich in einem späteren Abschnitt erläutern. Betrachten wir zunächst die verschiedenen Arten des hierarchischen Clustering.
Typen des hierarchischen Clustering
Es gibt hauptsächlich zwei Arten des hierarchischen Clustering:
- Agglomeratives hierarchisches Clustering
- Divisives hierarchisches Clustering
Lassen Sie uns jeden Typ im Detail verstehen.
Agglomeratives Hierarchisches Clustering
Bei dieser Technik ordnen wir jeden Punkt einem einzelnen Cluster zu. Angenommen, es gibt 4 Datenpunkte. Wir ordnen jeden dieser Punkte einem Cluster zu und haben somit zu Beginn 4 Cluster:
Dann fügen wir bei jeder Iteration das nächstgelegene Paar von Clustern zusammen und wiederholen diesen Schritt, bis nur noch ein einziger Cluster übrig ist:
Wir fusionieren (oder fügen hinzu) die Cluster bei jedem Schritt, richtig? Daher wird diese Art des Clustering auch als additives hierarchisches Clustering bezeichnet.
Divisives hierarchisches Clustering
Divisives hierarchisches Clustering funktioniert auf die entgegengesetzte Weise. Anstatt mit n Clustern zu beginnen (bei n Beobachtungen), beginnen wir mit einem einzigen Cluster und ordnen alle Punkte diesem Cluster zu.
Es spielt also keine Rolle, ob wir 10 oder 1000 Datenpunkte haben. Alle diese Punkte gehören zu Beginn zum selben Cluster:
Nun teilen wir bei jeder Iteration den am weitesten entfernten Punkt im Cluster auf und wiederholen diesen Vorgang, bis jeder Cluster nur noch einen einzigen Punkt enthält:
Wir teilen (oder dividieren) die Cluster bei jedem Schritt auf, daher der Name divisive hierarchische Clusterung.
Agglomeratives Clustering ist in der Industrie weit verbreitet und wird in diesem Artikel im Mittelpunkt stehen. Divisives hierarchisches Clustering ist ein Kinderspiel, sobald wir den agglomerativen Typ beherrschen.
Schritte zur Durchführung von hierarchischem Clustering
Wir fügen die ähnlichsten Punkte oder Cluster beim hierarchischen Clustering zusammen – das wissen wir. Die Frage ist nun: Wie entscheiden wir, welche Punkte ähnlich sind und welche nicht? Das ist eine der wichtigsten Fragen beim Clustering!
Eine Möglichkeit, die Ähnlichkeit zu berechnen, ist der Abstand zwischen den Zentren dieser Cluster. Die Punkte, die den geringsten Abstand haben, werden als ähnliche Punkte bezeichnet, und wir können sie zusammenführen. Wir können dies auch als einen distanzbasierten Algorithmus bezeichnen (da wir die Abstände zwischen den Clustern berechnen).
Beim hierarchischen Clustering gibt es ein Konzept, das als Proximity-Matrix bezeichnet wird. Diese speichert die Abstände zwischen den einzelnen Punkten. Nehmen wir ein Beispiel, um diese Matrix sowie die Schritte zur Durchführung des hierarchischen Clustering zu verstehen.
Beispiel einrichten

Angenommen, eine Lehrerin möchte ihre Schüler in verschiedene Gruppen einteilen. Sie hat die Noten, die jeder Schüler in einer Aufgabe erzielt hat, und möchte sie auf der Grundlage dieser Noten in Gruppen einteilen. Hier gibt es keine feste Vorgabe, wie viele Gruppen gebildet werden sollen. Da die Lehrkraft nicht weiß, welche Art von Schülern welcher Gruppe zuzuordnen ist, kann dieses Problem nicht als Problem des überwachten Lernens gelöst werden. Wir werden also versuchen, hierarchisches Clustering anzuwenden und die Schüler in verschiedene Gruppen einzuteilen.
Wir nehmen eine Stichprobe von 5 Schülern:
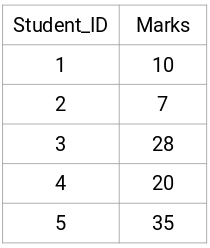
Erstellen einer Proximity-Matrix
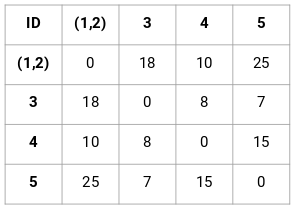
Zunächst erstellen wir eine Proximity-Matrix, die uns den Abstand zwischen jedem dieser Punkte angibt. Da wir die Entfernung jedes Punktes von jedem anderen Punkt berechnen, erhalten wir eine quadratische Matrix der Form n x n (wobei n die Anzahl der Beobachtungen ist).
Lassen Sie uns die 5 x 5 Näherungsmatrix für unser Beispiel erstellen:
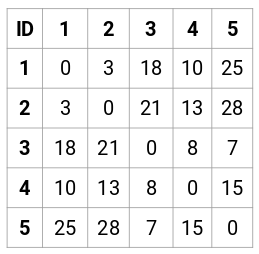
Die Diagonalelemente dieser Matrix werden immer 0 sein, da die Entfernung eines Punktes zu sich selbst immer 0 ist. Wir werden die euklidische Abstandsformel verwenden, um die restlichen Abstände zu berechnen. Nehmen wir also an, wir wollen den Abstand zwischen Punkt 1 und 2 berechnen:
√(10-7)^2 = √9 = 3
Auf ähnliche Weise können wir alle Abstände berechnen und die Proximity-Matrix füllen.
Schritte zur Durchführung des hierarchischen Clustering
Schritt 1: Zuerst ordnen wir alle Punkte einem einzelnen Cluster zu:
![]()
Die verschiedenen Farben stehen hier für verschiedene Cluster. Sie können sehen, dass wir 5 verschiedene Cluster für die 5 Punkte in unseren Daten haben.
Schritt 2: Als nächstes schauen wir uns den kleinsten Abstand in der Proximity-Matrix an und fügen die Punkte mit dem kleinsten Abstand zusammen. Dann aktualisieren wir die Proximity-Matrix:
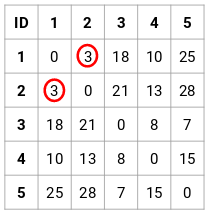
Hier ist der kleinste Abstand 3 und daher werden wir die Punkte 1 und 2 zusammenführen:
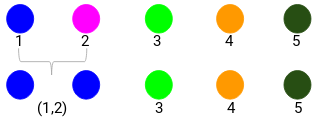
Schauen wir uns die aktualisierten Cluster an und aktualisieren die Proximity-Matrix entsprechend:
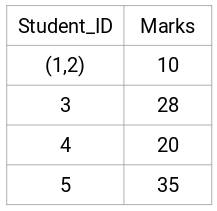
Hier haben wir das Maximum der beiden Marken (7, 10) genommen, um die Marken für diesen Cluster zu ersetzen. Anstelle des Maximums können wir auch den Minimalwert oder den Mittelwert nehmen. Nun berechnen wir erneut die Proximity-Matrix für diese Cluster:
Schritt 3: Wir wiederholen Schritt 2, bis nur noch ein einziger Cluster übrig ist.
So schauen wir uns zunächst den minimalen Abstand in der Proximity-Matrix an und fusionieren dann das nächstgelegene Paar von Clustern. Nach Wiederholung dieser Schritte erhalten wir die unten abgebildeten Cluster:
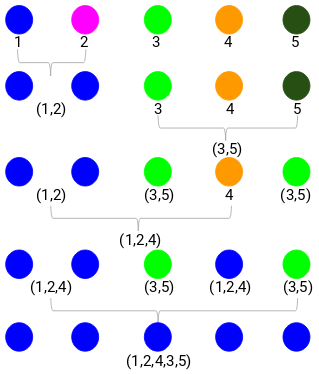
Wir begannen mit 5 Clustern und haben schließlich einen einzigen Cluster. So funktioniert das agglomerative hierarchische Clustering. Aber die brennende Frage bleibt – wie entscheiden wir die Anzahl der Cluster? Das wollen wir im nächsten Abschnitt klären.
Wie wählt man die Anzahl der Cluster beim hierarchischen Clustering?
Sind Sie bereit, endlich diese Frage zu beantworten, die sich seit Beginn des Lernens stellt? Um die Anzahl der Cluster beim hierarchischen Clustering zu ermitteln, verwenden wir ein geniales Konzept namens Dendrogramm.
Ein Dendrogramm ist ein baumartiges Diagramm, das die Abfolge von Verschmelzungen oder Aufteilungen aufzeichnet.
Lassen Sie uns auf unser Lehrer-Schüler-Beispiel zurückkommen. Immer wenn wir zwei Cluster zusammenführen, wird ein Dendrogramm den Abstand zwischen diesen Clustern aufzeichnen und in Form eines Graphen darstellen. Sehen wir uns an, wie ein Dendrogramm aussieht:
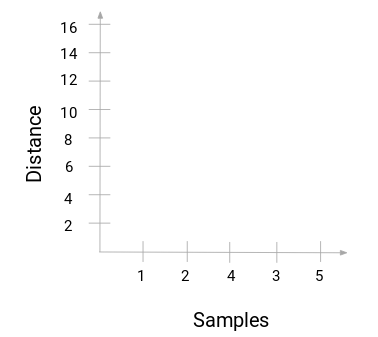
Auf der x-Achse befinden sich die Stichproben des Datensatzes und auf der y-Achse der Abstand. Wenn zwei Cluster zusammengeführt werden, verbinden wir sie in diesem Dendrogramm, und die Höhe der Verbindung entspricht dem Abstand zwischen diesen Punkten. Erstellen wir nun das Dendrogramm für unser Beispiel:
Nehmen Sie sich einen Moment Zeit, um das obige Bild zu bearbeiten. Wir begannen mit der Zusammenführung von Probe 1 und 2, und der Abstand zwischen diesen beiden Proben betrug 3 (siehe die erste Proximity-Matrix im vorherigen Abschnitt). Stellen wir dies im Dendrogramm dar:
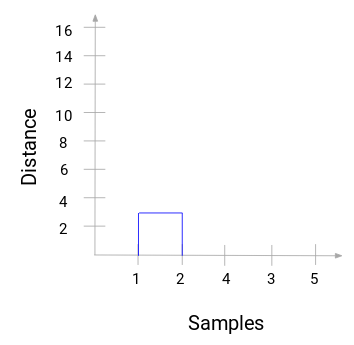
Hier können wir sehen, dass wir Probe 1 und 2 zusammengeführt haben. Die vertikale Linie stellt den Abstand zwischen diesen Proben dar. In ähnlicher Weise stellen wir alle Schritte dar, in denen wir die Cluster zusammengeführt haben, und schließlich erhalten wir ein Dendrogramm wie dieses:
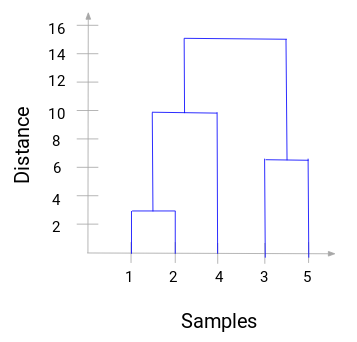
Wir können die Schritte der hierarchischen Clusterbildung deutlich visualisieren. Je größer der Abstand der vertikalen Linien im Dendrogramm, desto größer der Abstand zwischen diesen Clustern.
Nun können wir einen Schwellenwert für den Abstand festlegen und eine horizontale Linie zeichnen (im Allgemeinen versuchen wir, den Schwellenwert so festzulegen, dass er die höchste vertikale Linie schneidet). Setzen wir diesen Schwellenwert auf 12 und zeichnen wir eine horizontale Linie:
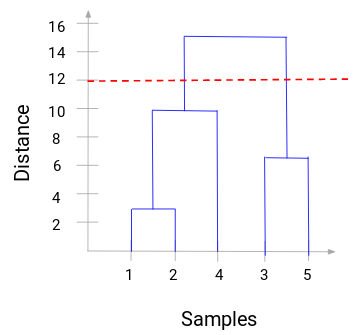
Die Anzahl der Cluster entspricht der Anzahl der vertikalen Linien, die von der mit dem Schwellenwert gezeichneten Linie geschnitten werden. Da im obigen Beispiel die rote Linie 2 vertikale Linien schneidet, ergeben sich 2 Cluster. Ein Cluster wird eine Stichprobe (1,2,4) und der andere eine Stichprobe (3,5) haben. Ziemlich einfach, nicht wahr?
So können wir die Anzahl der Cluster mithilfe eines Dendrogramms im Hierarchischen Clustering bestimmen. Im nächsten Abschnitt werden wir hierarchisches Clustering implementieren, was Ihnen helfen wird, alle Konzepte zu verstehen, die wir in diesem Artikel gelernt haben.
Lösen des Problems der Großhandelskunden-Segmentierung mit hierarchischem Clustering
Zeit, sich in Python die Hände schmutzig zu machen!
Wir werden an einem Problem der Großhandelskunden-Segmentierung arbeiten. Sie können den Datensatz über diesen Link herunterladen. Die Daten werden auf dem UCI Machine Learning Repository gehostet. Das Ziel dieses Problems ist es, die Kunden eines Großhändlers auf der Grundlage ihrer jährlichen Ausgaben für verschiedene Produktkategorien wie Milch, Lebensmittel, Region usw. zu segmentieren.
Lassen Sie uns zunächst die Daten untersuchen und dann Hierarchisches Clustering anwenden, um die Kunden zu segmentieren.
Wir importieren zunächst die erforderlichen Bibliotheken:
Laden Sie die Daten und sehen Sie sich die ersten Zeilen an:
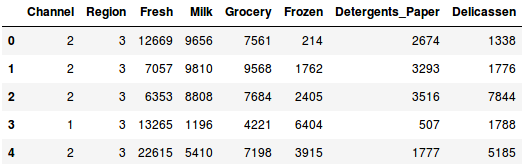
Es gibt mehrere Produktkategorien – Frisch, Milch, Lebensmittel usw. Die Werte geben die Anzahl der von jedem Kunden gekauften Einheiten für jedes Produkt an. Unser Ziel ist es, aus diesen Daten Cluster zu bilden, die ähnliche Kunden zusammenfassen können. Für dieses Problem werden wir natürlich das Hierarchische Clustering verwenden.
Aber bevor wir das Hierarchische Clustering anwenden, müssen wir die Daten normalisieren, damit die Skala jeder Variablen gleich ist. Warum ist das wichtig? Nun, wenn die Skala der Variablen nicht dieselbe ist, könnte das Modell in Richtung der Variablen mit einer höheren Größenordnung wie Frisch oder Milch verzerrt werden (siehe die obige Tabelle).
So, lassen Sie uns zuerst die Daten normalisieren und alle Variablen auf dieselbe Skala bringen:
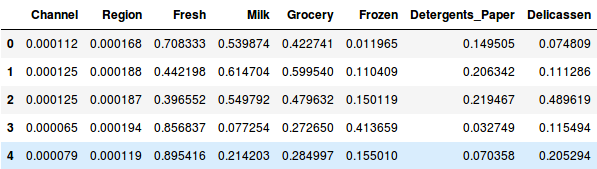
Hier können wir sehen, dass die Skala aller Variablen fast ähnlich ist. Jetzt sind wir startklar. Zeichnen wir zunächst das Dendrogramm, um uns bei der Entscheidung über die Anzahl der Cluster für dieses spezielle Problem zu helfen:
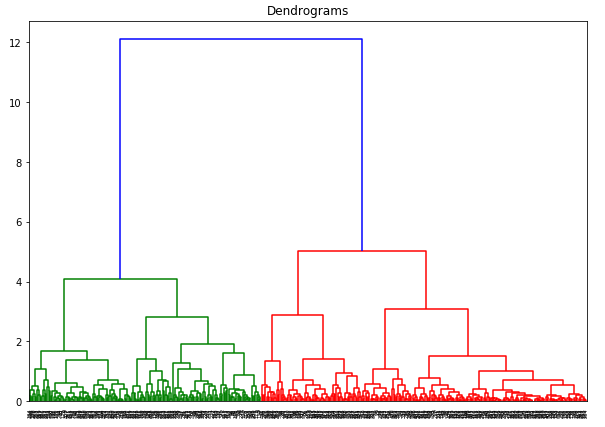
Die x-Achse enthält die Stichproben und die y-Achse stellt den Abstand zwischen diesen Stichproben dar. Die vertikale Linie mit dem maximalen Abstand ist die blaue Linie. Wir können daher einen Schwellenwert von 6 festlegen und das Dendrogramm schneiden:
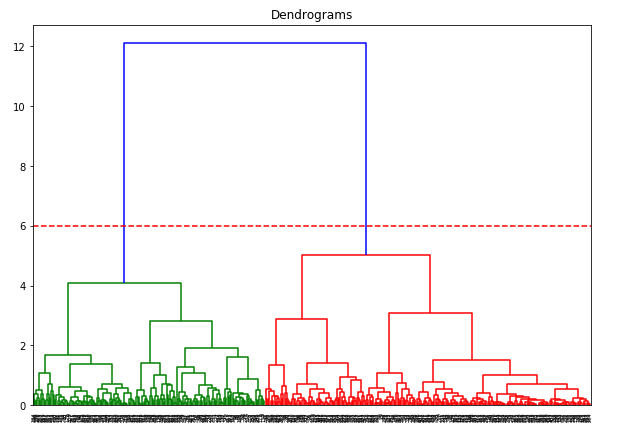
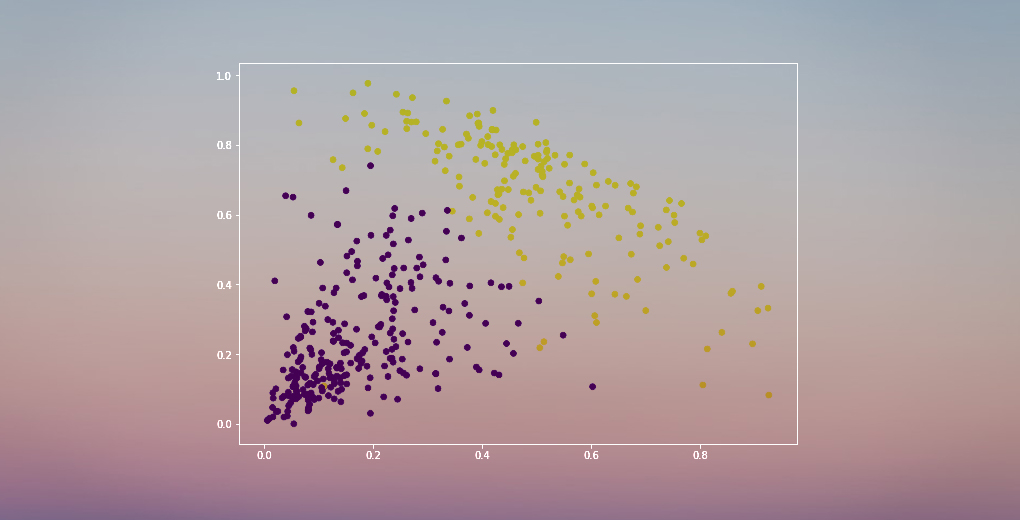
Wir haben zwei Cluster, da diese Linie das Dendrogramm an zwei Punkten schneidet. Wenden wir nun das hierarchische Clustering für 2 Cluster an:
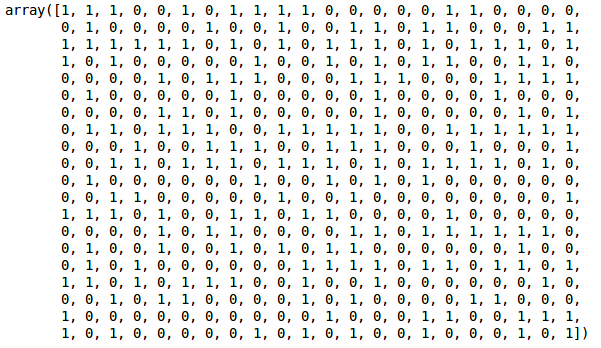
Wir können die Werte von 0 und 1 in der Ausgabe sehen, da wir 2 Cluster definiert haben. 0 steht für die Punkte, die zum ersten Cluster gehören, und 1 für die Punkte im zweiten Cluster. Lassen Sie uns nun die beiden Cluster visualisieren:
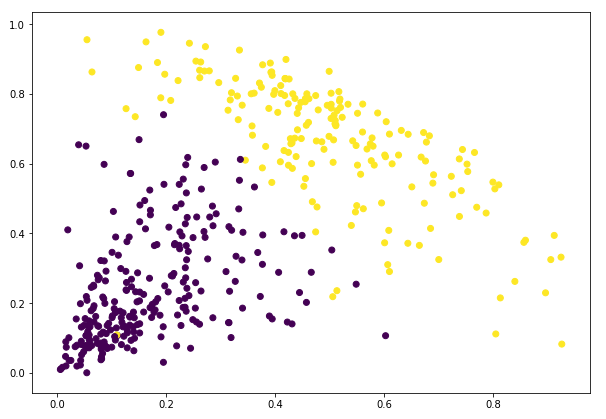
Gut! Wir können die beiden Cluster hier deutlich visualisieren. So können wir hierarchisches Clustering in Python implementieren.
Anmerkungen zum Schluss
Hierarchisches Clustering ist eine sehr nützliche Methode, um Beobachtungen zu segmentieren. Der Vorteil, dass man die Anzahl der Cluster nicht vordefinieren muss, ist ein großer Vorteil gegenüber k-Means.
Wenn Sie noch relativ neu in der Datenwissenschaft sind, empfehle ich Ihnen den Kurs „Angewandtes Maschinelles Lernen“. Er ist einer der umfassendsten Kurse zum maschinellen Lernen, die Sie irgendwo finden können. Hierarchisches Clustering ist nur eines der vielen Themen, die wir in diesem Kurs behandeln.